本文主要是介绍带着面试官畅游Java线程池,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:【java】并发之线程池||5:30开始剖析_哔哩哔哩_bilibili
目录
一、为什么使用线程池
二、线程池的优势
三、线程池的简单使用
1、Executors.newCachedThreadPool()
2、Executors.newFixedThreadPool()
3、Executors.newSingleThreadExecutor()
四、线程池源码分析
1、线程池参数
2、执行流程分析
3、cachedThreadPool()源码分析
4、newFixedThreadPool()源码分析
一、为什么使用线程池
java中经常需要用到多线程来处理一些业务,如果单纯使用继承Thread或者实现Runnable接口的方式来创建线程,那样势必有创建及销毁线程耗费资源、线程上下文切换问题。同时创建过多的线程也可能引发资源耗尽的风险,这个时候引入线程池比较合理,方便线程任务的管理。
java中涉及到线程池的相关类均在jdk1.5开始的 java.util.concurrent(JUC)包中,涉及到的几个核心类及接口包括:Executor、Executors、ExecutorService、ThreadPoolExecutor、FutureTask、Callable、Runnable等。
二、线程池的优势
总体来说,线程池有如下的优势:
(1)降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
三、线程池的简单使用
1、Executors.newCachedThreadPool()
cached的池子非常大,可以有很多的线程并发运行。
package threadPool;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadPoolDemo01 {public static void main(String[] args) {ExecutorService e1 = Executors.newCachedThreadPool();
// ExecutorService e2 = Executors.newFixedThreadPool(10);
// ExecutorService e3 = Executors.newSingleThreadExecutor();//使用线程e1.execute(new Task(1));}
}class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);}
}

已经打出了当前线程的名字。
我们将调用线程的方法执行100次,由于run方法执行有时长,线程来不及回池子时就需要再执行,所以需要开启另一个线程。执行100次大概需要开启三十多个线程。
public class ThreadPoolDemo01 {public static void main(String[] args) {ExecutorService e1 = Executors.newCachedThreadPool();
// ExecutorService e2 = Executors.newFixedThreadPool(10);
// ExecutorService e3 = Executors.newSingleThreadExecutor();//使用线程for(int i=0; i<100; i++) {e1.execute(new Task(i));}}
}class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);}
} 

线程池的序号大概是到三十几,说明从线程池中拿了三十多个线程。
我们在run方法中加一个一秒的睡眠,再看看结果。
class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);//睡1stry {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}
}
可以看到大概使用了100个线程。说明每一次调用都需要用一个新的线程。
2、Executors.newFixedThreadPool()
fixed线程池需要指定生成的线程数量。我们在代码中指定生成10个线程。
public class ThreadPoolDemo01 {public static void main(String[] args) {// ExecutorService e1 = Executors.newCachedThreadPool();ExecutorService e2 = Executors.newFixedThreadPool(10);
// ExecutorService e3 = Executors.newSingleThreadExecutor();//使用线程for(int i=0; i<100; i++) {e2.execute(new Task(i));}}
}class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);//睡1stry {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}
}线程池中只会生成10个线程,如果run方法中睡1秒钟,那么在1s之内只能打印出10个线程名字,我们的代码执行完需要10s。
3、Executors.newSingleThreadExecutor()
这个线程池中只有一个线程,可以理解为fixed的单数版。
public class ThreadPoolDemo01 {public static void main(String[] args) {// ExecutorService e1 = Executors.newCachedThreadPool();
// ExecutorService e2 = Executors.newFixedThreadPool(10);ExecutorService e3 = Executors.newSingleThreadExecutor();//使用线程for(int i=0; i<100; i++) {e3.execute(new Task(i));}}
}class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);//睡1stry {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}
}

每次打印出的线程名字都相同,说明自始至终都使用的用一个线程。1s钟只打印1个名字,代码执行完需要100s(需要等1s后线程回到线程池,才能再使用这个线程)。
四、线程池源码分析
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}可以看到他们都是由ThreadPoolExecutor构造出的方法,那我们再看看ThreadPoolExecutor:
/*** Creates a new {@code ThreadPoolExecutor} with the given initial* parameters.** @param corePoolSize the number of threads to keep in the pool, even* if they are idle, unless {@code allowCoreThreadTimeOut} is set* @param maximumPoolSize the maximum number of threads to allow in the* pool* @param keepAliveTime when the number of threads is greater than* the core, this is the maximum time that excess idle threads* will wait for new tasks before terminating.* @param unit the time unit for the {@code keepAliveTime} argument* @param workQueue the queue to use for holding tasks before they are* executed. This queue will hold only the {@code Runnable}* tasks submitted by the {@code execute} method.* @param threadFactory the factory to use when the executor* creates a new thread* @param handler the handler to use when execution is blocked* because the thread bounds and queue capacities are reached* @throws IllegalArgumentException if one of the following holds:<br>* {@code corePoolSize < 0}<br>* {@code keepAliveTime < 0}<br>* {@code maximumPoolSize <= 0}<br>* {@code maximumPoolSize < corePoolSize}* @throws NullPointerException if {@code workQueue}* or {@code threadFactory} or {@code handler} is null*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}1、线程池参数
- int corePoolSize 核心线程数,也是线程池中常驻的线程数,线程池初始化时默认是没有线程的,当任务来临时才开始创建线程去执行任务
- int maximumPoolSize 最大线程数,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
- long keepAliveTime 线程的最大存活时间,空闲时间超过keepAliveTime就会被自动终止回收掉,一直回收到剩corePoolSize个
- TimeUnit unit 存活时间的单位
- BlockingQueue<Runnable> workQueue 阻塞队列
- ThreadFactory threadFactory 线程工厂
- RejectedExecutionHandler handler 拒绝执行时的处理函数
按照下面的代码来执行一下
public class ThreadPoolDemo01 {public static void main(String[] args) {// ExecutorService e1 = Executors.newCachedThreadPool();
// ExecutorService e2 = Executors.newFixedThreadPool(10);
// ExecutorService e3 = Executors.newSingleThreadExecutor();ThreadPoolExecutor t = new ThreadPoolExecutor(10, //corePoolSize20, //maximumPoolSize10, //keepAliveTimeTimeUnit.SECONDS, //TimeUnit new ArrayBlockingQueue<>(10) //BlockingQueue);//使用线程for(int i=0; i<100; i++) {t.execute(new Task(i));}}
}class Task implements Runnable{int i;public Task(int i) {this.i = i;}@Overridepublic void run() {//打印当前线程的名字System.out.println(Thread.currentThread().getName() + "-----" + i);//睡1stry {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}
}在代码中,我们将核心线程数设置为10,最大线程数设置为20,最大存活时间设置为10,单位为秒,阻塞队列的大小设置为10
看一下执行结果:
pool-1-thread-3-----2
pool-1-thread-7-----6
pool-1-thread-1-----0
pool-1-thread-2-----1
pool-1-thread-4-----3
pool-1-thread-5-----4
pool-1-thread-6-----5
pool-1-thread-10-----9
pool-1-thread-9-----8
pool-1-thread-8-----7
pool-1-thread-11-----20
pool-1-thread-12-----21
pool-1-thread-13-----22
pool-1-thread-14-----23
pool-1-thread-15-----24
pool-1-thread-16-----25
pool-1-thread-17-----26
pool-1-thread-18-----27
pool-1-thread-19-----28
pool-1-thread-20-----29
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task threadPool.Task@135fbaa4 rejected from java.util.concurrent.ThreadPoolExecutor@45ee12a7[Running, pool size = 20, active threads = 20, queued tasks = 10, completed tasks = 0]at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(Unknown Source)at java.util.concurrent.ThreadPoolExecutor.reject(Unknown Source)at java.util.concurrent.ThreadPoolExecutor.execute(Unknown Source)at threadPool.ThreadPoolDemo01.main(ThreadPoolDemo01.java:27)
pool-1-thread-16-----11
pool-1-thread-15-----12
pool-1-thread-13-----15
pool-1-thread-19-----10
pool-1-thread-14-----13
pool-1-thread-8-----18
pool-1-thread-11-----17
pool-1-thread-12-----16
pool-1-thread-18-----14
pool-1-thread-9-----192、执行流程分析
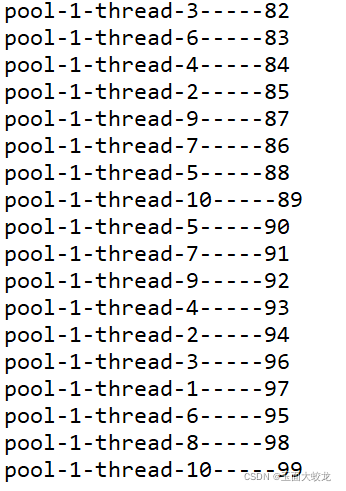
由于我们的核心线程数(corePoolSize)设置为10,就会有10个常驻的核心线程去执行
pool-1-thread-3-----2
pool-1-thread-7-----6
pool-1-thread-1-----0
pool-1-thread-2-----1
pool-1-thread-4-----3
pool-1-thread-5-----4
pool-1-thread-6-----5
pool-1-thread-10-----9由于run方法中睡眠了一秒钟,后面进入的任务会进入阻塞队列(blockingQueue)中,当阻塞队列中的十个空间被填满后,创建普通的线程去执行。
pool-1-thread-11-----20
pool-1-thread-12-----21
pool-1-thread-13-----22
pool-1-thread-14-----23
pool-1-thread-15-----24
pool-1-thread-16-----25
pool-1-thread-17-----26
pool-1-thread-18-----27
pool-1-thread-19-----28
pool-1-thread-20-----29由于blockingQueue的大小为10,10个任务进去之后,再进任务就会报拒绝执行(RejectedExecutionException)的错了:
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task threadPool.Task@135fbaa4 rejected from java.util.concurrent.ThreadPoolExecutor@45ee12a7[Running, pool size = 20, active threads = 20, queued tasks = 10, completed tasks = 0]at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(Unknown Source)at java.util.concurrent.ThreadPoolExecutor.reject(Unknown Source)at java.util.concurrent.ThreadPoolExecutor.execute(Unknown Source)at threadPool.ThreadPoolDemo01.main(ThreadPoolDemo01.java:27)1秒之后,线程执行结束之后回到线程池,就可以继续去队列中接受任务。将队列中的十个任务接收完。
核心线程和普通线程是不作区分的,他们没有任何的区别,所以接收任务的时候也是谁先结束谁就去接收。
pool-1-thread-16-----11
pool-1-thread-15-----12
pool-1-thread-13-----15
pool-1-thread-19-----10
pool-1-thread-14-----13
pool-1-thread-8-----18
pool-1-thread-11-----17
pool-1-thread-12-----16
pool-1-thread-18-----14
pool-1-thread-9-----19
3、cachedThreadPool()源码分析
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),threadFactory);}可以看到在cached中,核心线程数为0,线程总数为无穷大,阻塞队列为0,线程存活时间为60s。
这说明cached中没有核心线程,任务也不能进入阻塞队列,那么在一开始就会申请普通线程去执行。而线程存活时间为60s,被复用的次数会非常多,除非线程结束任务后的60s内没有新任务,线程才会被销毁,由于核心线程数为0,所有的线程均会被回收;同时线程数总数位无穷大,可以同时有非常多的线程。
4、newFixedThreadPool()源码分析
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}核心线程数和最大线程数一样,都是传入的数值,销毁时间为0。
说明传入的线程都作为核心线程使用,并且使用之后立即销毁。
这篇关于带着面试官畅游Java线程池的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




