本文主要是介绍【已开源】mtcnn_pytorch完美复现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
零 、代码发现
开源QQ群:414475612,名称LazyNet,代码详见群文件!
GITHUB![]() https://github.com/samylee/mtcnn_pytorch
https://github.com/samylee/mtcnn_pytorch
一、算法介绍
MTCNN,Multi-task convolutional neural network(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,它的主题框架类似于cascade。总体可分为P-Net、R-Net、和O-Net三层网络结构。
二、实现结果(完美复现,不是接近!)
2.1. 准确率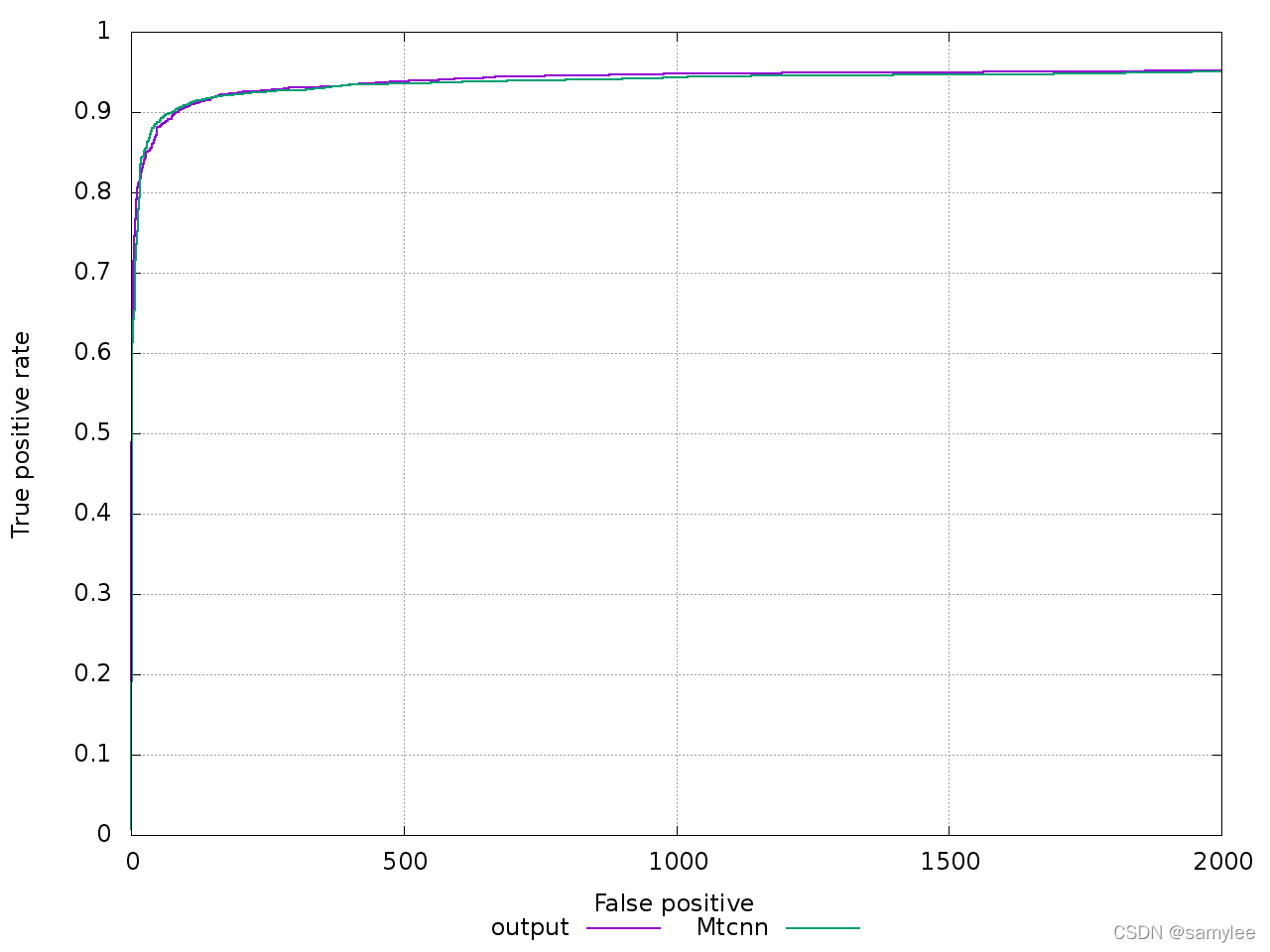
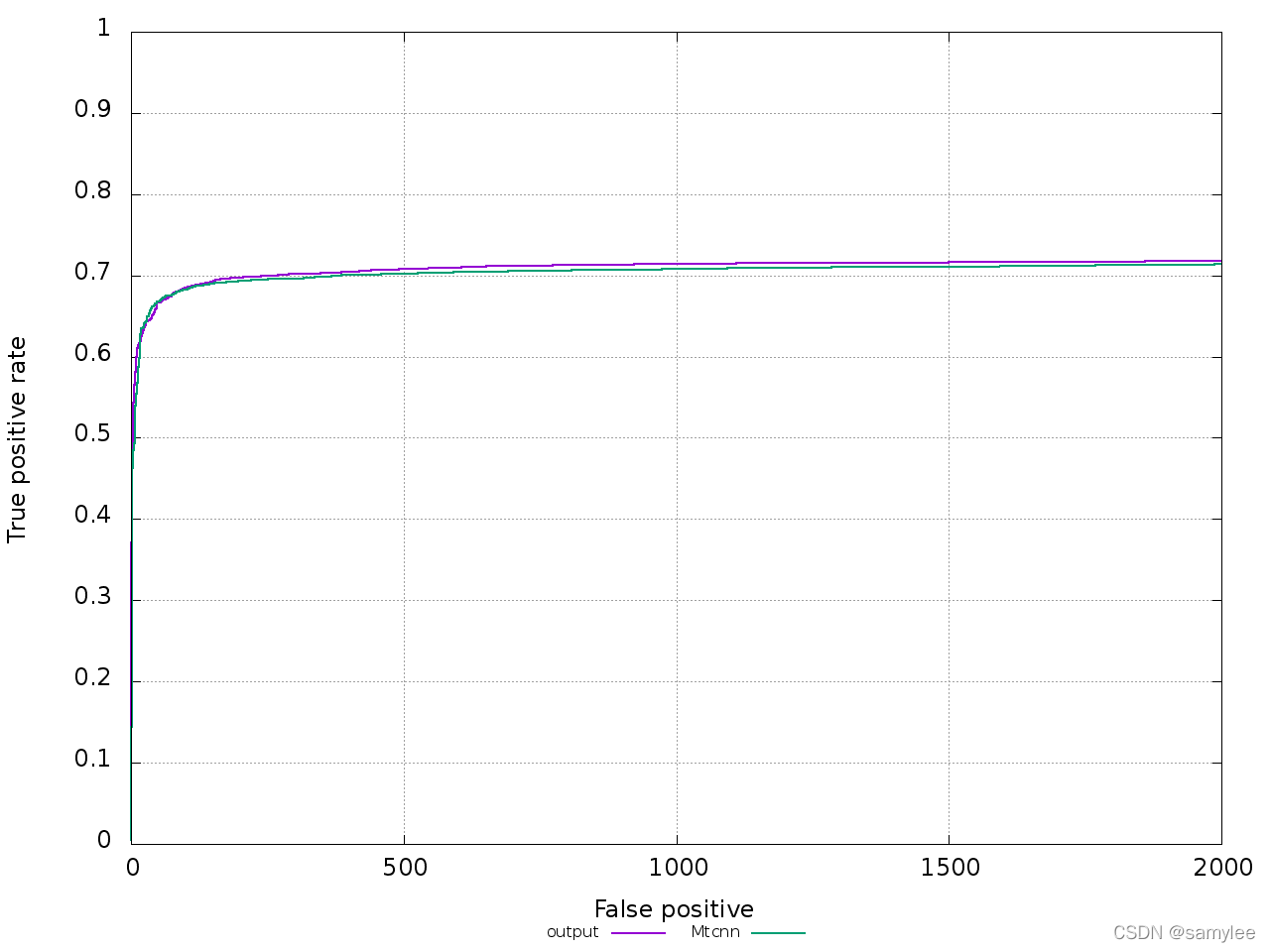
2.2. 速度
| mtcnn | hardware | software | image_size | min_size | speed |
| zhang's | i7-9700K | vs2017-opencv-dnn | 640x480 | 20 | 35ms |
| samylee | i7-9700K | vs2017-opencv-dnn | 640x480 | 20 | 32ms |
2.3. 优势
2.3.1. 大多数复现mtcnn代码并不能完美复现mtcnn的速度,因为他们pnet网络产生了大量负样本,导致整体算法速度减慢,虽然能获得更大的recall,但摒弃了mtcnn算法设计初衷。
2.3.2. 大多数复现mtcnn代码并不能完美复现mtcnn的精度,其ROC曲线并不能重合或稍高。
2.3.3. 大多数复现mtcnn代码编写复杂,逻辑冗长,无法一目了然。
2.3.4. 提供pytorch转caffe工具和c++实现工程,工程部署不在话下。
2.4. 效果展示



三、实现要求
3.1. 系统及硬件要求
ubuntu16.04, nvidia-1080 或者更高,
3.2. 软件要求
anaconda(强烈建议),pycharm(强烈建议)
3.3. 算法依赖
python==3.6
pytorch-gpu==1.4
opencv-python==4.5.4
pickle
四、实现步骤
4.1. pnet实现
4.1.1. 进入'prepare_data/12net_data'下依次运行'gen_12net_data.py'和'gen_12net_imdb.py',用以生成pnet数据结构。
4.1.2. 进入'train', 新建'pnet'文件夹,运行'train_pnet.py'
4.2. rnet实现
4.2.1. 进入'prepare_data/24net_data'下依次运行'gen_24net_data.py', 'gen_24net_data_append.py', 'gen_24net_landmark_data.py'和'gen_24net_imdb.py',用以生成rnet数据结构。
4.2.2. 进入'train', 新建'rnet'文件夹, 运行'train_rnet.py'
4.3. onet实现
4.3.1. 进入'prepare_data/48net_data'下依次运行'gen_48net_data.py', 'gen_48net_data_append.py', 'gen_48net_landmark_data.py'和'gen_48net_imdb.py',用以生成rnet数据结构。
4.2.2. 进入'train', 新建'onet'文件夹, 运行'train_onet.py'
五、测试步骤
5.1. pnet测试
进入'test'文件夹,运行'test_pnet.py'
5.2. rnet测试
进入'test'文件夹,运行'test_rnet.py'
5.3. onet测试
进入'test'文件夹,运行'test_onet.py'
六、验证步骤
6.1. 进入'validate'文件夹下,新建'output'文件夹,运行'gen_fddb_results.py'即可。
6.2. 获得ROC曲线方式网上博客很多,这里就不介绍了。
七. 实现细节
7.1. 关于pnet
7.1.1. 因pnet网络比较小,不利于landmark_regression,因此只采用了classification和bbox_regression。论文虽然写了landmark_regression,但是对标作者实现代码,非也!
7.1.2. 因pnet对classification要求比较高,所以loss_factor采用[1.0, 1.0]。论文虽然写了[1.0, 0.5, 0.5],但是对标作者实现代码,非也!
7.1.3. 数据比例neg:pos:part=3:1:1
7.2. 关于rnet
7.2.1. 因rnet对bbox_regression要求比较高,所以loss_factor采用[1.0, 10.0, 4.0]
7.2.2. 增加了'append'数据,是为了让数据均衡,同时也是让rnet尽可能的提高recall
7.2.3. 数据比例neg:pos:part:ldm=3:1:1:2
7.3. 关于onet
7.3.1. 因onet对landmark_regression要求比较高,所以loss_factor采用[1.0, 10.0, 40.0]
7.3.2. 和rnet类似,增加了'append'数据,是为了让数据均衡,同时也是让onet尽可能的提高recall
7.3.3. 数据比例neg:pos:part:ldm=3:1:1:2
7.4. imdb数据格式
7.4.1. 使用了pickle压缩成imdb格式数据,主要是增加数据读取效率,若直接在pytorch中反复读取数据,会使训练速度慢很多。
7.5. 数据增强
7.5.1. 10%数据灰度化,让网络针对夜间gray图像有一定的鲁棒性
7.5.2. 50%数据水平翻转,让网络更加健壮
7.6. loss设计
7.6.1. 分类loss,采用CrossEntropyLoss,并没有采用ohem,因为算法要求数据稍有不平衡(3:1:1:2),所以并不能使用ohem
7.6.2. 回归loss,采用MSELoss,但是注意reduction='none',并不能平均计算
7.7. wider数据调整
7.7.1. 调整数据格式,(x1, y1, x2, y2)
7.7.2. 调整数据宽高比,因wider有部分人脸数据宽高比为1:2,因此在制作数据时无法获得iou>0.65的正样本,所以将所有数据宽高比都限制在2:3以内
7.8. celebA数据调整
7.8.1. 该数据集人脸边框相较于wider有大不同,所以没有用到
7.8.2. 使用pnet和rnet的人脸检测获得边框更加符合mtcnn算法设计需求
这篇关于【已开源】mtcnn_pytorch完美复现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








