本文主要是介绍信息学奥赛一本通 1339:【例3-4】求后序遍历 | 洛谷 P1827 [USACO3.4] 美国血统 American Heritage,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【题目链接】
ybt 1339:【例3-4】求后序遍历
洛谷 P1827 [USACO3.4] 美国血统 American Heritage
两题都是已知先序和中序遍历序列,求后序遍历序列
区别为:【ybt 1339】先输入先序遍历序列,再输入中序遍历序列。【洛谷 P1827】先输入中序遍历序列,再输入先序遍历序列。
【题目考点】
1. 二叉树
已知先序、中序边路序列,求后序遍历序列
【解题思路】
解法1:
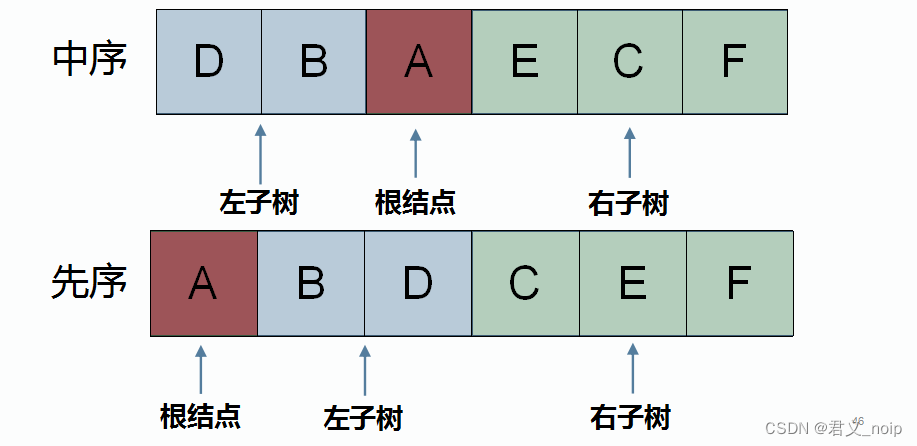
假设输入的中序遍历序列为:DBAECH,先序遍历序列为ABDCEF。以该输入为例讨论问题解法。
当前要解决的问题是:已知先序、中序遍历序列,构建二叉树。
- 首先先序遍历中第一个字母为树的根结点的值(A)。
- 而后在中序遍历序列中找到根结点值(A)的位置,根结点值左边的序列(DB)是根结点的左子树的中序遍历序列。根结点值右边的序列(ECF)为根结点的右子树的中序遍历序列。
- 在先序遍历序列中根据左子树中序遍历序列的长度,找到左子树的先序遍历序列(BD),及右子树的先序遍历序列(CEF)。
- 递归调用“已知先序中序遍历序列求二叉树”的函数。现在已知根结点的左子树、右子树的先序、中序遍历序列,那么就可以构建出根结点的左子树与右子树(构建子树相对于构建以A为根结点的树,是小规模问题,递归求解大规模问题时,小规模问题的解被视为是已知的)
- 以A为根结点,接上构造好的左右子树,即完成了树的构建。
接下来对这棵树做后序遍历,即可得到树的后序遍历序列。
写法1:使用字符数组
输入先序遍历序列到s_pre,中序遍历序列到字符数组s_in。
函数createTree需要传入ml,mr,pl,pr,意为:由先序序列s_pre[pl]~s_pre[pr]与中序序列s_in[ml]~s_in[mr]构造一棵二叉树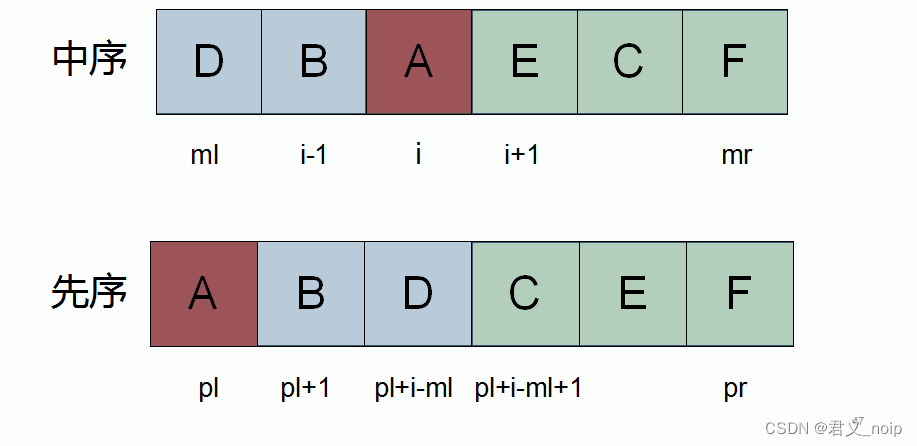
根据上述算法,先在中序序列中找到先序序列第一个字符s_pre[pl]的位置,找到位置为i。那么左子树的中序遍历序列为s_in[ml]~s_in[i-1],长度为i-ml,在先序遍历序列中,从pl+1开始取长为i-ml的序列,最后一个元素的位置为pl+i-ml,那么左子树的先序遍历序列为s_pre[pl+1]~s_pre[pl+i-ml]。类似地,可以得到右子树的中序序列为s_in[i+1]~s_in[mr],先序序列为s_pre[pl+i-ml+1]~s_pre[pr]。
使用createTree分别生成左右子树,接在新分配出来的根结点的下面,就得到了这棵树。
递归出口为:先序与中序序列的下标范围一定有pl<=pr且ml<=mr,如果不满足这一条件,序列范围无意义,应该返回。
写法2:使用string类
思路与上述方法类似,不再赘述。
使用string类,可以使用substr成员函数来取子串。每次传入函数的先序、中序序列都是string类对象。
【题解代码】:ybt 1339:【例3-4】求后序遍历
写法1:使用字符数组
#include <bits/stdc++.h>
using namespace std;
#define N 1005
struct Node
{char val;int left, right;
};
Node node[N];
int p;
char pre_s[105], mid_s[105];
//由先序遍历序列pre_s[pl]~pre_s[pr]与中序遍历序列mid_s[ml]~mid_s[mr]构建二叉树,返回根结点地址
int createTree(int pl, int pr, int ml, int mr)
{if(pl > pr || ml > mr)return 0;int np = ++p, i;node[np].val = pre_s[pl];//pre_s[pl]一定是根结点的值 for(i = ml; i <= mr; ++i)if(mid_s[i] == pre_s[pl])//找到根结点在中序序列中的下标为i break;node[np].left = createTree(pl + 1, pl + i - ml, ml, i - 1);node[np].right = createTree(pl + i - ml + 1, pr, i + 1, mr);return np;
}
void postOrder(int root)
{if(root == 0)return; postOrder(node[root].left);postOrder(node[root].right);cout << node[root].val;
}
int main()
{cin >> pre_s >> mid_s;int len_pre = strlen(pre_s), len_mid = strlen(mid_s);int root = createTree(0, len_pre - 1, 0, len_mid - 1);postOrder(root);return 0;
}写法2:使用string类
#include <bits/stdc++.h>
using namespace std;
#define N 1005
struct Node
{char val;int left, right;
};
Node node[N];
int p;
string s_pre, s_in;
int createTree(string sp, string si)//用先序序列sp与中序序列si构建二叉树,返回树根
{int np = ++p, i;node[np].val = sp[0];for(i = 0; i < si.length(); ++i)if(sp[0] == si[i])break;int len_l = i, len_r = si.length() - 1 - i;//左右子树序列长度 if(len_l > 0)//序列长度大于0,才可以建立一棵树 node[np].left = createTree(sp.substr(1, len_l), si.substr(0, len_l));if(len_r > 0)node[np].right = createTree(sp.substr(i+1, len_r), si.substr(i+1, len_r));return np;
}
void postOrder(int root)
{if(root != 0){postOrder(node[root].left);postOrder(node[root].right);cout << node[root].val;}
}
int main()
{cin >> s_pre >> s_in;int root = createTree(s_pre, s_in);postOrder(root);return 0;
}
【题解代码】:洛谷 P1827 [USACO3.4] 美国血统 American Heritage
写法1:使用字符数组
#include <bits/stdc++.h>
using namespace std;
#define N 1000
struct Node
{char val;int left, right;
};
Node node[N];
int p = 1;
char s_pre[105], s_in[105];//s_pre:先序遍历序列 s_in:中序遍历序列
//由先序序列s_pre[pl]~s_pre[pr]与中序序列s_in[ml]~s_in[mr]构造一棵二叉树,返回根结点
int createTree(int pl, int pr, int ml, int mr)
{if(pl > pr || ml > mr)return 0;int np = p++, i;node[np].val = s_pre[pl];for(i = ml; i <= mr; ++i){if(s_in[i] == s_pre[pl])break;}node[np].left = createTree(pl + 1, pl + i - ml, ml, i - 1);node[np].right = createTree(pl + i - ml + 1, pr, i + 1, mr);return np;
}
void postOrder(int root)
{if(root != 0){postOrder(node[root].left);postOrder(node[root].right);cout << node[root].val;}
}
int main()
{cin >> s_in >> s_pre;int root = createTree(0, strlen(s_pre) - 1, 0, strlen(s_in) - 1);postOrder(root);return 0;
}
写法2:使用string类
#include <bits/stdc++.h>
using namespace std;
#define N 1000
struct Node
{char val;int left, right;
};
Node node[N];
int p = 1;
string s_pre, s_in;
int createTree(string sp, string si)//用先序序列sp与中序序列si构建二叉树,返回树根
{int np = p++, i;node[np].val = sp[0];for(i = 0; i < si.length(); ++i){if(sp[0] == si[i])break;}int len_l = i, len_r = si.length() - 1 - i;//左右子树序列长度 if(len_l > 0)//序列长度大于0,才可以建立一棵树 node[np].left = createTree(sp.substr(1, len_l), si.substr(0, len_l));if(len_r > 0)node[np].right = createTree(sp.substr(i+1, len_r), si.substr(i+1, len_r));return np;
}
void postOrder(int root)
{if(root != 0){postOrder(node[root].left);postOrder(node[root].right);cout << node[root].val;}
}
int main()
{cin >> s_in >> s_pre;int root = createTree(s_pre, s_in);postOrder(root);return 0;
}
这篇关于信息学奥赛一本通 1339:【例3-4】求后序遍历 | 洛谷 P1827 [USACO3.4] 美国血统 American Heritage的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!