本文主要是介绍《快学scala第二版》第四章 练习答案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
4.1 设置一个映射,其中包含你想要的一些装备,以及它们的价格。然后构建另一个映射,采用同一组键,但是价格上打9折
var equiments = Map("shoes" -> 200, "pants" -> 80)var newMap = for((k,v) <- equiments) yield (k, 0.9 * v)println(newMap)
4.2 编写一段程序,从文件中读取单词。用一个可变映射来清点每个单词出现的频率。读取这些单词的操作可以使用java.util.Scanner:
val in = new java.util.Scanner(new java.io.File(“myfile.txt”)) while(in.hasNext()) 处理 in.next() 或者翻到第9章看看更Scala的做法。 最后,打印出所有单词和它们出现的次数。
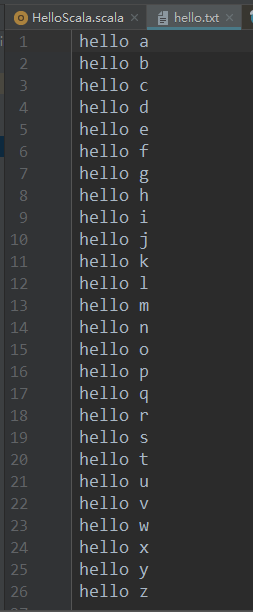
文件hello.txt如下:
def main(args: Array[String]): Unit = {var file = scala.io.Source.fromFile("hello.txt","UTF-8")var words = file.mkString.split("\\s+")var map = scala.collection.mutable.Map[String,Int]()for( word <- words){map(word) = (map.getOrElse(word, 0) + 1)}println(map)}
4.3 重复前一个练习,这次用不可变的映射
def main(args: Array[String]): Unit = {val in = new Scanner(new File("hello.txt"))var map = Map[String,Int]()while (in.hasNext()) {var str = in.next()map += (str -> (map.getOrElse(str, 0) + 1))}println(map)}
上面的Map其实就是scala.collection.immutable.Map,即不可变的映射。
不可变映射与可变映射的区别就是,每次添加元素,都会返回一个新的映射
这里我们再改用第9章的方式:
def main(args: Array[String]): Unit = {var file = scala.io.Source.fromFile("hello.txt","UTF-8")var words = file.mkString.split("\\s+")var map = scala.collection.immutable.Map[String,Int]()for( word <- words){map += (word -> (map.getOrElse(word, 0) + 1))}println(map)}
4.4 重复前一个练习,这次使用已排序的映射,以便单词可以按顺序打印出来
和上面的代码没有什么区别,只是将映射修改为SortedMap
def main(args: Array[String]): Unit = {var file = scala.io.Source.fromFile("hello.txt","UTF-8")var words = file.mkString.split("\\s+")var map = scala.collection.mutable.SortedMap[String,Int]()for( word <- words){map(word) = (map.getOrElse(word, 0) + 1)}println(map)}
4.5 重复前一个练习,这次使用java.util.TreeMap并使之适用于Scala API
原本想按书上的操作,but:
@deprecated("Use `asScala` instead", "2.13.0")def mapAsScalaMap[A, B](m: ju.Map[A, B]): mutable.Map[A, B] = asScala(m)
我用的是2.13版本~经过一番研究:
var file = scala.io.Source.fromFile("hello.txt","UTF-8")var words = file.mkString.split("\\s+")import scala.jdk.CollectionConverters._var source = new java.util.TreeMap[String,Int]()var map = source.asScalafor( word <- words){map(word) = (map.getOrElse(word, 0) + 1)}println(map)
4.6 定义一个链式哈希映射,将"Monday"映射到java.util.Calendar.MONDAY,依次类推加入其他日期。展示元素是以插入的顺序被访问的
var map = scala.collection.mutable.LinkedHashMap[String,Int]()map += ("Monday" -> Calendar.MONDAY)map += ("Tuesday" -> Calendar.TUESDAY)map += ("Wednesday" -> Calendar.WEDNESDAY)println(map)
4.7 打印出所有Java系统属性的表格 ,类似于下面这样:

4.8 编写一个函数minmax(values:Array[Int]),返回数组中最小值和最大值的对偶
def minmax(values:Array[Int]) = {(values.min,values.max)}
4.9 编写一个函数Iteqgt(values:Array[Int],v:Int),返回数组中小于v,等于v和大于v的数量,要求三个值一起返回
Scala代码
def Iteqgt(values:Array[Int],v:Int) = {(values.count(_ < 0),values.count(_ == 0),values.count(_ > 0))}
4.10 当你将两个字符串拉链在一起,比如"Hello".zip(“World”),会是什么结果?想出一个讲得通的用例

zip的doc如下:
/** Returns a $coll formed from this $coll and another iterable collection* by combining corresponding elements in pairs.* If one of the two collections is longer than the other, its remaining elements are ignored.** @param that The iterable providing the second half of each result pair* @tparam B the type of the second half of the returned pairs* @return a new $coll containing pairs consisting of corresponding elements of this $coll and `that`.* The length of the returned collection is the minimum of the lengths of this $coll and `that`.*/def zip[B](that: IterableOnce[B]): CC[(A @uncheckedVariance, B)] = iterableFactory.from(that match { // sound bcs of VarianceNotecase that: Iterable[B] => new View.Zip(this, that)case _ => iterator.zip(that)})
我们可以很清楚的看到和iterable相关,String可以看成是字符数组,也就是可迭代的~那么zip就是针对每个字符。
这篇关于《快学scala第二版》第四章 练习答案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!