本文主要是介绍Hive统计每日新增及其二日和三十日回访比例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据如下:
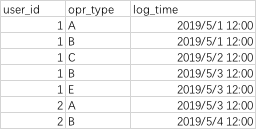
一、求每日新增
方法:每日新增即用户第一次访问,那么此时按照用户的id为key做分组,求他访问的最大时间和最小时间(天);
如果最大时间等于最小时间,那么说明用户是第一次访问,否则不是;那么总的来说就是按照用户的最小时间统计即可
selectmin_date,count(distinct user_id) as per_day_new
from
(selectuser_id,min(log_date) as min_datefrom tablegroup by user_id
)t
group by min_date;
该sql就能统计出来每日的新增用户数
二、求二日和三十日的回访比例
回访比例计算公式=二日回访用户数/总体用户数;由该公式可知需要计算二日和三十日回访的用户数,以及求总体的用户数;
selectround(second_log_cnt/float(cnt), 3) as second_log_rate,round(thirty_log_cnt/float(cnt), 3) as thirty_log_rate
from
(selectcount(distinct user_id) as cnt,count(distinct if(date_rank=1,user_id,null)) as second_log_cnt,count(distinct if(date_rank=30,user_id,null)) as thirty_log_cntfrom(selectuser_id,log_date,dense_rank() over(partition by user_id order by substr(log_time, 0, 10) asc) as date_rankfrom table)t
)tt
这篇关于Hive统计每日新增及其二日和三十日回访比例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





