本文主要是介绍论文阅读 | Learning Event-Driven Video Deblurring and Interpolation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:利用事件相机作的视频去糊和视频插帧文章,发表在ECCV2020
论文地址:【here】
Learning Event-Driven Video Deblurring and Interpolation
引言
目前去糊的方法没有办法解决特别糊的情况,因此可以利用一种低时延的新型相机解决特别糊的图片的去糊问题
目前主要有两种方法:
第一种pan等人的传统方法(CVPR2019),通过优化的思想还原出阈值C,但是这种方法假设阈值是固定的,但其实阈值由于硬件设备和和环境影响并不一定是固定的
比如:作者对下图的示例估计了全局的阈值,并不是一样的

第二种是Jiang等人提出的基于CNN的去糊方法(CVPR2020),这种方法网络架构大,并且去糊和细化是分开的,效果一般
本人提出了一个生成高速视频的方法,用动态滤波器的思想解决了全局阈值自适应的问题
方法动机
这一部分作者通过阐释了事件相机的原理,利用残差的思想推出,两张清晰帧与中间事件点之间的关系 和 模糊帧和清晰帧与事件点的关系
两张清晰帧与中间事件点之间的关系
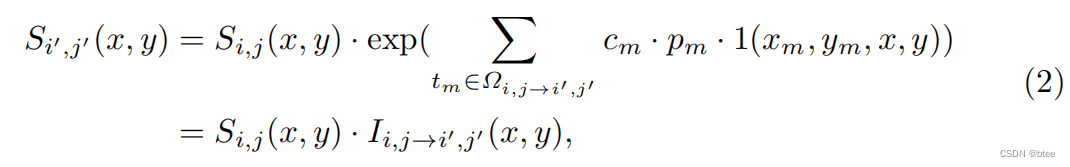
模糊帧和清晰帧与事件点的关系
由于模糊帧可以看成一段时间内的清晰帧的积分,这里直接平均
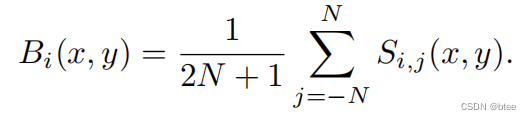
各个清晰帧之间由可以由事件点关联起来
即模糊帧和清晰帧与事件点的关系
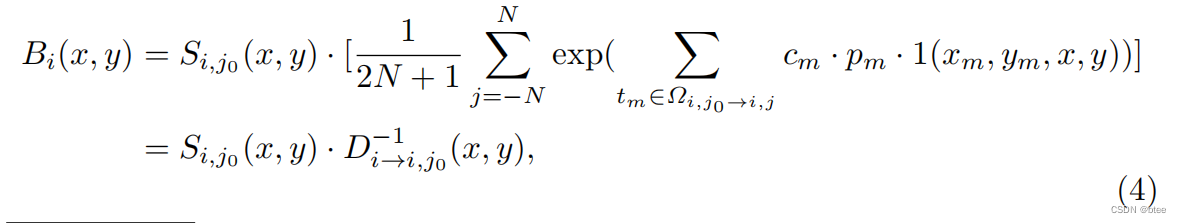
网络设计
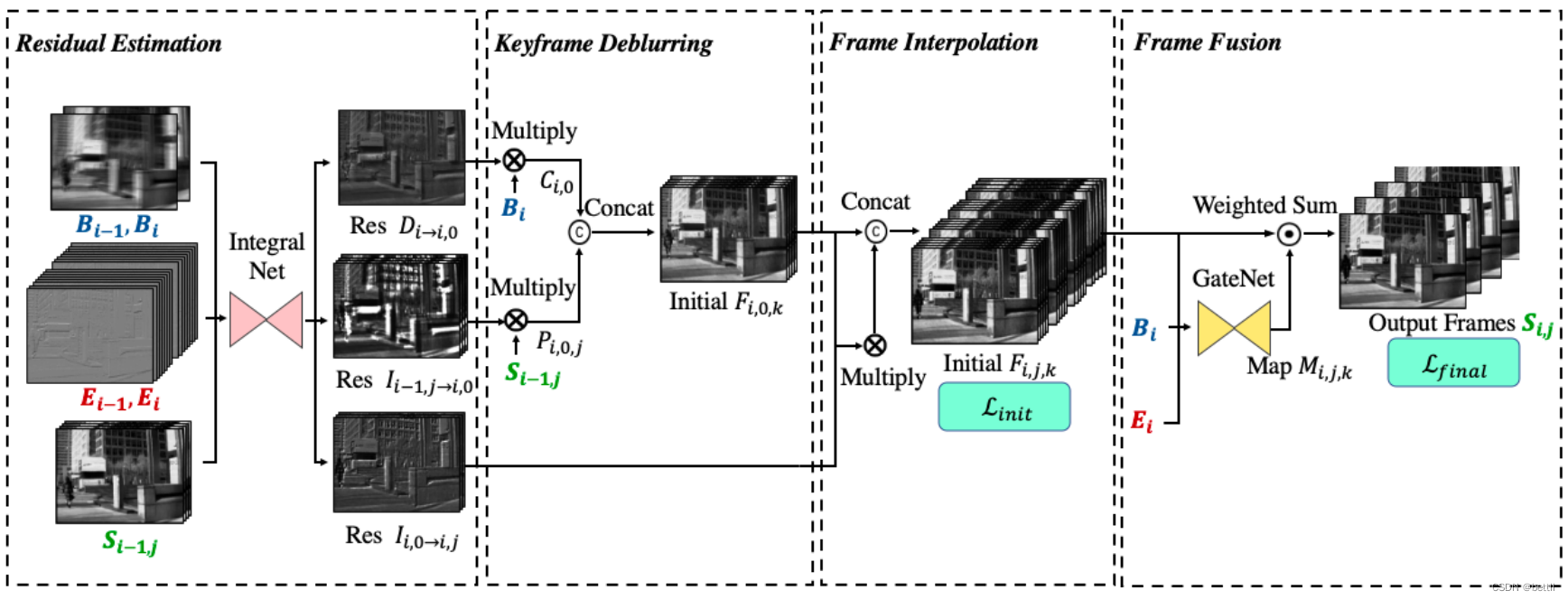
从左自右依次是四个部分,残差估计、关键帧去糊、插帧、帧融合
残差估计
由模糊帧、事件点、和上一时刻阶段i-1求出的清晰帧作为输入,到网络integralNet
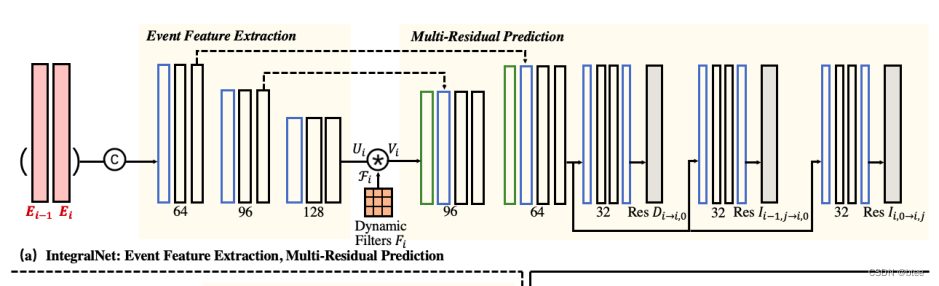
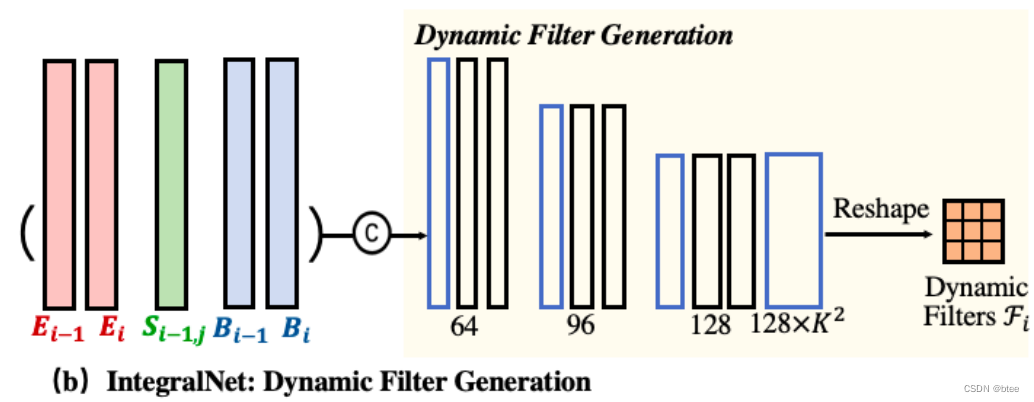
其中主网络的输入还是有事件点拍成的图片作输入,但是粗尺度下的动态滤波器的生成,由三个输入共同决定
残差估计一共出三个残差,其中两个残差作为去糊残差,一个残差作为插帧残差
关键帧去糊
去糊残差1
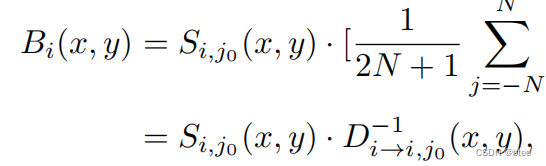
清晰帧S=D* B
去糊残差2
这个残差不是由模糊图像来的,是由上一曝光时刻i-1求得的清晰帧来的,通过上一个时刻到这一时刻的事件点,可以再求一个残差
清晰帧 Si = R * Si-1
由于去糊算出的结果都cat起来,最后得到了2N +1个结果
插帧
插帧残差
即这一段曝光时刻的各个时间的值,跟去糊残差2一个算法
最后生成了2N个值
帧融合
这里的帧融合作者采用3D网络
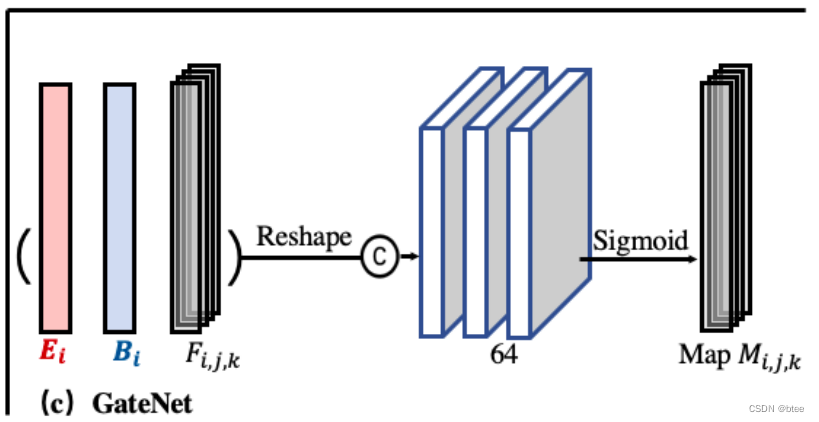
其中,由于插帧的输出是四维, E和B都被展开成四维,最后生成需要插帧数的清晰图片
实验
对比实验
Gopro数据集

真实数据集
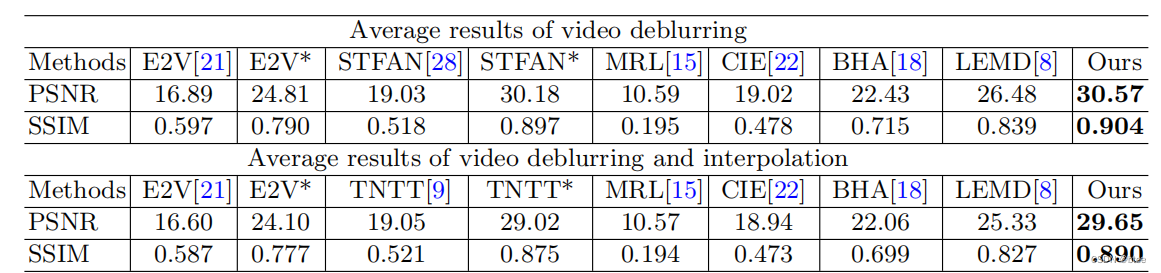
(这个值高得属实有些离谱了)

总结
这篇在性能上大幅超过之前的方法,用到的网络也不复杂,在19年的那篇文章提出的公式上进行CNN网络化的比较成功的方法
这篇关于论文阅读 | Learning Event-Driven Video Deblurring and Interpolation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)