本文主要是介绍【python】半佛老师的表情包是怎么爬的?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
听半佛老师说他的表情包是爬的,有点好奇是怎么爬的?由此有了这篇文章。
我调研了几个表情包的网站,最后以斗图网为例https://www.doutula.com/photo/list/爬取网站上的表情图片。
为了简单,用python +Scrapy去做。
环境
Python3 + Scrapy(1.6.0)+ urllib + BeautifulSoup
如果没有Scrapy包,pip3 install Scrapy即可。
参考:https://docs.scrapy.org/en/latest/intro/tutorial.html
步骤
1.创建scrapy项目
# 最后一个是项目路径,会创建一个同名项目
scrapy startproject scrapy_test
命令创建项目,就像一些脚手架一样生成一个项目组织路径。会生成一个cfg文件,和一个同名scrapy_test路径,路径下有一个spiders路径,爬取的逻辑就在这个路径下写一个新类,实现scrpy.Spider的方法,此处新建了img_spider.py,逻辑怎么实现呢?向下看~
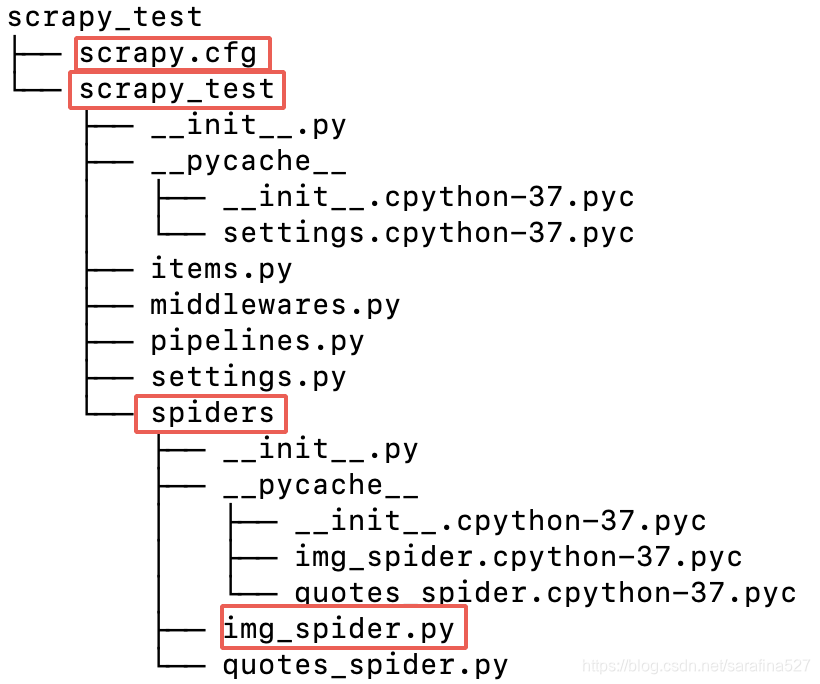
2.Spider爬取逻辑
- 指定名称name,后续启动要用
- 重写start_tequests,爬取指定地址,指定回调函数
- 重写回调函数parse,解析http响应,提取img标签中的图片路径,使用urllib http请求图片路径,并写入本地文件。
import os
import urllibimport scrapy
from bs4 import BeautifulSoupclass QuotesSpider(scrapy.Spider):name = "images"# 发送http请求def start_requests(self):urls = ['https://www.doutula.com/photo/list/']for url in urls:yield scrapy.Request(url=url, callback=self.parse) # 回调解析函数# 解析http响应,def parse(self, response):print(response)soup = BeautifulSoup(response.body, 'html.parser')path = "./result/"os.makedirs(path) #创建多级目录# 解析html标签,获取img标签tags = soup('img')for tag in tags:url = tag.get('data-original', None) #调研了网站,图片路径放在这个属性里print(url)if url != None:arr = url.split(sep='/')imgNm = arr[len(arr) - 1] # 获取文件名称img = urllib.request.urlopen(url) # 获取图片# outputfhand = open(path+imgNm, 'wb') # 打开本地文件size = 0# 分次拷贝while True:info = img.read(100000)if len(info) < 1: breaksize = size + len(info)fhand.write(info) # 防止一次性内存过大,分批写入到本地print(size, 'characters copied.')fhand.close()3.启动scrapy
scrapy crawl images 启动抓取后,跑一会儿就会发现成功啦,当前路径下创建了个result路径,切图片已经写入到这个路径下了~
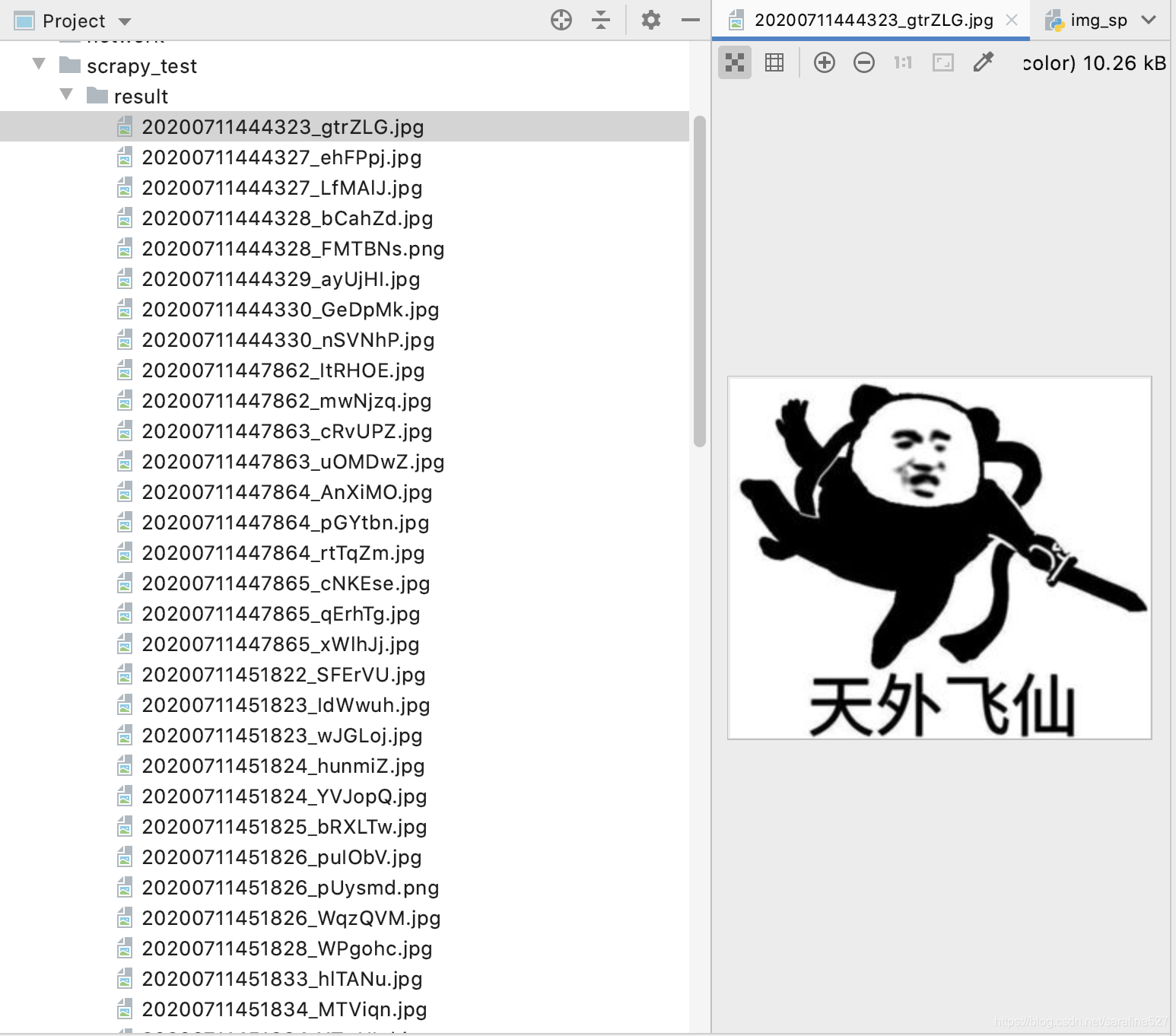
4.展望
其实这个网站是分页展示的,后续可以优化下,这样可以将所有页的图片都下载下来。
由于这个网站有3500+页,这篇仅是最简单的小demo,暂时就不做了,其实最简单实现方案就是urls数组增加带页号的url,如https://www.doutula.com/photo/list/?page=2。
这篇关于【python】半佛老师的表情包是怎么爬的?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




