本文主要是介绍【Sofice小司笔记】1 计算机基础知识汇总,杂七杂八的知识总能在这里找到,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编码
-
ASCII编码
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符
-
GBK编码
由于ASCII编码不支持中文,国人就定义了一套编码规则:当字符小于127位时,与ASCII的字符相同,但当两个大于127的字符连接在一起时,就代表一个汉字,第一个字节称为高字节(从0xA1-0xF7),第二个字节为低字节(从0xA1-0xFE),这样大约可以组合7000多个简体汉字。这个规则叫做GB2312。
但是由于中国汉字很多,有些字无法表示,于是重新定义了规则:不在要求低字节一定是127之后的编码,只要第一个字节是大于127,就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这种扩展之后的编码方案称之为GBK标,包括了GB2312的所有内容,同时新增了近20000个新的汉字(包括繁体字)和符号。
但是,中国有56个民族,所以,我们再次对编码规则进行了扩展,又加了近几千个少数民族的字符,于是再次扩展后得编码叫做GB18030。中国的程序员觉得这一系列编码的标准是非常的好,于是统统称他们叫做"DBCS"(Double Byte Charecter Set 双字节字符集)。
-
Unicode字符集
ISO(国际标准化组织)决定定义一套编码方案来解决所有国家的编码问题。Unicode不是一个新的编码规则,而是一套字符集,为每一个「字符」分配一个唯一的 ID(学码位 / 码点 / Code Point)。
每个字符必须使用两个字节(这一标准的2字节形式通常称作UCS-2。然而,受制于2字节数量的限制,UCS-2只能表示最多65536个字符。Unicode的4字节形式被称为UCS-4或UTF-32),对于ASCII编码表里的字符,保持其编码不变,只是将长度扩展到了16位,其他国家的字符全部统一重新编码。由于传输ASCII表里的字符时,实际上可以只用一个字节就可以表示,所以,这种编码方案在传输数据比较浪费带宽,存储数据比较浪费硬盘。
-
UTF-8编码
由于Unicode比较浪费网络带宽和硬盘,因此为了解决这个问题,就在Unicode的基础上,定义了一套编码规则,将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程),这个新的编码规则就是UTF-8,采用1-4个字符进行传输和存储数据。
**utf8mb4:**MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。
-
UTF-16编码
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
-
UTF-32编码
用固定长度的字节存储字符编码,不管Unicode字符编号需要几个字节,全部都用4个字节存储,直接存储Unicode编号。无需经过字符编号向字符编码的转换步骤,提高效率,用空间换时间。
UTF-8与Unicode转换
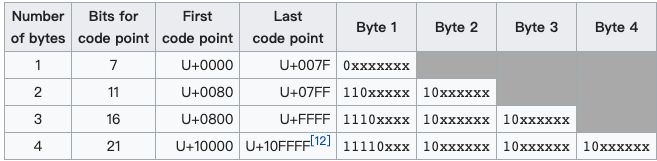
Unicode 与 UTF-8 对应关系:
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
比如汉字“智”,utf-8编码是 “\xe6\x99\xba” 对应的二进制为:“111001101001100110111010”,由于utf-8中一个汉字是3个字节,所以对应的模板为“0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx”。
11100110 10011001 10111010
1110xxxx 10xxxxxx 10xxxxxx
0110 011001 111010
0110011001111010代表十六进制667A,因此根据规则转换得出“智”Unicode的位置为为“667A”。
Unicode与GBK编码的转换
比如汉字“路”,在gbk中的编码为 “\xc2\xb7” ,对应的二进制为:“1100 0010 1011 0111”。同时“路”在Unicode字符集中的位置是“\u8def”(python中的Unicode类型),因此可以通过“\u8def”在Unicode字符集中找到“路”对应的编码为“4237”,对应的二进制为:“0100 0010 0011 0111”,由于gbk的两个字节的高字节是为了区分中文和ASCII,所以将“1100 0010 1011 0111”高字节的“1”去掉后,就对应Unicode字符集中的0100 0010 0011 0111”
这篇关于【Sofice小司笔记】1 计算机基础知识汇总,杂七杂八的知识总能在这里找到的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






