本文主要是介绍Vigenere密码的唯密文攻击暴力破解(python实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、找到最可能的密钥长度
在不知道密钥的情况下破解,首先要猜测密钥长度,这是非常重要的一个环节。
书上写的是kasiski测试法和重合指数法
这里使用到的不是课本上的,而是代码实现中用到的一种方法:移位法(暂且称之为移位法)
原理:
我们都知道vigenere密码是多表循环加密实现的,在这里假设密钥长度是d,那么第1,1+d,....,1+k*d都是同一个密钥字母加密的,那么如果第i和第i+d*n个字母相同的话,他们的密文一定是一样的。
所以我们可以利用这个事实,来进行概率推测,我们假设密钥长度是3~15,我们从密钥长度为3开始测试:
从第0个字符开始,对每个字符(i)判断,如果该字符与相隔密钥长度(我们猜想的)的字符(i+3)一样,那么我们可以认为,这两个字符在一定程度上明文也是匹配的,可以把这个匹配个数记下来,进行累加。(这里不用计算重合指数,代码实现起来比较快,正确率也是很高的)
重复测试直到密钥长度15,每次都会计算出一个匹配最大值,我们取最后的匹配量最大的密钥长度,很有可能是我们的密钥长度。
下面给出图示,来清晰下这个过程:


下面给出代码实现:
def getKeyLen(cipherText): # 获取密钥长度keylength = 1maxCount = 0for step in range(3,10): # 循环密钥长度count = 0for i in range(len(cipherText)-step): #range(step,len(cipherText)-step):if cipherText[i] == cipherText[i+step]:count += 1if count>maxCount:maxCount = countkeylength = stepreturn keylength二、找到最可能的匹配密钥
寻找密钥是使用的是交互重合指数法
在得到密钥长度之后,就要实现对密钥字母的匹配了。
我们知道密钥长度(k)之后,那么将密文分成n个组(每组包含k个字符),那么每个分组中的第i个字符,都是使用同一个密钥字母进行加密的,那么现在所有分组第i个字符就是一个单表加密的实现,故,他的每组中字母频率,只是明文字母频率的一个转换(shift)。

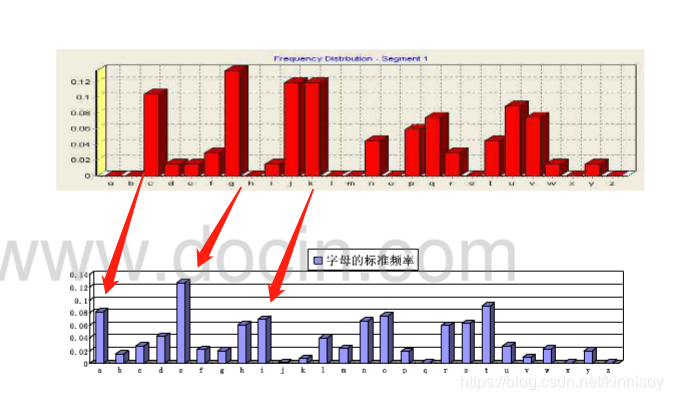
字母频率也会是这样的一个转换,但是我们实际上是不可能得到明文的频率分布的,(不然还破解个?2?)
这里只是清晰下思路。
现在我们可以来计算明文和所有分组用同一密钥字母加密的密文的交互重合指数(两个都随机取一个字母相同的概率)
注:l为密文与明文的相对位移
这个式子表示一段文本中第i个字符和另一段文本中第j个字符同为26个字母中第h个字母的概率,由于26个字母的概率我们是知道的,也就是,式子就变成了: [已知的字母概率] * [密文字母概率](也就是相对位移l后的字母概率)
很显然,我们的密文字母概率是可以统计出来的。
如果我们此时我们存在相对位移的话,也就是说没有找对正确的密钥字母时,这时候交互重合指数的数值是在[0.031,0.045]之间浮动的;当不存在相对位移时,也就是说相对位移为0时,这时候这个数值会比较接近0.065.
但是这个0.065是在大量大量大量英文中找到的一个普遍水平,我们随便找的文本,可以说是不可能达到0.065的水平。
所以我们只需要取最接近0.065的那个相对位移值(0~25),其对应的字母就是我们的密钥第一个字母。
其他密钥字母如是。
下面给出代码实现:
def getKey(text,length): # 获取密钥key = [] # 定义空白列表用来存密钥#已知的字母出现概率alphaRate = [0.082, 0.015,0.028,0.043,0.127,0.022,0.02,0.061,0.07,0.002,0.008,0.04,0.024,0.067,0.075,0.019,0.001,0.06,0.063,0.091,0.028,0.01,0.023,0.001,0.02,0.001]
#更准确的概率,使用一个就ok#alphaRate =[0.08167,0.01492,0.02782,0.04253,0.12705,0.02228,0.02015,0.06094,0.06996,0.00153,0.00772,0.04025,0.02406,0.06749,0.07507,0.01929,0.0009,0.05987,0.06327,0.09056,0.02758,0.00978,0.02360,0.0015,0.01974,0.00074]matrix =textToList(text,length) #将明文按照密钥长度分组成二位列表for i in range(length):w = [row[i] for row in matrix] #获取每组密文中第i位的密文 这都是用同一个字母加密的li = countList(w) #计算里面的字母频率powLi = [] #交互重合指数for j in range(26):Sum = 0.00000for k in range(26):Sum += alphaRate[k]*li[k] # Ic的值Sum[k] += alphaRate[k]*li[k+j] 的话 就不用后面的切片操作powLi.append(Sum)li = li[1:]+li[:1]#循环移位 向左移一位 Abs = 1ch = ''for j in range(len(powLi)):if abs(powLi[j] -0.065546)<Abs: # 找出最接近英文字母重合指数的项Abs = abs(powLi[j] -0.065546) # 保存最接近的距离,作为下次比较的基准ch = chr(j+97)key.append(ch)return key#用到的两个子函数
def countList(lis): # 统计字母频率li = []alphabet = [chr(i) for i in range(97,123)] //生成小写字母表for c in alphabet: 统计26个字母的出现概率count = 0for ch in lis:if ch == c:count+=1li.append(count/len(lis))return li #返回字母表每个字母的出现概率def textToList(text,length): # 根据密钥长度将密文分组textMatrix = [] #二维表 里面添加分组数个分组 每个分组中都是按照密钥加密的row = [] #行 = 分组 每个row都是按照密钥逐一加密的 每个row长度为密钥的元素个数index = 0 #从0开始for ch in text:row.append(ch)index += 1if index % length ==0: #一组完成后,加入二维表textMatrix.append(row)row = []return textMatrix三、密文还原为明文
因为我们的密钥是重复使用的,所以在还原时,需要不断根据密文字母的位置对密钥长度取余,判断使用密钥的哪个字母。
plainText = ''
index = 0
for ch in cipherText:c = chr((ord(ch)-ord(key[index%length])+26)%26+97) #字母的ascii值与对该位置加密的密钥字母,相对位移plainText += cindex+=1至此,我们就已经完成了vigenere的 唯密文破解。
前面的代码已经很完善了,如果还有不明白的,这里附上完整源码<传送门>。
附:图源水印
加油加油加油啊~
不要辜负大好年华!
这篇关于Vigenere密码的唯密文攻击暴力破解(python实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



