本文主要是介绍STM32F10xx 存储器和总线架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、系统架构
在小容量、中容量和大容量产品 中,主系统由以下部分构成:
- 四个驱动单元 :
-
Cotex-M3内核、DCode总线(D-bus)和系统总线(S-bus)
-
通用DMA1和通用DMA2
-
- 四个被动单元
-
内部SRAM
-
内部闪存存储器
-
FSMC
-
AHB到APB的桥(AHB2APBx),它连接所有的APB设备
-
这些都是通过一个多级的AHB总线结构 相互连接的,如下图图1所示:
图1 系统架构
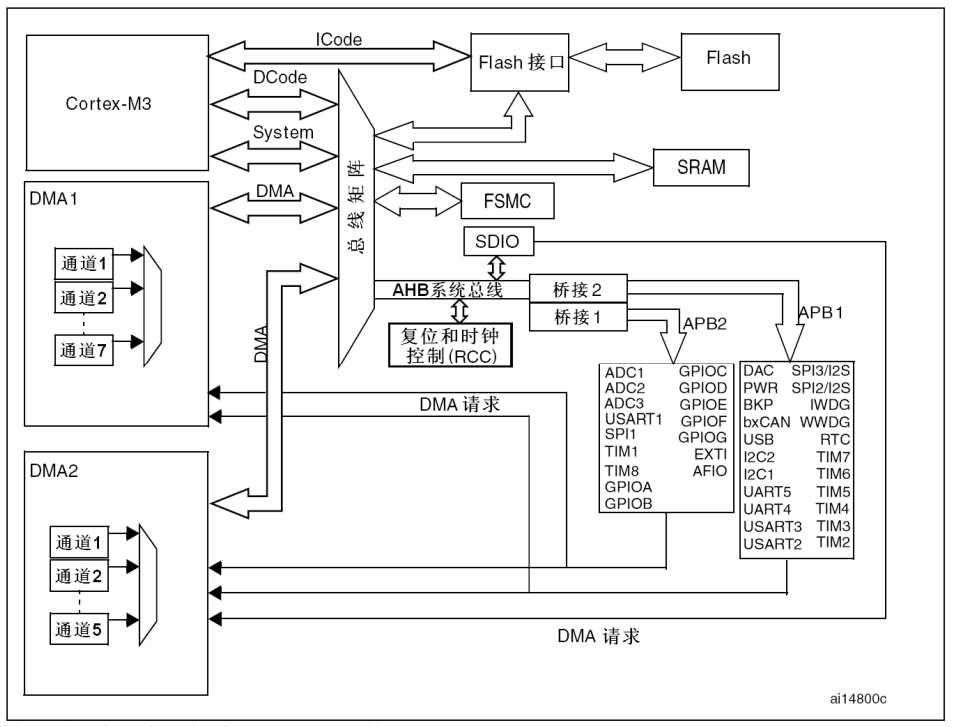
在互联性产品 中,主系统由以下部分构成:
- 五个驱动单元
-
Cotex-M3内核、DCode总线(D-bus)和系统总线(S-bus)
-
通用DMA1和通用DMA2
-
以太网DMA
-
- 三个被动单元
-
内部SRAM
-
内部闪存存储器
-
AHB到APB的桥(AHB2APBx),它连接所有的APB设备 这些都是通过一个多级的AHB总线结构 相互连接的,如下图图2所示
-
图2 互联型产品系统架构

1.1 ICode总线
该总线将Cortex-M3内核的指令总线与闪存指令接口相连接。指令预取 在此总线上完成。
1.2 DCode总线
该总线将Cortex-M3的内核的DCode总线与闪存存取器的数据接口相连接(常量加载和调试访问)。
1.3 系统总线
此总线连接Cortex-M3内核的系统总线(外设总线)到总线矩阵,总线矩阵协调着内核和DMA间的访问。
1.4 DMA总线
此总线将DMA的AHB主控接口和总线矩阵相联,总线矩阵协调着CPU的DCode和DMA到SRAM、闪存和外设的访问。
1.5 总线矩阵
总线矩阵协调内核系统总线和DMA主控总线之间的访问仲裁,仲裁利用轮换算法 。在互联型产品中,总线矩阵包含5个驱动部件(CPU的DCode、系统总线、以太网DMA )和3个从部件(闪存存储器接口(FLITF)、SRAM和AHB2AP桥)。在其他产品中总线矩阵包含4个驱动部件(CPU的DCode、系统总线、DMA1总线和DMA2总线)和4个被动部件(闪存存储器接口(FLITF)、SRAM、FSMC 和AHB2APB桥)。AHB外设通过总线矩阵与系统总线相连允许DMA访问。
1.6 AHB/APB桥(APB)
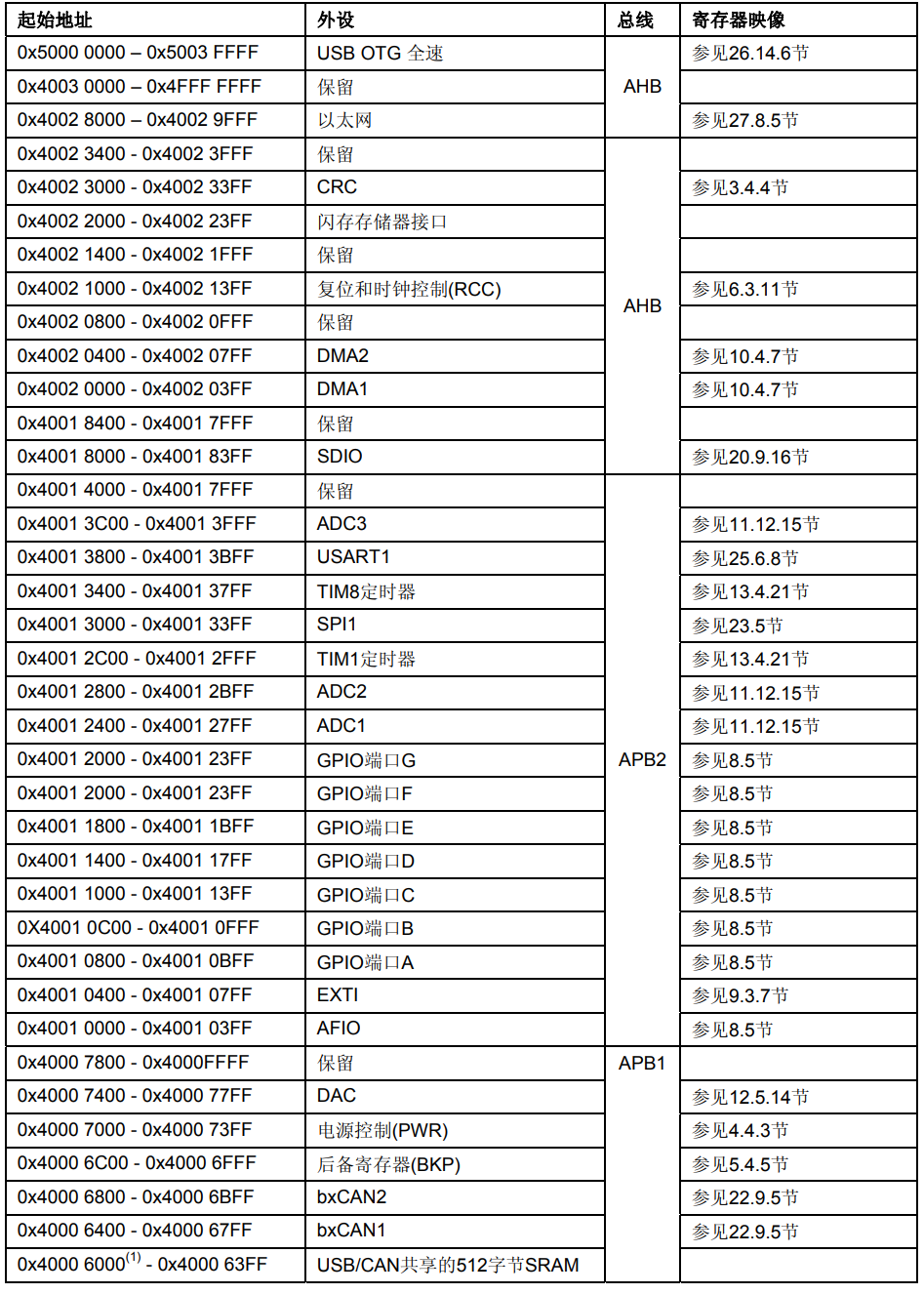
两个AHB/APB桥在AHB和两个APB总线间提供同步连接。APB1操作速度限于36MHz,APB2操作于全局(最高72MHz)。 有关连接到每个桥的不同外设的地址映射请参考表1。
在每一次复位之后,所有除SRAM和FLITF以外的外设都被关闭,在使用一个外设之前,必须设置寄存器RCC_AHBENR来打开该外设的时钟。
注意 :当对APB寄存器进行8位或者16位访问时,该访问会被自动转换成32位的访问:桥会自动将数据扩展以配合32的向量。
二、储存器组织
程序存储器、数据存储器、寄存器和输入输出端口被组织在同一个4GB 的线性地址空间内。数据字节以小端格式存放在存储器中。一个字里的最低地址被认为是该字的最低有效字节,而最高地址字节是最高有效字节。
可访问的存储器被分成8个主要块 ,每个块为512MB。
其他所有没有分配给片上存储器和外设的存储器空间都是保留的地址空间。
三、存储器映像
请参考相应器件的数据手册中的存储器映像图。表1列出了所用STM32F10xxx中内置外设的起始地址 。
表1 寄存器组起始地址

3.1 嵌入式SRAM
STM32F10xx内置64K字节的静态SRAM。它可以以字节、半字(16位)或全字(32位)访问。SRAM的起始地址是0x2000 0000 。
3.2 位段
Cortex-M3存储器映像包括两个位段(bit-band)区 。这两个位段区将别名存储器 区的每个字映射到位段存储区 的一个位,在别名存储区写入一个字具有对位段区的目标位执行读-改-写操作的相同效果。
在STM32F10xx里,外设存储器和SRAM都被映射到一个位段区里,这允许执行单一的位段的写和读操作。 下面的映射公式给出了别名区中的每个字是如何对应位段区的相应位的:
bit_word_addr = bit_band_band + (byte_offset × 32) + (bit_number × 4)
其中:
bit_word_addr是别名存储区中字的地址,它映射到某个目标位。
bit_band_base是别名区的起始地址。
byte_offset是包含目标位的字节在位段里的序号。
bit_number是目标位所在地址(0-31) 例子 : 下面的例子说明如何映射别名区中SRAM地址为0x20000300的字节中的位2:
0x22006008 = 0x22000000 + (0x300 × 32) + (2 × 4)
对0x22006008地址的写操作于对SRAM中地址0x20000300字节的位2执行读-改-写操作有着相同的效果。 读0x22006008地址返回SRAM中地址0x20000300字节的位2的值(0x01或0x00)。
3.3 嵌入式内存
高性能的闪存模块有以下的主要特征:
- 高达512字节闪存存储器结构:闪存存储器有主存储块 和信息块 组成
- 主存储块容量
-
小容量产品主存储块最大为4k×64位,每个存储块划分为32个1K字节的页(见表2)。
-
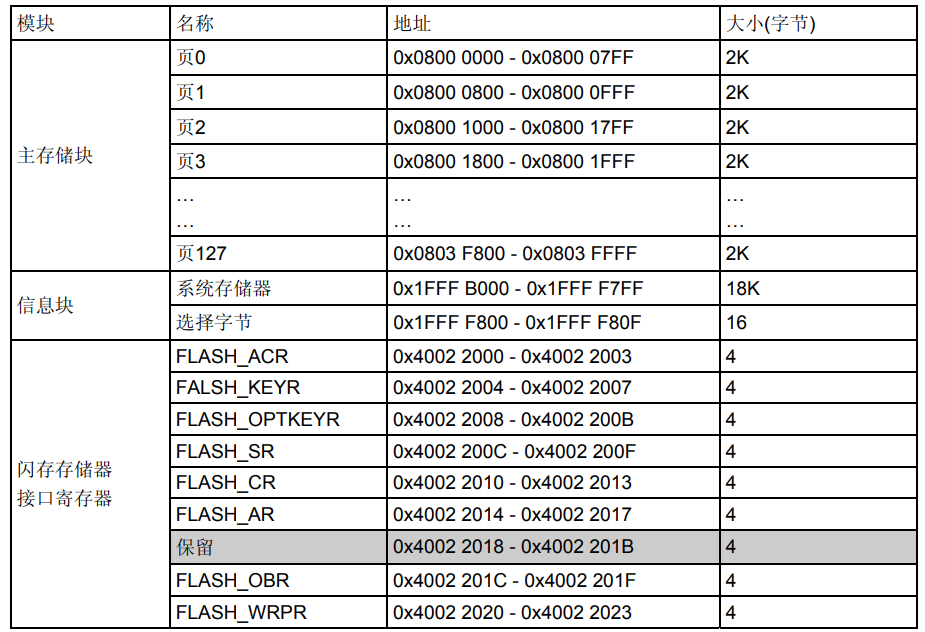
中容量产品主存储块最大为16K×64位,每个存储块划分为128个1K字节的页(见表3)。
-
大容量产品主存储块最大为64K×64位,每个存储块划分为256个2K字节的页(见表4)。
-
互联型产品主存储块最大为32K×64位,每个存储块划分为128个2K字节的页(见表5)。
-
- 信息块容量
-
互联型产品有2360×64位(见表5)。
-
其他产品有258×64位(见表2、表3、表4)。 闪存存储器接口的特性为:
-
- 主存储块容量
-
带预期缓冲器 的读接口(每字为2才64位)
-
选择字节加载器
-
闪存编程/擦除操作
-
访问/写保护
表2 闪存模块的组织(小容量产品)

表3 闪存模块的组织(中容量产品)
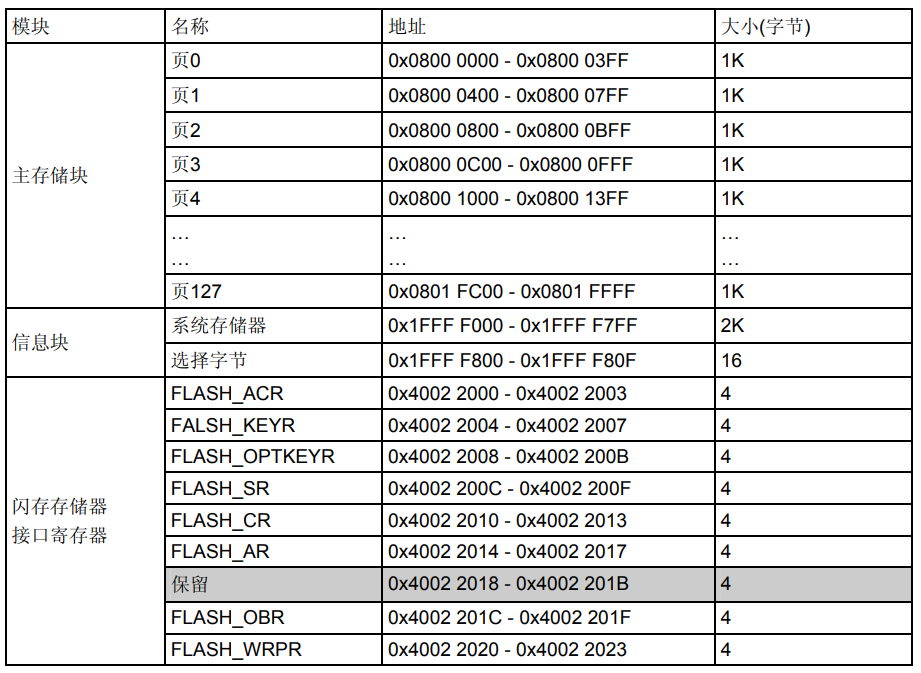
表4 闪存模块的组织(大容量产品)

表5 闪存模块的组织(互联型产品)
3.3.1 闪存读取
闪存的指令和数据访问是通过AHB总线完成。预取模块是用户通过ICode总线读取指令的。仲裁是作用在闪存接口,并且DCode总线上的数据访问优先。 读访问可以有以下配置选项:
-
等待时间:可以随时更改的用于读取操作的等待状态的数量。
-
预取缓冲区(2个64位):在每一次复位以后被自动打开,由于每个缓冲区的大小(64位)与闪存的带宽相同,因此只需通过一次读闪存的操作即可更新整个缓冲区的内容。由于预取缓冲区的存在,CPU可以工作在更高的主频。CPU每次取指最多为32位的字,取一条指令时,下一个指令已经在缓冲区中等待。
-
半周期:用于功耗优化
注:
-
这些选项与闪存存储器的访问时间一起使用。等待周期体现在系统时钟(SYSCLK)时钟与闪存访问时间的关系
-
0等待周期,当0<SYSCLK<24MHz
-
1等待周期,当24MHz<SYSCLK≤ 48MHz
-
2等待周期,当48MHz<SYSCLK≤ 72MHz
-
半周期配置不能与使用了预分频器的AHB一起使用,时钟系统应该等于HCLK时钟。该特性只能在时钟频率为8MHz或者低于8MHz时,可以直接使用内部RC振荡器(HSI),或者主振荡器(HSE),但不能用PLL。
-
当AHB预分频系数不为1时,必须置预取缓冲区处于开启状态。
-
只有在系统时钟(SYSCLK)小于24MHz并且没有打开AHB的预分频器(即HCLK必须等于SYSHCLK)时,才能执行预取缓冲器的打开和关闭操作。一般而言,在初始化过程中执行预取缓冲器的打开和关闭操作,这时微控制器的时候由8MHz的内部RC震荡器(HSI)提供。
-
使用DMA:DMA在DCode总线上访问闪存存储器,它的优先级比ICode上的取指高。DMA在每次传送完成后具有一个空余的周期。有些指令可以和DMA传输一起执行。
3.3.2 编程和擦除闪存
闪存编程一次可以写入16位(半字)。
闪存擦除操作可以按页面擦除或完全擦除(全擦除)。全擦除不影响信息块。
为了确保不发生过度编程,闪存编程和擦除控制器块是由一个固定的时钟控制的。
写操作(编程或擦除)结束时可以触发中断。仅当闪存控制器接口时钟开启时,此中断可以用来从WFI模块退出。
四、启动配置
在STM32F10xxx里,可以通过BOOT[1:0]引脚选择三种不同启动模式。
表6 启动模式
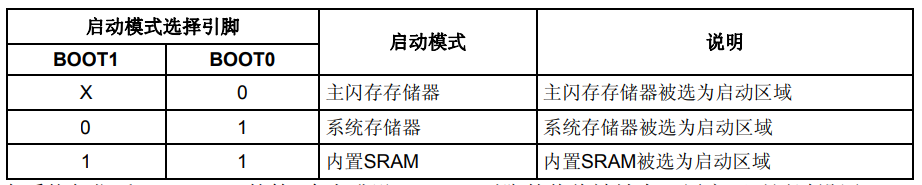
在系统复位后,SYSCLK的第4个上升沿,BOOT引脚的值将被锁存。用户可以通过设置BOOT1和BOOT0 引脚的状态,来选择在复位后的启动模式。
在从待机模式退出时,BOOT引脚的值将被重新锁存;因此,在待机模式下BOOT引脚应保持为需要的启动配置,在启动延迟之后,CPU从地址0x00000000获取堆栈顶的地址,并从启动存储器的0x00000004指示的地址开始执行代码。
因为固定的存储器映像,代码区使用从地址0x0000 0000开始(通过ICode和DCode总线访问),而数据区 (SRAM)始终从地址0x2000 0000开始(通过系统总线访问)。Cortex-M3的CPU始终从ICode总线获取复位向量,即启动仅适用于从代码区开始(典型地从Flash启动)。
STM32F10xxx微控制器实现了一个特殊的机制,系统不仅仅可以从Flash存储器或系统存储器启动,还可以从内置SRAM启动。
根据选定的启动模式,主闪存存储器、系统存储器或SRAM可以按照以下方式访问:
-
从主存存储器启动:主闪存存储器被映射到启动空间(0x0000 0000),但仍然能够在它原有的地址(0x0800 0000)访问它,即闪存存储器的内容可以在两个地址区域访问,0x0000 0000或0x0800 0000。
-
从系统存储器启动:系统存储器被映射到启动空间(0x0000 0000),但仍然能够在它原有的地址(互联型产品原有地址为0x1FFF B000,其它产品原有地址为0x1FFF F000)访问它。
-
从内置SRAM启动:只能在0x2000 0000开始的地址区访问SRAM。
注:当从内置SRAM启动,在应用程序的初始化代码中,必须使用NVIC的异常表和偏移寄存器重新映射向量表至SRAM中。
内嵌的自举程序
内嵌的自举程序存放在系统存储区,由ST在生产线上写入,用于通过可用的串行接口对闪存存储器进行重新编程。
-
对于小容量、中容量和大容量的产品而言,可以通过USART1接口启用自举程序。
-
对于互联型产品而言,可以通过以下某个接口启动自举程序:USART1、USART2(重映像的)、CAN2(重映像的)或USB OTG全速接口的设备模式(通过设备固件更新DFU协议)。USART接口依靠内部8MHz振荡器(HSI)运行。只有在外部使用8MHz、14.7456MHz或25MHz时钟(HSE)时,才能使用CAN或USB OTG接口。
一个专注于“嵌入式知识分享”、“DIY嵌入式产品”的技术开发人员,关注我,一起共创嵌入式联盟。

这篇关于STM32F10xx 存储器和总线架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







