本文主要是介绍Java如何使用KEPserver 实现S71500 OPC通信,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.PLC和OPC
使用的PLC:西门子PLC S7-1500
使用的OPC server软件:
KEPServer V6
二.连接测试
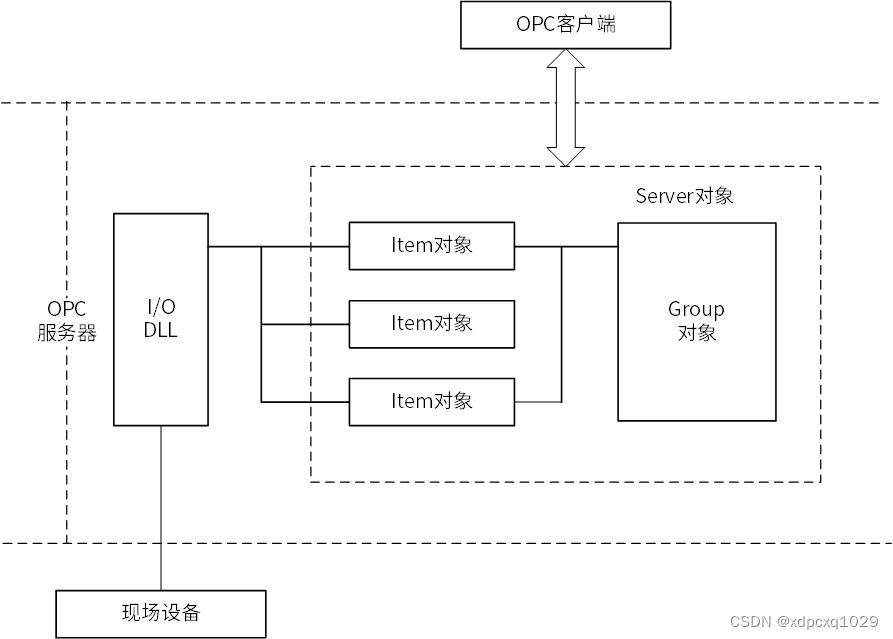
OPC是工业控制和生产自动化领域中使用的硬件和软件的接口标准,以便有效地在应用和过程控制设备之间读写数据。O代表OLE(对象链接和嵌入),P (process过程),C (control控制)。
OPC服务器包括3类对象(Object):服务器对象(Server)、项对象(Item)和组对象(Group)。
OPC标准采用C/S模式,OPC服务器负责向OPC客户端不断的提供数据。
maven依赖
<!--utgard --><dependency><groupId>org.openscada.external</groupId><artifactId>org.openscada.external.jcifs</artifactId><version>1.2.25</version></dependency><dependency><groupId>org.openscada.jinterop</groupId><artifactId>org.openscada.jinterop.core</artifactId><version>2.1.8</version></dependency><dependency><groupId>org.openscada.jinterop</groupId><artifactId>org.openscada.jinterop.deps</artifactId><version>1.5.0</version></dependency><dependency><groupId>org.openscada.utgard</groupId><artifactId>org.openscada.opc.dcom</artifactId><version>1.5.0</version></dependency><dependency><groupId>org.openscada.utgard</groupId><artifactId>org.openscada.opc.lib</artifactId><version>1.5.0</version></dependency><dependency><groupId>org.bouncycastle</groupId><artifactId>bcprov-jdk15on</artifactId><version>1.61</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-core</artifactId><version>1.3.0-alpha4</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.3.0-alpha4</version><scope>test</scope></dependency>读取PLC 的点位值
import java.util.concurrent.Executors;
import org.jinterop.dcom.common.JIException;
import org.jinterop.dcom.core.JIString;
import org.jinterop.dcom.core.JIVariant;
import org.openscada.opc.lib.common.ConnectionInformation;
import org.openscada.opc.lib.da.AccessBase;
import org.openscada.opc.lib.da.DataCallback;
import org.openscada.opc.lib.da.Item;
import org.openscada.opc.lib.da.ItemState;
import org.openscada.opc.lib.da.Server;
import org.openscada.opc.lib.da.SyncAccess;
public class UtgardTutorial1 {
public static void main(String[] args) throws Exception {
// 连接信息
final ConnectionInformation ci = new ConnectionInformation();
ci.setHost("192.168.0.1"); // 电脑IP
ci.setDomain(""); // 域,为空就行
ci.setUser("OPCUser"); // 电脑上自己建好的用户名 (之前DCOM 配置过)
ci.setPassword("123456"); // 密码(用户名密码)
// 使用MatrikonOPC Server的配置
// ci.setClsid("F8582CF2-88FB-11D0-B850-00C0F0104305"); // MatrikonOPC的注册表ID,可以在“组件服务”里看到
// final String itemId = "u.u"; // MatrikonOPC Server上配置的项的名字按实际
// 使用KEPServer的配置
ci.setClsid("7BC0CC8E-482C-47CA-ABDC-0FE7F9C6E729"); // KEPServer的注册表ID,可以在“组件服务”里看到
final String itemId = "u.u.u"; // KEPServer上配置的项的名字,没有实际PLC,用的模拟器:simulator (KEPserver 建立通道,建立设备,建立点位)通过标记点位名字定位要读取的值
// final String itemId = "通道 1.设备 1.标记 1";
// 启动服务
final Server server = new Server(ci, Executors.newSingleThreadScheduledExecutor());
try {
// 连接到服务
server.connect();
// add sync access, poll every 500 ms,启动一个同步的access用来读取地址上的值,线程池每500ms读值一次
// 这个是用来循环读值的,只读一次值不用这样
final AccessBase access = new SyncAccess(server, 500);
// 这是个回调函数,就是读到值后执行这个打印,是用匿名类写的,当然也可以写到外面去
access.addItem(itemId, new DataCallback() {
@Override
public void changed(Item item, ItemState itemState) {
int type = 0;
try {
type = itemState.getValue().getType(); // 类型实际是数字,用常量定义的
} catch (JIException e) {
e.printStackTrace();
}
System.out.println("监控项的数据类型是:-----" + type);
System.out.println("监控项的时间戳是:-----" + itemState.getTimestamp().getTime());
System.out.println("监控项的详细信息是:-----" + itemState);
// 如果读到是short类型的值
if (type == JIVariant.VT_I2) {
short n = 0;
try {
n = itemState.getValue().getObjectAsShort();
} catch (JIException e) {
e.printStackTrace();
}
System.out.println("-----short类型值: " + n);
}
// 如果读到是字符串类型的值
if(type == JIVariant.VT_BSTR) { // 字符串的类型是8
JIString value = null;
try {
value = itemState.getValue().getObjectAsString();
} catch (JIException e) {
e.printStackTrace();
} // 按字符串读取
String str = value.getString(); // 得到字符串
System.out.println("-----String类型值: " + str);
}
}
});
// start reading,开始读值
access.bind();
// wait a little bit,有个10秒延时
Thread.sleep(10 * 1000);
// stop reading,停止读取
access.unbind();
} catch (final JIException e) {
System.out.println(String.format("%08X: %s", e.getErrorCode(), server.getErrorMessage(e.getErrorCode())));
}
}
}
读取数值与写入数值
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;import org.jinterop.dcom.common.JIException;
import org.jinterop.dcom.core.JIVariant;
import org.openscada.opc.lib.common.ConnectionInformation;
import org.openscada.opc.lib.da.AccessBase;
import org.openscada.opc.lib.da.DataCallback;
import org.openscada.opc.lib.da.Group;
import org.openscada.opc.lib.da.Item;
import org.openscada.opc.lib.da.ItemState;
import org.openscada.opc.lib.da.Server;
import org.openscada.opc.lib.da.SyncAccess;public class UtgardTutorial2 {public static void main(String[] args) throws Exception {// 连接信息 final ConnectionInformation ci = new ConnectionInformation();ci.setHost("192.168.0.1"); // 电脑IPci.setDomain(""); // 域,为空就行ci.setUser("OPCUser"); // 用户名,配置DCOM时配置的ci.setPassword("123456"); // 密码// 使用MatrikonOPC Server的配置// ci.setClsid("F8582CF2-88FB-11D0-B850-00C0F0104305"); // MatrikonOPC的注册表ID,可以在“组件服务”里看到// final String itemId = "u.u"; // 项的名字按实际// 使用KEPServer的配置ci.setClsid("7BC0CC8E-482C-47CA-ABDC-0FE7F9C6E729"); // KEPServer的注册表ID,可以在“组件服务”里看到final String itemId = "u.u.u"; // 项的名字按实际,没有实际PLC,用的模拟器:simulator// final String itemId = "通道 1.设备 1.标记 1";// create a new server,启动服务final Server server = new Server(ci, Executors.newSingleThreadScheduledExecutor());try {// connect to server,连接到服务server.connect();// add sync access, poll every 500 ms,启动一个同步的access用来读取地址上的值,线程池每500ms读值一次// 这个是用来循环读值的,只读一次值不用这样final AccessBase access = new SyncAccess(server, 500);// 这是个回调函数,就是读到值后执行再执行下面的代码,是用匿名类写的,当然也可以写到外面去access.addItem(itemId, new DataCallback() {@Overridepublic void changed(Item item, ItemState state) {// also dump valuetry {if (state.getValue().getType() == JIVariant.VT_UI4) { // 如果读到的值类型时UnsignedInteger,即无符号整形数值System.out.println("<<< " + state + " / value = " + state.getValue().getObjectAsUnsigned().getValue());} else {System.out.println("<<< " + state + " / value = " + state.getValue().getObject());}} catch (JIException e) {e.printStackTrace();}}});// Add a new group,添加一个组,这个用来就读值或者写值一次,而不是循环读取或者写入// 组的名字随意,给组起名字是因为,server可以addGroup也可以removeGroup,读一次值,就先添加组,然后移除组,再读一次就再添加然后删除final Group group = server.addGroup("test"); // Add a new item to the group,// 将一个item加入到组,item名字就是MatrikonOPC Server或者KEPServer上面建的项的名字比如:u.u.TAG1,PLC.S7-300.TAG1final Item item = group.addItem(itemId);// start reading,开始循环读值access.bind();// add a thread for writing a value every 3 seconds// 写入一次就是item.write(value),循环写入就起个线程一直执行item.write(value)ScheduledExecutorService writeThread = Executors.newSingleThreadScheduledExecutor();writeThread.scheduleWithFixedDelay(new Runnable() {@Overridepublic void run() {final JIVariant value = new JIVariant("24"); // 写入24try {System.out.println(">>> " + "写入值: " + "24");item.write(value);} catch (JIException e) {e.printStackTrace();}}}, 5, 3, TimeUnit.SECONDS); // 启动后5秒第一次执行代码,以后每3秒执行一次代码// wait a little bit ,延时20秒Thread.sleep(20 * 1000);writeThread.shutdownNow(); // 关掉一直写入的线程// stop reading,停止循环读取数值access.unbind();} catch (final JIException e) {System.out.println(String.format("%08X: %s", e.getErrorCode(), server.getErrorMessage(e.getErrorCode())));}}
}这篇关于Java如何使用KEPserver 实现S71500 OPC通信的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




