本文主要是介绍论文阅读 - Hidden messages: mapping nations’ media campaigns,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:
https://link.springer.com/content/pdf/10.1007/s10588-023-09382-7.pdf
目录
1 Introduction
2 The influence model
2.1 The influence‑model library
3 Data
4 Methodology
4.1 Constructing observations
4.2 Learning the state‑transition matrices
5 Results
5.1 Account clusters
5.2 Coordinated link sharing
5.3 Top influencer
5.4 State‑linked tweet activity
6 Discussion
7 Conclusion
几个世纪以来,有权势的行为者一直在进行信息控制,限制、促进或影响信息环境,以适应其不断发展的机构。在数字时代,信息控制已经转移到了网上,信息行动现在瞄准了在新闻参与和公民辩论中发挥关键作用的网络平台。在本文中,我们使用离散时间随机模型来分析在线社交网络中的协调活动,将账户行为表示为相互作用的马尔可夫链。
我们从 206 个账户(其中一半被 Twitter 识别为参与了与国家有关的信息行动)发布的 31521 条推文的数据集中,评估了与国家有关的账户对与未与国家有关的账户对之间的协调性(以表面影响力衡量)。我们的分析表明,与国家有关的行动者之间的协调程度明显高于他们与无关联账户之间的协调程度。此外,与国家有关的账户之间的协调程度是无关联账户之间的七倍多。此外,我们还发现,在网络中代表最协调活动的账户没有追随者,这证明了我们的建模方法即使在没有显性网络结构的情况下也能发现隐藏连接的能力。
1 Introduction
网络媒体的消费率急剧上升,个人的在线社交网络(OSN)成为越来越受欢迎的新闻内容来源。希望操纵信息环境的国家和非国家行为体顺应了这一趋势,针对一系列在线平台发起了信息行动。自 2018 年 10 月以来,Twitter 已公开确认了 40 多起与国家有关的信息行动,这些行动被归咎于 20 多个国家,以其平台 Twittter 为目标(2022 年)。从 2017 年到 2021 年年中,Facebook 也同样删除并报告了来自 50 多个国家的 150 多起信息行动 Facebook(2021)。信息行动的特点可以概括为以战略目标为目的、从根本上具有欺骗性的协调活动(Erhardt 和 Pentland,2021 年)。这种欺骗不一定意味着明确的虚假信息(如断章取义的图片、议程设置,或在信息环境中充斥多余的信息以混淆视听(Starbird 等人,2019 年;King 等人,2017 年))。
错误/虚假信息领域的大部分文献都侧重于通过基于内容的特征(Alizadeh 等人,2020 年;Rheault 和 Musulan,2021 年)或基于网络的方法(Vargas 等人,2020 年)来检测信息操作。其他研究则研究了帖子活动的时间模式(Luceri 等人,2020 年;Magelinski 和 Carley,2020 年)。在本文中,我们选择重新审视影响模型,该模型最早由 Asavathiratham(2001 年)提出。该模型与 Magelinski 和 Carley(2020 年)中的时间方法最为相似,但其优势在于能够区分明显影响的方向性,而不是产生一个无向的账户对账户协调图。影响模型描述了网络化、相互作用的马尔可夫链的动态。马尔科夫链是一种生成随机变量序列的方法,其中当前值在概率上总是只依赖于最近的前一个值。
在这种情况下,我们选择将单个社交账户建模为马尔可夫链,其随机变量代表特定用户的帖子活动。利用影响力模型,我们可以仅根据帖子活动来衡量成对账户之间的协调性。从这些协调度量中,我们可以量化账户之间的隐藏联系以及潜在的不真实活动。我们关注信息操作的协调性有几个原因。首先,它减轻了与审核相关的一些隐私和偏见问题。其次,与基于内容的替代方法相比,影响建模方法更不依赖于语言和媒体。第三,与基于网络的方法不同,这种方法不需要访问底层网络结构。
我们的贡献如下。首先,我们提出了一种新颖的影响模型应用,用于检测参与信息操作的账户。其次,我们展示了如何仅凭协调的发帖活动就能将网络中的状态链接账户与其他账户区分开来。第三,我们发布了一个开源 Python 库,它能有效地实现影响模型,并支持从观测序列中学习其参数。该程序包可在 https:// pypi. org/ proje ct/ influ ence- model/ 上获取。
2 The influence model
影响模型通过马尔可夫链之间的 "影响 "来描述网络马尔可夫链之间的关系。该模型由相互作用的马尔可夫链网络组成,每个马尔可夫链与网络中的一个节点相关联。在网络层面,节点被称为站点,它们之间的联系由随机网络矩阵 D 描述。在局部层面上,每个站点都有一个内部马尔可夫链 Γ(A),并在任何给定的离散时间瞬间处于 Γ(A)的状态之一。这些状态由一个长度为 m 的状态向量 ⃗ s 表示,这个指示向量在与当前状态相对应的位置上包含一个 1,在其他位置上包含 0:

每条链都会根据自身及其邻链的状态进行演变。影响模型中第 i 个站点的状态更新分为三个阶段:
(1)第 i 个站点(sitei)随机选择一个邻居作为其确定站点;站点 j 被选中的概率为 d_ij;
(2)站点 j 在时间 k 的状态⃗,固定了概率向量
,该向量在用于 (3) 中去随机选择site i 的下一个状态。
(3)下一个状态 ⃗根据
实现。
状态转换矩阵 Aij 描述了站点 j 的状态转换概率如何取决于站点 i 以前的状态。Aij 是 mi × mj 的非负矩阵,各行总和为 1。A 是一个矩阵,Aij 位于其(i,j)块中。根据随机网络矩阵 D 和状态转换矩阵 A,可以计算出影响矩阵 H,该矩阵描述了网络中每个站点施加的 "影响"。H 表示影响模型中各站点组的联合状态,由 D' 和 {Aij} 的广义克朗克乘积给出。
![]()
影响模型已被应用于许多问题,从模拟电网故障到识别会议中的职能角色(Asavathi-ratham 等人,2001 年;Dong 等人,2007 年)。有关该模型及其特性和应用的更多详情,请读者参阅 Asavathiratham 等人 (2001) 和 Pan 等人 (2012)。
2.1 The influence‑model library
在发表这篇论文的同时,我们还发布了一个开源 Python 库,提供了影响模型的完整实现。该库支持定义新的影响模型,并通过应用模型的演化方程生成观测结果。它还提供了重建从一连串的观测数据中建立影响模型,学习参数 D、A 和 H。Basu 等人(2001 年)提出的joy示例演示了这一实现方法:

3 Data
在本文中,我们分析了一次针对推特、归属于中华人民共和国(PRC)的信息行动。该行动的重点是宣传中国共产党(CCP)有关新疆维族人待遇的言论。2021 年 12 月,推特公布了与这一与国家有关的信息行动相关的具有代表性的样本账户和推文,其中包括来自 2016 个独特账户的 31269 条推文。这些推文从 2019 年 4 月 20 日开始,到 2021 年 4 月 5 日结束。我们用 "无关联 "账户和推文扩充了这一数据集,"非关联 "账户和推文是指截至 2022 年 3 月推特平台上仍可用的账户和推文(未因涉嫌信息行动或其他平台违规而被删除)。非关联账户的推文是通过 Twitter Search API v2 收集的,选择在 2019 年 4 月 20 日至 2021 年 4 月 5 日期间发布的推文,其中至少包含一个关键词或标签(不区分大小写): "新疆"、"维吾尔族"、"维吾尔人"、"维吾尔人"、"维吾尔人"、"维吾尔人"、"维吾尔人"、"维吾尔人 "或 "维吾尔人"。该搜索查询共返回来自 2,665,001 个独特账户的 14,728,582 条推文。
为确保每个账户都有合理数量的观察结果(推文),我们只考虑推文总数排名前百分之一的账户的推文。这意味着一个账户必须在两年内至少发布 60 次推文才能被纳入分析。在对推文进行精选后,我们只剩下 103 个与国家有关的账户发布的 10,889 条推文和 27,003 个无关联账户发布的 6,231,955 条推文。然后,我们随机选择 103 个账户(相当于与国家有关的账户数量)及其相关推文进行分析。我们的最终数据集包括来自 206 个账户(50% 与国家有关,50% 无关联)的 31521 条推文。
4 Methodology
我们数据集中的每个账户都是网络图中的一个站点。两类账户(与国家有关联的账户和非关联账户)以及真实的网络结构(关注者与关注者之间的关系)并不是先验已知的。我们的目标是利用观察到的行为,量化决定每个站点在网络中地位的 "影响力"。
4.1 Constructing observations
站点通过发布信息(tweets)进行互动,这是我们观察到的行为。如果一个网站在离散时间瞬间 k 发布了一条信息,我们就认为该网站在时间 k 处于 "活跃 "状态。我们选择将推文划分为 1 小时的时间块,以确保有足够的粒度将明确协调的行为与开始流行的话题区分开来,同时还能确保在任何给定时间都有一定数量的账户可能处于 "活跃 "状态。每个账号的观察序列代表了该账号在一段时间内的状态。

考虑到我们期望协调的行动者会共同推动类似的叙述,我们对整体帖子活动的兴趣较小,而对按主题划分的帖子活动更感兴趣。我们为 "话题 "选择了一个简单的定义:任何实体都是一个话题。每条信息都包含零个或多个实体,定义为标签、URL 或用户提及。我们首先从帖子中提取所有实体,然后为每个实体构建跨所有站点的观察序列。
. 例如,对于实体 #hashtag,我们只需要如果账户发布了包含 #hashtag 的信息,则认为该账户为活跃账户。我们排除了从 Twitter API 收集账户时用作搜索条件的任何实体。此外,我们还对 URL 进行了规范化处理,删除了协议、子域和任何查询参数。
4.2 Learning the state‑transition matrices
在影响模型中,每个站点的状态会随着时间的推移而变化,这取决于网络中其他站点的 "影响"。这种影响部分由前面提到的状态转换矩阵表示。给定每个观测点的观测序列,我们就可以使用与 Basu 等人(2001)的方法类似的最大似然估计法重建状态转换矩阵。每个状态转换矩阵为 2 × 2,代表两种可能的状态:活跃和不活跃。如果站点 j 完全遵循站点 i 的行为(正向协调),那么 Aij 就是单位矩阵。为了得到每个状态转换矩阵的标量协调度量,我们计算 Aij 与单位矩阵的弗罗贝尼斯内积。协调度的范围为 [0,2]。0 代表最大正协调,即 site_i[k - 1] = site_j[k] ∀ k;2 代表最大负协调,即 site_i[k - 1] ≠ site_j[k] ∀ k。通过对所有节点的这些协调度量取平均值,我们可以确定每对节点的主状态-状态转移矩阵。
5 Results
我们发现,参与最协调活动的账户绝大多数是由与国家相关的行为体控制的账户。此外,我们发现,通过对更传统的关注者关注关系网络(即使可用)的分析,无法识别协调网络中心的帐户,因为这些帐户几乎没有关注者。
5.1 Account clusters
为了评估协调活动水平较高的账户群,我们根据成对的协调度量构建了一个协调网络。协调网络中的有向边 (i, j) 代表站点 i 对站点 j 有明显的影响,边的权重等于 1 减去协调度。我们主要关注的是正向协调--当一个账户模仿另一个账户的行为时,因此只有当协调度小于 1 时才会创建一条边(回顾一下,0 相当于最大正向协调)。这种筛选意味着并非所有账户都会出现在协调网络中。如果一个账户不能对另一个账户产生积极的 "影响",而其本身也没有受到积极的 "影响",那么这个账户就不存在。我们发现,协调程度高的账户群主要由与国家有关的行动者控制,每个账户群通常由所有与国家有关或所有无关联的账户组成。这与我们的直觉相吻合,即账户会根据其类别成员身份,在与之协调的账户中表现出明显的差异。
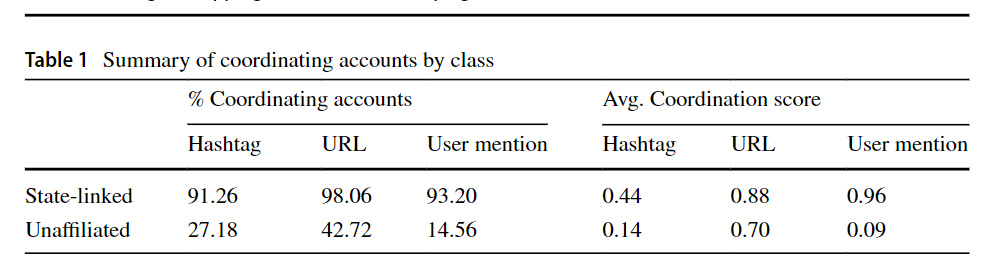
如表 1 所示,当我们单独研究这三种实体类型时,会发现它们的协调方式有所不同。在所有情况下,与国家有关的账户在参与协调活动的账户中占大多数,并且几乎只与其他与国家有关的账户进行协调。无关联账户在网络中最多的表现形式是URL共享,这可能是由于新出现的新闻报道在OSN中传播的速度很快。
5.2 Coordinated link sharing
在与国家有关的账户中,中国官方国家新闻机构新华社的一篇英文文章显示了最协调的活动。这篇报道谴责了美国因新疆涉嫌侵犯人权而实施的制裁。对于没有关联的账户,香港传媒摄影协会有限公司(PSHK Media)在Facebook上发布的一篇中文帖子描述了中共官员对新疆维吾尔人的“中国化”,显示出了最大的协调。帖子指责中共官员胁迫穆斯林少数民族庆祝中国传统节日并食用猪肉。有趣的是,Facebook 屏蔽了其平台上指向 PSHK Media 网站的重定向,而且截至本文撰写之时,该网站似乎已被其托管服务提供商暂停服务。
5.3 Top influencer
通过对标签、URL 和用户提及协调网络进行平均,得出了一个由 81 个账户组成的新网络,其中 75 个与国家有关,6 个与国家无关。在这个网络中,我们发现有一个账户的协调程度远远高于其他账户。这个 "顶级影响者 "与国家有关,并且只与其他与国家有关的账户协调。有趣的是,这个账户没有关注任何其他用户,也没有追随者。
在长达两年的中国信息行动中,该账户共发布了 87 条推文。59 条推文包含一个标签,其中最受欢迎的是 "新疆"、"新疆在线 "和 "停止新疆谣言"。28 条推文包含网址,除了中国共产党的官方报纸《人民日报》外,还引用了中国政府拥有的 8 家新闻或信息网站的报道。71 条用户推文包含用户提及。这些推文既有反驳国家强制绝育和新疆强迫劳动的争论性推文,也有描述新疆人民幸福、和平、富足生活的乐观推文。在活动开始时,该账号往往是最先开始分享新内容的账号之一,例如,一个以前未分享过的 URL,随后被其他与国家有关的账号转载,从而提高了其影响力分数。
5.4 State‑linked tweet activity
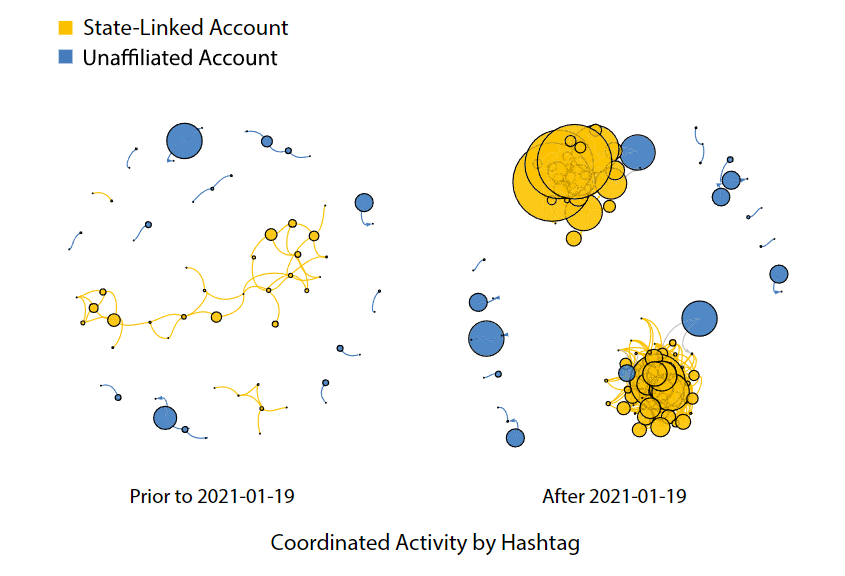
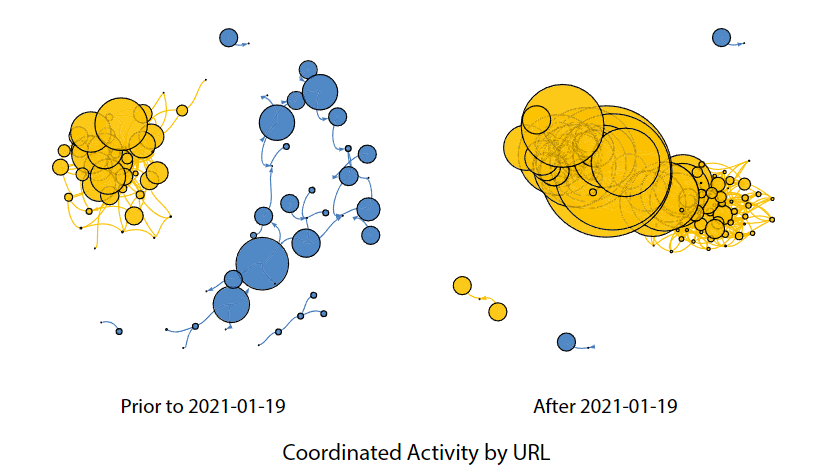
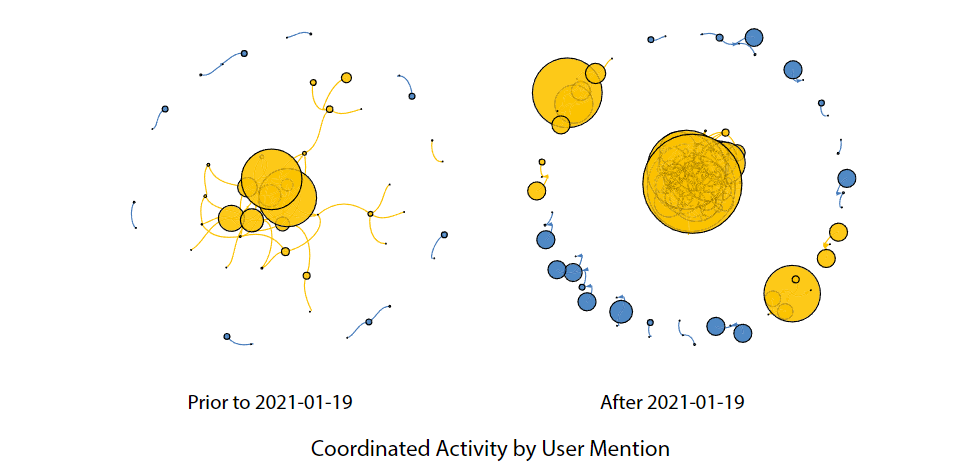
2021 年 1 月 19 日,迈克-蓬佩奥(Mike Pompeo)作为美国国务卿上任的最后一天,发表了一份新闻声明,指责中国对新疆维吾尔族人实施了 "持续的 "种族灭绝。该声明似乎引发了与国家有关的账户推特活动的急剧上升,其中许多推文直接提到了蓬佩奥。为了评估推文的活跃程度是否会对我们研究的协调度产生影响,我们计算了与图 1 相同的网络,这次我们将推文细分为两组:2021 年 1 月 19 日之前发布的推文(低活跃期)和之后发布的推文(高活跃期)。结果与整个两年期间观察到的结果保持一致。然而,蓬佩奥公开声明后,当国家相关推文活动达到顶峰时,国家相关账户之间的协调措施就更加明显。平均而言,协调得分显示标签网络增加了 4.36 倍,URL 网络增加了 1.47 倍,用户提及网络增加了 2.09 倍(图 2)。
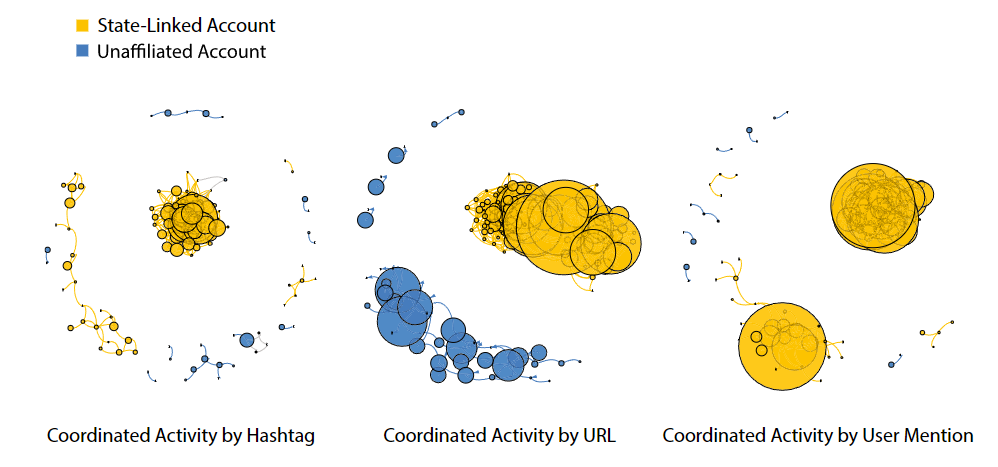
(图 1 账户之间的协调。如果一条边代表了一个与国家有关的账户和另一个与国家有关的账户之间的协调活动,则该边用黄色表示;如果协调活动是从一个无关联账户到一个无关联账户,则该边用蓝色表示;如果该边连接了不同类别的账户,则该边用灰色表示。节点的大小按账户施加的总 "影响力 "缩放。网络采用 Fruchterman-Reingold 布局,使相邻节点物理上相互靠近。(在线彩图))
6 Discussion
分析网络动态似乎有望成为一种检测机制,用于发现操作系统网络上的明确策划活动。在本文中,我们使用影响力模型来描述参与讨论维吾尔族和/或新疆(中国西北部维吾尔族聚居的自治区)的账号之间的关系。我们希望在更大范围的信息运营数据集上进行同样的分析。Twitter 已经发布了数十个数据集,其中包含来自 40 多个国家相关信息业务的账户和推文。我们很想知道我们的模型在这些范围广泛的活动中表现如何。
此外,我们还计划探索如何以新的方式使用最新的统计方法来揭示协调活动的网络动力学。例如,非线性 "因果 "分析和子图检测研究最近取得了进展(Wang 等,2018 年)。与本文提出的方法类似,帖子活动被视为一种观察到的行为,帖子行为等动态特征可能会被证明有助于检测隐藏的子图,如状态关联行为者网络。
7 Conclusion
我们相信,这项工作是检测协调信息操作的一种独特方法,它植根于一个经过充分研究的模型,具有广泛的实用性。我们展示了所提出的方法如何在无法访问用户信息、帖子内容或底层网络结构的情况下,成功地将参与真实世界信息操作的状态关联账户与非关联 Twitter 用户区分开来。仅考虑网络动态,就有可能减轻因 OSN 上的内容审核而产生的潜在隐私和偏见问题。此外,网络动态还能揭示隐藏在协调的不真实活动背后的影响,而这些影响大多无法从标准的网络社会影响力衡量标准中辨别出来。
这篇关于论文阅读 - Hidden messages: mapping nations’ media campaigns的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)