本文主要是介绍由论文写作到知识教育传承,智者善用,扶AIGC踏新程!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在学术领域中,诚信是不可动摇的基石。但是,令人震惊的事件发生了,竟有学术论文作者将ChatGPT上操作按钮的短语「Regenerate Response」毫无保留地援引到自己的论文中,更令人惊讶的是,审稿编辑竟然未能察觉这一事实,这导致了该论文被轻松发表。这个谜一般的事件始于一篇数学论文,一篇严格经过同行评审的论文。那么,这究竟是偶然现象,还是一种趋势?其中隐藏的秘密相信足以引发我们对学术未来乃至社会内容生产的重新审视。
上月中旬,美国Physica Scripta(论文期刊)发布了一篇意在寻找复杂数学方程新解的论文,看似寻常的论文,却在第三页意外地发现了一个引人注目的现象:文章中竟出现了类似ChatGPT的「Regenerate Response」。出版商的同行评审和诚信负责人联系作者后确认,他在起草手稿时使用了ChatGPT。令人意外的是,在之前的论文提交、5月的修改版本、7月的最终提交,以及后续的排版中都没有发现这样的异常。目前出版商已经决定撤回这一论文,理由是作者提交时没有声明使用了该工具,这一行为违反了他们的道德政策。

(该论文中的「Regenerate Response」)
这并非孤立事件。根据pubpeer(一个讨论和质疑学术期刊上发表的论文的网站)的不完全统计,过去四个月内,已经有十几篇论文中出现了类似「Regenerate Response」或「As an AI language model, I…」的短语,引发了广泛关注。
AI代写论文的这些现象引发了大众对论文写作和知识教育的深刻反思。论文写作、发表在世界上大多数国家的知识教育界中往往被作为学位、职称、教职评定的重要依据。这些现象除了体现学术诚信的老问题,也让人们担忧,如果在校的大学生都如此使用ChatGPT此类AI大语言模型工具撰写课程论文乃至学位论文,是不是也能成功过关呢?被誉为人类教育的知识殿堂的大学是否会因AIGC的出现而被涂污?这是身处AIGC时代的我们必须进行思考的问题。

(大学生滥用AI工具成为高等教育难题)
在现代社会,学术写作一直是知识传承与创新的核心。在传统学术写作中,研究者们花费大量时间搜集资料、分析数据、构思论文结构。AI文本生成工具的出现将这一切变得更加高效。它能够自动检索海量文献,找出关键信息直至完全生成论文。比如,在医学领域,研究者们可以借助AI工具分析大规模的医学数据,自动生成论文的数据分析部分,大大提高了研究的效率。这种全新的写作体验,为学者们提供了更多的可能性。

(AI文本生成工具让学者写作论文不至于书海淘金)
另外,学术写作被认为是创作者的独特表达和思考,但现在,“AIGC版论文”引发了原创性的争议。据了解,AI文本生成工具非常受学生们喜爱,因为只需要几行提示,它就可以生成从论文到数学计算的任何东西,随之而来的剽窃和作弊行为引发了教育界的担忧。在学术诚信方面,“AIGC版论文”如何确保其原创性?这需要我们深入思考,并建立相应的伦理标准,以确保AIGC技术在发展中不迷失方向,更好地服务人类社会。同时,“AIGC版论文”因为其合理性和逻辑性,有时甚至难以辨别是否为机器生成。为此,今年9月7日,联合国教科文组织发布了首份关于在教育中使用生成式人工智能(AIGC)的指南。在这份长达64页的指南报告中,教科文组织强调了政府批准人工智能课程的必要性,包括在学校教育、职业技术教育和培训中设置相关规范使用课程。教科文组织还表示:“生成式人工智能的提供者应该负责确保遵守核心价值观和合法目的,尊重知识产权,坚持道德实践……人们通过观察真实世界、通过实验探讨等实践经验,以及通过独立逻辑推理来发展认知能力和社交技能,而生成式人工智能有可能会剥夺人们发展这些能力的机会。”
今年是几几年?2023年吗?错!今年是“天临五年”,2019年的翟天临论文剽窃事件让中国政府各级高等教育部门对大学各层次毕业生的毕业论文审查政策进一步收紧。苦不堪言的大学生便戏称2019年为“天临元年”,依此类推。正在经历AI飞速发展的中国,相关政府部门也开始针对AI代写论文问题制定相应规则。今年8月28日,《中华人民共和国学位法(草案)》提请十四届全国人大常委会第五次会议审议。草案规定:学位论文或者实践成果存在抄袭、剽窃、伪造、数据造假、人工智能代写等学术不端行为的,经学位评定委员会审议决定,由学位授予单位撤销学位证书。
正是在AIGC带来的挑战中,我们看到了机遇的蛛丝马迹。AIGC使得学术、教育界开始更加重视人类独特的思维方式和创造力;政府管理界也开始引导AIGC技术更好地为社会教育、知识生成服务。借此,我们可以更好地培养学生等论文作者的创新思维,让他们不仅仅是信息的接收者,更是问题的解决者,创新的发起者。
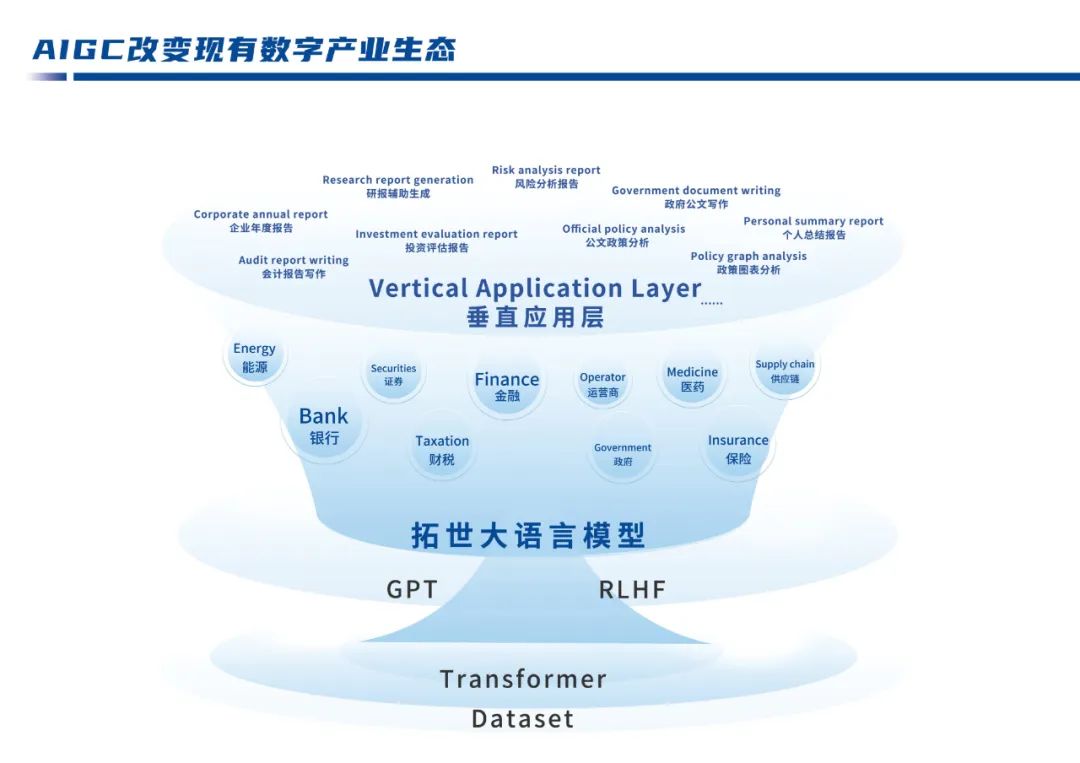
(大模型应用,未来可期)
AI在知识教育界中,既是过去智慧的传承者,又是未来知识创新的引领者。面对挑战,我们需要更具智慧地引导这项技术,使其成为学术研究、学习教育的助推器,而不是束缚者。AIGC+学术论文写作仅仅是其未来发展的冰山一角,以大模型为基座的AI工具可胜任如此繁杂的学术写作,应用到其它产业生态又有何阻碍呢?期待AI在明天的发展中,真正服务于人类的创造性和智慧性,不断探索未知的边界。因为,“世之奇伟、瑰怪,非常之观,常在于险远。”
这篇关于由论文写作到知识教育传承,智者善用,扶AIGC踏新程!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









