本文主要是介绍LANCER : A Lifetime-Aware News Recommender System阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
🎯基本信息
🎯研究背景
🎞️研究内容
🚩研究方法
🚩实验分析
✅研究总结
💡创新点
✅未来研究方向
👀个人总结
🎯基本信息
📋标题:
LANCER: A Lifetime-Aware News Recommender System
🎓作者:Bae Hong-Kyun,Ahn Jeewon,Lee Dongwon,Kim Sang-Wook🗓️出版期刊和年份:AAAI-2023📍影响因子:
作者单位:
Department of Computer Science, Hanyang University, South Korea 2 College of Information Sciences and Technology, The Pennsylvania State University, USA

💭引用:
Bae, H.-K., Ahn, J., Lee, D. & Kim, S.-W. LANCER: A Lifetime-Aware News Recommender System. doi:10.1609/aaai.v37i4.25530.
🌟关键词:新闻推荐、生命周期、深度学习模型、有限竞争
🎯研究背景
研究的出发点:观察发现用户阅读新闻时往往不会点击过时的新闻。
-
根据这个提出新闻“life time”的概念和两个假设。
之前研究存在的不足:没有在新闻推荐考虑新闻的生命周期的概念。
-
在训练模型和向用户推荐新闻时没有考虑新闻的生命周期:它们没有考虑新闻之间的竞争来推断用户对新闻的偏好,也没有在推荐时考虑新闻的剩余生命周期。
-
2014年就有研究提出在新闻推荐中使用生命周期的概念,但是忽略了新闻只有与其他有重叠生命周期的新闻竞争才能被用户点击的特性。
🎞️研究内容
(1)通过观察提出新闻"生命周期"的概念,和两个假设:( i )新闻的生命期比其他类型的物品(如电影或电子商务产品)更短;( ii )为了获得用户的点击,新闻只与其他生命期未结束的实时新闻竞争,并且这些新闻的生命周期存在重叠(即有限竞争)。
(2)提出了一种新的新闻推荐方法,即生命周期感知新闻推荐系统LANCER,在训练和推荐过程中充分利用新闻的生命周期。
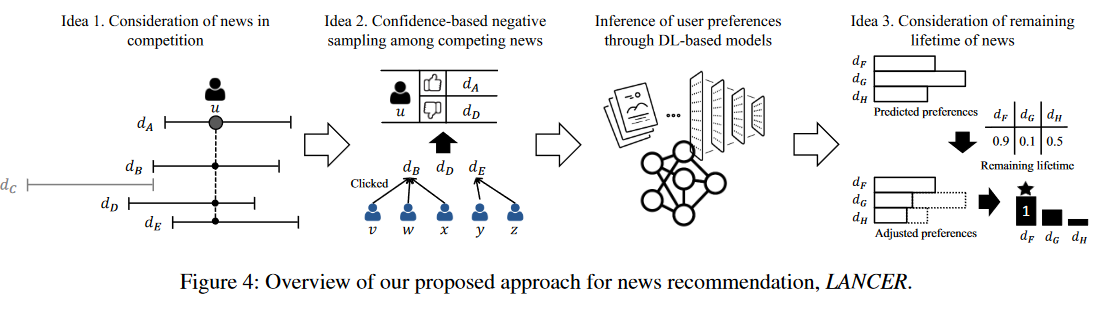
LANCER三个关键思想:
-
在竞争中考虑新闻:基于新闻的生命期,我们确定用户点击的新闻(正面新闻)比其它未被点击的新闻(负面新闻)更受用户青睐,后者的生命周期存在重叠(有限竞争)。
-
竞争新闻中的基于置信度的负采样:公户未点击的新闻中和正面新闻存在重叠周期。可以估计新闻的受欢迎程度的置信度来发现真正的负面新闻。例如,我们假设当不受欢迎的新闻没有被点击时,它更有可能是真正的负面新闻,因为用户可能不喜欢它。
-
考虑新闻剩余的生命周期:为了避免推荐生命期已经结束或快结束的新闻,通过考虑新闻剩余的生命周期来调整对新闻的预测偏好分数。通过这种调整,我们可以推荐具有预测偏好分数高和剩余生命期长的新闻。
(3)成功地证明了最新的新闻推荐模型可以通过整合生命周期的概念和LANCER获得显著增益。
🚩研究方法
(1)概念定义:
-
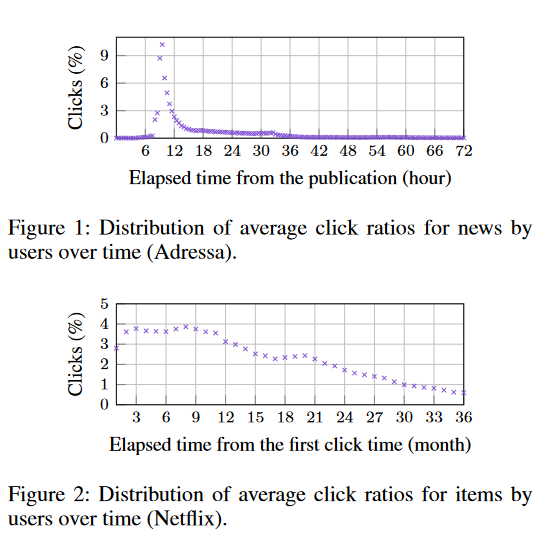
新闻的生命周期:从初始发布时间到最后点击时间,相对较短(几个小时)
-
有限竞争:新闻只与其他生命期未结束的且有时间重叠的新闻竞争,而不是和所有的新闻竞争。基于这些竞争训练的新闻推荐模型可以从中获益。
新闻数据集和电影/戏剧数据集的点击率对比
-
36hours vs 36 months
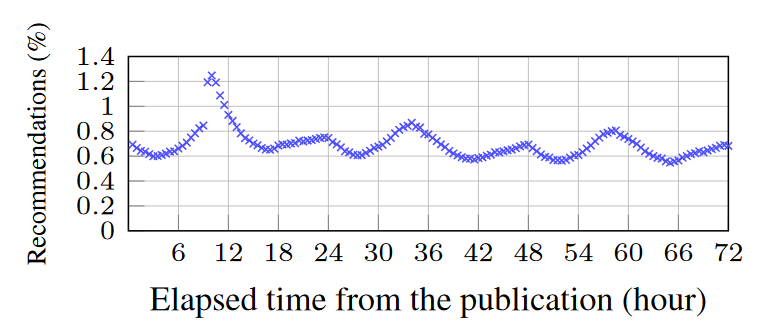
NRMS推荐新闻的发布时间统计
在新闻发布48h后依旧进行推荐,造成了推荐的浪费
(2)LANCER框架概述
1)考虑有时间重叠的新闻集(里面的新闻是竞争关系)并根据用户的点击分类 positive negative
-
例如:c没有重叠就不考虑
-
通过对新闻时间取交集来确定时间是否重叠
-
Finding news in competition with each other
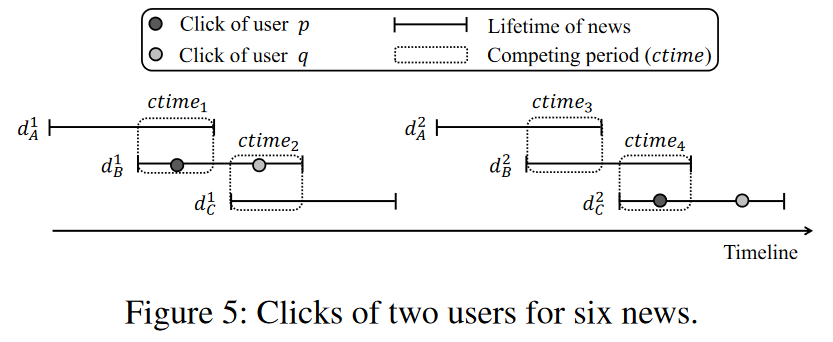
-
Determining the positive/negative news
将用户点击的新闻视为她的positive。将她在与positive新闻竞争期间没有点击的新闻确定为她的negative。
例如:在ctime1期间,用户p只点击了d1B,因此,d1B和d1A分别被视为p的positive、negative新闻。
“B > A and C > B for p, thus C > B > A for p; B > C for q” “existing studies, the order of B = C > A”
之前研究存在问题:错误的排序、将无法判断的新闻分类错误negative
2)将不太流行的新闻即使置信度高(dD)也判定为用户u的negative。
-
Confidence-based Negative Sampling among Competing News
提出原因:部分没有点击的新闻不是用户不喜欢而是没有意识到它的存在。
目标:对未点击的新闻进行抽样,这些新闻可以确信是用户的负面新闻和相应的正面新闻
确定置信度:给用户未点击的新闻置信度,流行度越低,则相应的置信度越高
di、dj分别为用户u的正负新闻,pop(u,di,dj)指在用户u点击di前其他用户点击di的竞争新闻dj的总数
未来工作:流行度预测方法例如基于DL的模型(注意力网络)也可以独立地应用到我们的LANCER方法中,以确定对负新闻的置信度。
3)通过基于DL的模型NRMS对前面确定的positive/negative新闻训练来预测用户的偏好
-
Training the DL-based models
使用已有的深度模型NRMS、CNE-SUE进行训练。并使用下面的损失函数进行优化
4)考虑新闻的剩余生命周期对用户的偏好分数进行调整。(原本推荐dG,调整后推荐dF)
-
Consideration of Remaining Lifetime
利用sigmoid函数根据新闻的剩余生命周期降低用户的偏好分数。
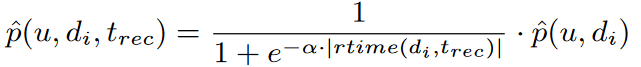
🚩实验分析
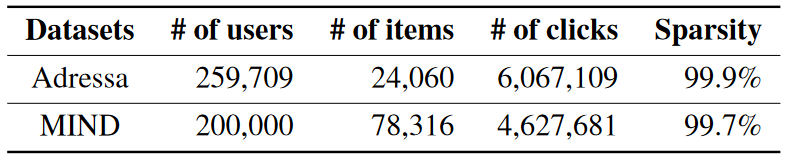
数据集:MIND、Adressa
评估指标:AUC、MRR、NDCG
基准模型:NRMS (2019); LSTUR (2019); NAML (2019); CNE-SUE (2021).
实验结果:
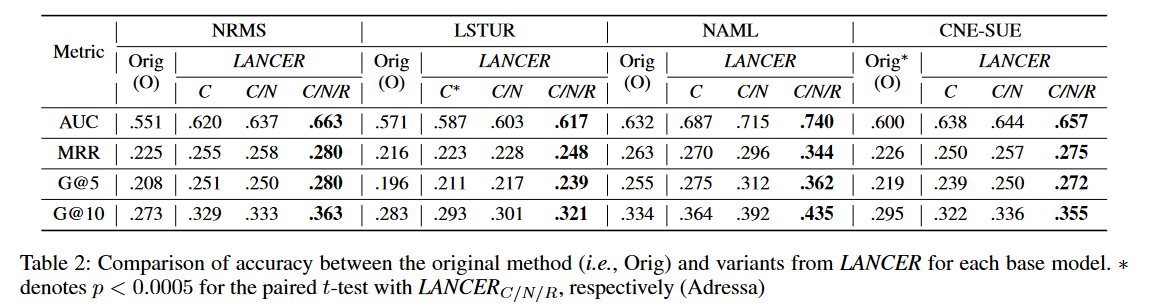
Adressa:
MIND:

实验一:通过有限竞争来确定用户的负面新闻的有效性。
实验设计:设计了变体LANCERc,即只从与相应正面新闻有竞争关系的非点击新闻集中随机采样每个用户的K条非点击新闻。将其与原始方法(即Orig)进行了比较,后者在每个基础模型中都会随机采样每个用户的K条非点击新闻,而不考虑其生命周期。Imp样本从相应的正面新闻印象日志中随机抽取每个用户的K条非点击新闻。
实验结论:
-
在两个数据集上,配备LANCERc的模型优于原始模型,说明了通过有限竞争来确定用户的负面新闻可以提高模型的性能。
-
配备Imp的模型显示出比Orig更低的准确率,这表明从印象日志中通过负采样来训练模型对于推断用户偏好几乎是无效的。
实验二:采用了基于流行度的置信度对于负采样的有效性。
实验设计:设计LANCERC / N变体,通过赋予低流行的负新闻高概率来对负新闻采样。变体LANCERC/(1−N)通过赋予高流行的负新闻高概率来对负新闻采样。
实验结论:
-
-
LANCERC/N > LANCERC > LANCERC/(1−N)
-
-
提出的基于置信度的负采样可以提高推荐性能
平滑值使用的有效性
-
实验设计:RAW不使用任何平滑函数;SQRTs使用平方根作为平滑值(平滑效果低于log函数);LOG:使用log平滑函数
实验结论:

由于新闻之间流行度的严重差异,在计算基于流行度的新闻置信度时,使用适当的平滑值是必要的。
实验三、考虑新闻剩余生命周期对于预测偏好的有效性
实验设计:LANCERC/N/R集合了提出的三个关键思想。
实验结论:
-
LANCERC/N/R > LANCERC/N
-
说明综合考虑新闻的剩余生命周期是有效的
利用配备两个变体(即LANCERC / N和LANCERC / N / R)dCNE-SUE给每个用户推荐top-1新闻,并调查每个对应新闻的剩余生命期。

结论:提出的整合所有想法的LANCERC/N/R有利于推荐具有高度预测偏好和足够剩余生命周期的新闻。
实验四、参数α的值对推荐性能的影响
参数α决定思想3中的调整程度实验结论:
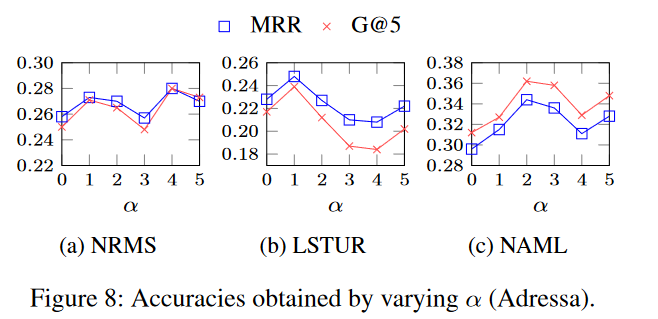
实验结论:
-
较小的α值显著降低了剩余生命周期较小的新闻的预测偏好
-
α = 0.4,α = 0.1和α = 0.2分别是NRMS,LSTUR和NAML的最佳性能
✅研究总结
本文利用新闻领域的生命周期特征:( i )新闻的生命周期比电影或电子商务产品的生命周期相对较短;( ii )新闻只与其他生命期未结束的新闻竞争,而这些新闻的生命周期存在重叠(即有限竞争)。
本文提出了一种新的新闻推荐方法LANCER,它有三个关键思想:( i )考虑竞争中的新闻;( ii )在竞争新闻中进行基于置信度的负采样;( iii)考虑新闻的剩余周期。
使用两个真实世界新闻数据集的实证研究中,证明了一些最先进的新闻推荐算法通过结合我们的LANCER获得了显著增益。
💡创新点
提出在新闻推荐中考虑生命周期和新闻竞争的想法并验证提高基于DL新闻推荐模型的推荐性能。
✅未来研究方向
使用基于DL的模型来计算新闻负采样的置信度。
👀个人总结
优点:提出的模型具有通用性:可以独立地应用于现有的新闻推荐模型。
这篇关于LANCER : A Lifetime-Aware News Recommender System阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









