本文主要是介绍股票指数信息采集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中证指数有限公司数据采集
直接上代码
__author__ = 'Luzaofa'
__date__ = '2019/4/25 21:18'import re
import time
import requests
import logging
import configparser
import pandas as pd
from requests.exceptions import RequestExceptionclass Config(object):'''解析配置文件'''def get_config(self, lable, value):cf = configparser.ConfigParser()cf.read("CONFIG.conf")config_value = cf.get(lable, value)return config_valueclass Spider(Config):def __init__(self):self.url = 'http://www.csindex.com.cn/zh-CN/indices/index?page={page}&page_size=5000&by=asc&order=%E5%8F%91%E5%B8%83%E6%97%B6%E9%97%B4&data_type=json&class_2=2'self.type = '_0.CNSHS'def log(self, fileName, mass):'''日志'''logging.basicConfig(filename=fileName, format='%(asctime)s - %(levelname)s - %(message)s', level=logging.INFO)logging.info(mass)def get_response(self, url):'''给出url,获取网页响应'''try:response = requests.get(url)response.encoding = 'unicode-escape'return response.textexcept RequestException:return Nonedef get_list_value(self, response):'''利用正则匹配,发送请求,获取整页源代码'''pattern = re.compile(r'index_code":"(.*?)",.*?indx_sname.*?".*?"(.*?)",.*?\}', re.S)item = pattern.findall(response)return itemdef logic(self, args):'''业务逻辑(单个任务逻辑模块)'''all_index = []for page in range(1, 7):url = self.url.format(page=page)response = self.get_response(url)values = self.get_list_value(response)for value in values:# all_index.append([value[1], value[0]]) # 简称,代码all_index.append(['%s%s' % ((value[0]), self.type)]) # 代码_0.CNSHSprint('正在采集第:%s页,一共:%s条数据' % (page, len(values)))print(all_index)print(len(all_index))df = pd.DataFrame(all_index)df.to_csv('sh.csv', index=False, header=None)def main(self):'''主入口:return:'''start = time.time()pros = [1] # 任务池self.logic(pros) # 普通处理end = time.time()print('业务处理总耗时:%s 秒!' % (end - start))if __name__ == '__main__':print('Start!')demo = Spider()demo.main() # 普通print('END')效果图如下:

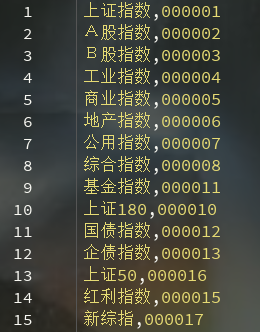
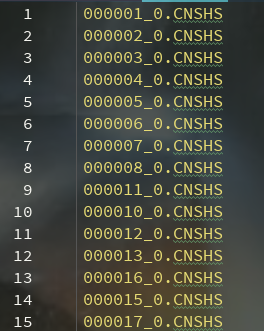
最近很忙,代码就不做解释了,晚上朋友们!
这篇关于股票指数信息采集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






