本文主要是介绍SpringCache使用和注意事项,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、基本原理与使用方法论
1.1、基本介绍
1.2、SpringCache具有如下特点
1.3、Spring缓存实现
1.4、声名式缓存注解
1.5、SpringBoot的支持
1.6、开启声名式缓存支持
1.7、缓存比较
2、使用场景
2.1、条件缓存
2.2、综合运用
3、实现成果(使用Spring 与SpringCache JCache实现)
4、可运行源码地址
1、基本原理与使用方法论
1.1、基本介绍
一个应用主要瓶颈在于数据库的IO,大家都知道内存的速度是远远快于硬盘的速度(即使固态硬盘与内容也无法比拟)。应用之中经常会遇到返回相同的数据(数据字典,行政区划树),因为这些数据变化的可能性很小。假如我们使用传统的方式每次都通过接口与数据库打交道去请求获得;是不是每次都既消耗了内存资源、网络资源、数据库资源、CPU资源,又导致大量的时间耗费在数据库查询,及远程方法调用上;从而导致程序性能的恶化。这种场景就是需要使用缓存来解决这类问题。我们把数据缓存在内存之中,以后每次获取直接内存之中获得;使得程序获得极大的性能提升。下图是我们日常Web开发之中多种缓存场景。

日常研发中使用的缓存有如下几类不限于此:
EhCache:此缓存框架一直伴随着Spring,Hibernate,Mybatis等等。在SpringBoot出来之前都已经广泛的使用来做为一级缓存。
Guava: Google出品的框架,也支持缓存。
Redis:在我们日常开发之中经常使用的;并且被大众广泛接受的速度极快的缓存。
memcached:是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。
本文章将介绍的缓存SpringCache,自从Spring 3.1 引入了基于注解 annotation 的缓存 cache 技术,SpringCache本质上不是一种缓存的实现,而是一种缓存的抽象。Spring此框架的原则是让使用者方便开发,也能很好的支持第三方框架集成。如同Spring实现的SpringJdbc一样。
SpringCache 通过在现有代码之中,仅添加少量各种预先定义好的 注解 annotation,即能达到缓存方法返回对象的效果。降低了开发者使用缓存技术的学习成本。
SpringCache 缓存技术具备相当的灵活性,不仅能够使用 SpEL(Spring Expression Language)来定义缓存的 key 和各种 condition,而且提供开箱即用的缓存临时存储方案,也支持与主流专业缓存(EHCache、Redis ....)集成。
1.2、SpringCache具有如下特点
- 通过少量的配置 annotation 注释即可使得既有代码支持缓存
- 支持开箱即用 Out-Of-The-Box,即不用安装和部署额外第三方组件即可使用缓存
- 支持 Spring Express Language,能使用对象的任何属性或者方法来定义缓存的 key 和 condition
- 支持 AspectJ,并通过其实现任何方法的缓存支持
- 支持自定义 key 和自定义缓存管理者,具有相当的灵活性和扩展性
- 支持各种缓存实现,默认基于ConcurrentMap实现的ConcurrentMapCache,同时支持其他缓存实现

从以上的注解中可以看出,虽然使用注解的确方便,但是缺少灵活的缓存策略,
缓存策略:
-
TTL(Time To Live )
存活期,即从缓存中创建时间点开始直到它到期的一个时间段(不管在这个时间段内有没有访问都将过期) -
TTI(Time To Idle)
空闲期,即一个数据多久没被访问将从缓存中移除的时间
项目中可能有很多缓存的TTL不相同,这时候就需要编码式使用编写缓存。
1.3、Spring缓存实现
Spring缓存的接口:org.springframework.cache.Cache ;org.springframework.cache.CacheManager这两个接口都在context中,一个是用来提供缓存,一个是用来提供管理缓存。
CacheManager是Spring提供的各种缓存技术抽象接口,
Cache接口包含缓存的各种操作(增加、删除、获得缓存,我们一般不会直接和此接口打交道)。
Spring支持的CacheManager实现如下图:
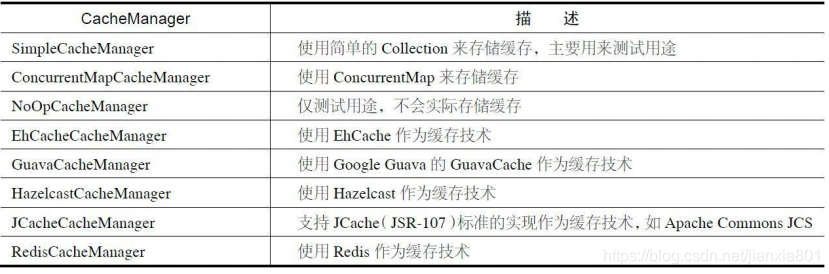
1.4、声名式缓存注解
Spring提供了4个注解来声明缓存规则(又是使用注解式的AOP的一个生动例子)。
所示。

@Cacheable、@CachePut、@CacheEvit都有value属性,指定的是要使用的缓存名称;key属性指定的是
数据在缓存中的存储的键。
1.5、SpringBoot的支持
在springboot中,已经为cache做了自动配置,如图:
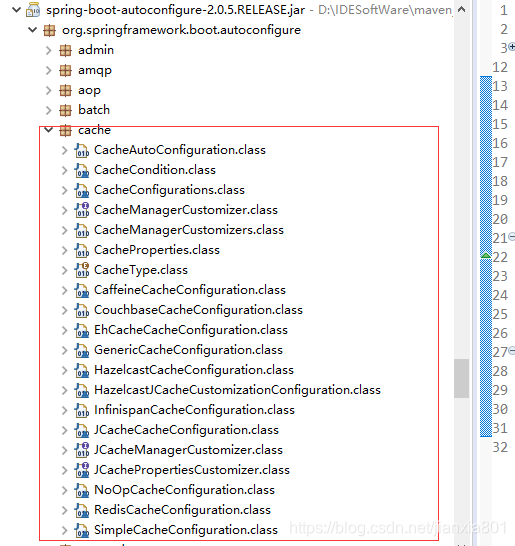
在Spring Boot环境下,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在配置类使用@EnableCaching开启缓存支持即可。
1.6、开启声名式缓存支持
开启声名式缓存支持十分简单,只需在配置类上使用@EnableCaching注解即可,例如:
@Configuration
@EnableCaching
public class QixueAiApplication {
}1.7、缓存比较
项目中注解缓存只能配置一个,所以可以通过以下引入哪个配置文件来决定使用哪个缓存。
当然,可以通过其他配置搭配使用两个缓存机制。比如ecache做一级缓存,redis做二级缓存。

2、使用场景
2.1、条件缓存
根据运行流程,如下@Cacheable将在执行方法之前( #result还拿不到返回值)判断condition,如果返回true,则查缓存;
@Cacheable(value = "user", key = "#id", condition = "#id lt 10")
public User conditionFindById(final Long id)
如下@CachePut将在执行完方法后(#result就能拿到返回值了)判断condition,如果返回true,则放入缓存
@CachePut(value = "user", key = "#id", condition = "#result.username ne 'zhang'")
public User conditionSave(final User user)
如下@CachePut将在执行完方法后(#result就能拿到返回值了)判断unless,如果返回false,则放入缓存;(即跟condition相反)
@CachePut(value = "user", key = "#user.id", unless = "#result.username eq 'zhang'")
public User conditionSave2(final User user)
如下@CacheEvict, beforeInvocation=false表示在方法执行之后调用(#result能拿到返回值了);且判断condition,如果返回true,则移除缓存;
@CacheEvict(value = "user", key = "#user.id", beforeInvocation = false, condition = "#result.username ne 'zhang'")
public User conditionDelete(final User user)2.2、综合运用
package com.whdcmap.example.code.service;import java.util.HashSet;
import java.util.Set;import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;import com.whdcmap.example.code.entity.User;/***
*@purpose:用户 使用 SpringCache 缓存
*@author:jianxiapc
*@since:2019年3月11日
***/
@Service
@CacheConfig(cacheNames = {"user", "user2"})
public class UserService {Set<User> users = new HashSet<User>();@CachePut(key = "#user.id")public User save(User user) {users.add(user);return user;}@CachePut(key = "#user.id")public User update(User user) {users.remove(user);users.add(user);return user;}@CacheEvict(key = "#user.id")public User delete(User user) {users.remove(user);return user;}@CacheEvict(allEntries = true)public void deleteAll() {users.clear();}@Cacheable(key = "#id")public User findById(final Long id) {System.out.println("cache miss, invoke find by id, id:" + id);for (User user : users) {if (user.getId().equals(id)) {return user;}}return null;}}3、实现成果(使用Spring 与SpringCache JCache实现)
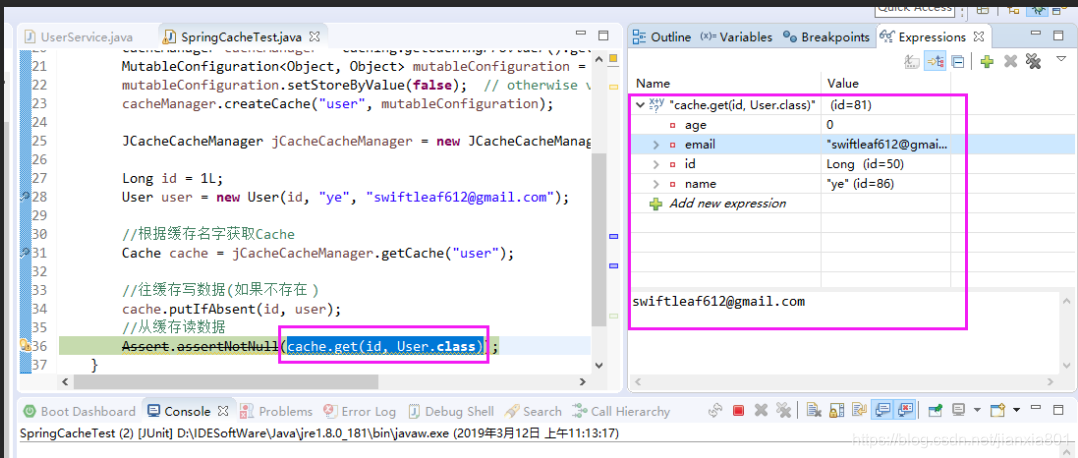

4、可运行源码地址
https://github.com/jianxia612/SpringCache.git
参考文章:https://mp.weixin.qq.com/s/z0fBCVkN7F1zIfBDzpVTsA 图片版权归于此
这篇关于SpringCache使用和注意事项的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





