本文主要是介绍PointRend原理及源码解读--2020.2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文PointRend: Image Segmentation as Rendering
本质
个人认为这篇文章的本质就是,在最深的feature map上进行预测,找出分类不明确的这些点,然后把这些点的低层特征concat进来单独再进行预测;
之所以计算量小,速度快,就是因为只concat了有限少量点的低层特征,而不是全部低层特征。
1、PointRend原理
PointRend 能够通过一种不断迭代的算法来自适应的挑选出有问题的区域,并对该区域的像素点进行精细化的调整预测(多层感知机)。
1.1 PointRend结构
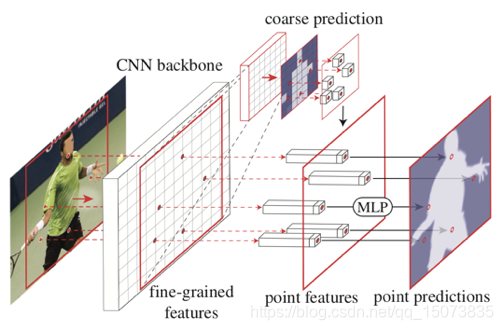
PointRend模块主要由三部分组成:
①难点的选取策略:并不是feature map中的全部点,为了降低计算量
②基于点的特征point-wise feature获取:用双线性插值
③Point head:一个小的可训练的网络(多层感知机MLP)来预测每个点的label
PointRend 方法要点总结来说是一个迭代上采样的过程:
while 输出的分辨率 < 图片分辨率:
- 对输出结果进行2倍双线性插值上采样得到 coarse prediction_i。
- 挑选出 N 个“难点”,即结果很有可能和周围点不一样的点(例如物体边缘)。
- 对于每个难点,获取其“表征向量”,“表征向量”由两个部分组成,其一是低层特征(fine-grained features),通过使用点的坐标,在低层的特征图上进行双线性插值获得(类似 RoI Align),其二是高层特征(coarse prediction),由步骤 1 获得。
- 使用 MLP 对“表征向量”计算得到新的预测,更新 coarse prediction_i 得到 coarse prediction_i+1。这个 MLP 其实可以看做一个只对“难点”的“表征向量”进行运算的由多个 conv1x1 组成的小网络。
Point Head:
对于每个选定点的逐点特征表示,PointRend使用简单的多层感知器(MLP)进行逐点分割预测。
该多层感知器在所有点(和所有区域)上共享权重。
由于 MLP预测的是每个点的分割标签,因此它可以通过标准的任务特定的分割损失进行训练。
1.2 Inference
从常规的网络的最后一层输出开始(意思就是从网络的最深层,即感受野最大的那层开始上采样迭代),在每一次迭代的过程中,PointRend都会用双线性差值(bilinear interpolation)的办法进行上采样,并且从中选取N个不确定的点(比如那些在二分蒙版的情况下概率接近0.5的),**生产该点的特征,并预测它们的标签。**这一方法将被迭代使用,直到达到输出的分辨率大小。
在stride最大的那一层进行预测,然后进行一次2倍双线性插值上采样,从中选取N个最不确定的点(在binary mask中概率接近0.5的点)。
然后计算这些点的特征point-wise feature representation,再进行预测。
重复上述两个步骤,直到想要的分辨率
这些点的特征point-wise feature representation如何表达?
Fine-grained features和Coarse prediction features进行concatenate
其实就是将两种不同的特征(细粒度特征和粗粒度特征)进行拼接,作为每一个点的特征表示。两者的作用分别是提供目标的细节信息以及全局的上下文信息。
- Fine-grained features:
从单一feature map中进行双线性插值比如res2
也可以从多个feature map中进行双线性插值后再concatenate,如res2~res5或者fpn
代码中选取的是fpn后的feature map最大的一层。
- Coarse prediction features:
从stride=16的feature map上进行预测
这一处理的示意图如下所示,
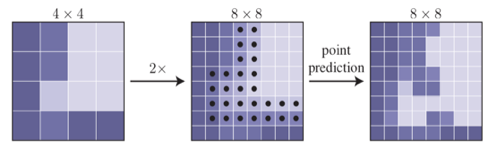
对于采样点的选择一个指导思想就是选择那些与周围邻域有较大差异概率的点(可以理解为边缘部分)。而在预测阶段文章会选择不确定性最大的N 个采样点(这些点的概率接近于0.5,不确定性最大),之后在PointRend中去预测这些点的标签。
def forward_test(self, inputs, prev_output, img_metas, test_cfg):"""Forward function for testing.Args:inputs (list[Tensor]): List of multi-level img features.prev_output (Tensor): The output of previous decode head.img_metas (list[dict]): List of image info dict where each dicthas: 'img_shape', 'scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.test_cfg (dict): The testing config.Returns:Tensor: Output segmentation map."""x = self._transform_inputs(inputs)refined_seg_logits = prev_output.clone()for _ in range(test_cfg.subdivision_steps): # 上采样几次refined_seg_logits = resize(refined_seg_logits,scale_factor=test_cfg.scale_factor,mode='bilinear',align_corners=self.align_corners)batch_size, channels, height, width = refined_seg_logits.shapepoint_indices, points = self.get_points_test(refined_seg_logits, calculate_uncertainty, cfg=test_cfg) # 每次上采样,计算分类不确定性,获取不确定的pointfine_grained_point_feats = self._get_fine_grained_point_feats(x, points) # 获取这些点的细特征,即在fpn的最大feature map上的coarse_point_feats = self._get_coarse_point_feats(prev_output, points) # 获取这些点的粗特征,即在把fpn所有level的feature map都上采样并加到最大feature map的point_logits = self.forward(fine_grained_point_feats,coarse_point_feats) # 获取这些点的预测point_indices = point_indices.unsqueeze(1).expand(-1, channels, -1)refined_seg_logits = refined_seg_logits.reshape(batch_size, channels, height * width)refined_seg_logits = refined_seg_logits.scatter_(2, point_indices, point_logits)refined_seg_logits = refined_seg_logits.view(batch_size, channels, height, width)return refined_seg_logits
计算不确定性的函数
def calculate_uncertainty(seg_logits):"""Estimate uncertainty based on seg logits.For each location of the prediction ``seg_logits`` we estimateuncertainty as the difference between top first and top secondpredicted logits.Args:seg_logits (Tensor): Semantic segmentation logits,shape (batch_size, num_classes, height, width).Returns:scores (Tensor): T uncertainty scores with the most uncertainlocations having the highest uncertainty score, shape (batch_size, 1, height, width)"""top2_scores = torch.topk(seg_logits, k=2, dim=1)[0]return (top2_scores[:, 1] - top2_scores[:, 0]).unsqueeze(1)
self.get_points_test()
def get_points_test(self, seg_logits, uncertainty_func, cfg):"""Sample points for testing.Find ``num_points`` most uncertain points from ``uncertainty_map``.Args:seg_logits (Tensor): A tensor of shape (batch_size, num_classes,height, width) for class-specific or class-agnostic prediction.uncertainty_func (func): uncertainty calculation function.cfg (dict): Testing config of point head.Returns:point_indices (Tensor): A tensor of shape (batch_size, num_points)that contains indices from [0, height x width) of the mostuncertain points.point_coords (Tensor): A tensor of shape (batch_size, num_points,2) that contains [0, 1] x [0, 1] normalized coordinates of themost uncertain points from the ``height x width`` grid ."""num_points = cfg.subdivision_num_pointsuncertainty_map = uncertainty_func(seg_logits)batch_size, _, height, width = uncertainty_map.shapeh_step = 1.0 / heightw_step = 1.0 / widthuncertainty_map = uncertainty_map.view(batch_size, height * width)num_points = min(height * width, num_points)point_indices = uncertainty_map.topk(num_points, dim=1)[1]point_coords = torch.zeros(batch_size,num_points,2,dtype=torch.float,device=seg_logits.device)point_coords[:, :, 0] = w_step / 2.0 + (point_indices %width).float() * w_steppoint_coords[:, :, 1] = h_step / 2.0 + (point_indices //width).float() * h_stepreturn point_indices, point_coords
self._get_fine_grained_point_feats()
def _get_fine_grained_point_feats(self, x, points):"""Sample from fine grained features.Args:x (list[Tensor]): Feature pyramid from by neck or backbone.points (Tensor): Point coordinates, shape (batch_size,num_points, 2).Returns:fine_grained_feats (Tensor): Sampled fine grained feature,shape (batch_size, sum(channels of x), num_points)."""fine_grained_feats_list = [point_sample(_, points, align_corners=self.align_corners)for _ in x]if len(fine_grained_feats_list) > 1:fine_grained_feats = torch.cat(fine_grained_feats_list, dim=1)else:fine_grained_feats = fine_grained_feats_list[0]return fine_grained_feats
point_sample()
def point_sample(input, points, align_corners=False, **kwargs):"""A wrapper around :func:`grid_sample` to support 3D point_coords tensorsUnlike :func:`torch.nn.functional.grid_sample` it assumes point_coords tolie inside ``[0, 1] x [0, 1]`` square.Args:input (Tensor): Feature map, shape (N, C, H, W).points (Tensor): Image based absolute point coordinates (normalized),range [0, 1] x [0, 1], shape (N, P, 2) or (N, Hgrid, Wgrid, 2).align_corners (bool): Whether align_corners. Default: FalseReturns:Tensor: Features of `point` on `input`, shape (N, C, P) or(N, C, Hgrid, Wgrid)."""add_dim = Falseif points.dim() == 3:add_dim = Truepoints = points.unsqueeze(2)output = F.grid_sample(input, denormalize(points), align_corners=align_corners, **kwargs)if add_dim:output = output.squeeze(3)return output
self._get_coarse_point_feats()
def _get_coarse_point_feats(self, prev_output, points):"""Sample from fine grained features.Args:prev_output (list[Tensor]): Prediction of previous decode head.points (Tensor): Point coordinates, shape (batch_size,num_points, 2).Returns:coarse_feats (Tensor): Sampled coarse feature, shape (batch_size,num_classes, num_points)."""coarse_feats = point_sample(prev_output, points, align_corners=self.align_corners)return coarse_feats
def forward(self, fine_grained_point_feats, coarse_point_feats):x = torch.cat([fine_grained_point_feats, coarse_point_feats], dim=1)for fc in self.fcs:x = fc(x)if self.coarse_pred_each_layer:x = torch.cat((x, coarse_point_feats), dim=1)return self.cls_seg(x)
self.fcs就是一个多层感知机MLP
self.fcs = nn.ModuleList()
for k in range(num_fcs):fc = ConvModule(fc_in_channels,fc_channels,kernel_size=1,stride=1,padding=0,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg)self.fcs.append(fc)fc_in_channels = fc_channelsfc_in_channels += self.num_classes if self.coarse_pred_each_layer \else 0
def cls_seg(self, feat):"""Classify each pixel with fc."""if self.dropout is not None:feat = self.dropout(feat)output = self.fc_seg(feat)return output
self.fc_seg = nn.Conv1d(fc_in_channels,self.num_classes,kernel_size=1,stride=1,padding=0)
if self.dropout_ratio > 0:self.dropout = nn.Dropout(self.dropout_ratio)
1.3 Training
训练时用上述交互的方法不利于反向传播,所以用的是随机采样的方法。
①先从均匀分布中随机选取kN个点, k>1
②对这些kN个点进行插值预测,并计算其不确定度(概率最大的两个类别的概率差),选出最不确定的βN个,β∈[0,1]
③剩余的(1-β)N个点从均匀分布中采样。
这种策略更偏重于那些不确定的区域,也就是物体轮廓。
文中,deeplabV3,训练时N=2304,k=3,β=0.75
N在inference和training时可以不一样,inference时N=8096
def forward_train(self, inputs, prev_output, img_metas, gt_semantic_seg,train_cfg):"""Forward function for training.Args:inputs (list[Tensor]): List of multi-level img features.prev_output (Tensor): The output of previous decode head.img_metas (list[dict]): List of image info dict where each dicthas: 'img_shape', 'scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.gt_semantic_seg (Tensor): Semantic segmentation masksused if the architecture supports semantic segmentation task.train_cfg (dict): The training config.Returns:dict[str, Tensor]: a dictionary of loss components"""x = self._transform_inputs(inputs)with torch.no_grad():points = self.get_points_train(prev_output, calculate_uncertainty, cfg=train_cfg)fine_grained_point_feats = self._get_fine_grained_point_feats(x, points)coarse_point_feats = self._get_coarse_point_feats(prev_output, points)point_logits = self.forward(fine_grained_point_feats,coarse_point_feats)point_label = point_sample(gt_semantic_seg.float(),points,mode='nearest',align_corners=self.align_corners)point_label = point_label.squeeze(1).long()losses = self.losses(point_logits, point_label)return losses
self.get_points_train()
def get_points_train(self, seg_logits, uncertainty_func, cfg):"""Sample points for training.Sample points in [0, 1] x [0, 1] coordinate space based on theiruncertainty. The uncertainties are calculated for each point using'uncertainty_func' function that takes point's logit prediction asinput.Args:seg_logits (Tensor): Semantic segmentation logits, shape (batch_size, num_classes, height, width).uncertainty_func (func): uncertainty calculation function.cfg (dict): Training config of point head.Returns:point_coords (Tensor): A tensor of shape (batch_size, num_points,2) that contains the coordinates of ``num_points`` sampledpoints."""num_points = cfg.num_pointsoversample_ratio = cfg.oversample_ratioimportance_sample_ratio = cfg.importance_sample_ratioassert oversample_ratio >= 1assert 0 <= importance_sample_ratio <= 1batch_size = seg_logits.shape[0]num_sampled = int(num_points * oversample_ratio)point_coords = torch.rand(batch_size, num_sampled, 2, device=seg_logits.device)point_logits = point_sample(seg_logits, point_coords)# It is crucial to calculate uncertainty based on the sampled# prediction value for the points. Calculating uncertainties of the# coarse predictions first and sampling them for points leads to# incorrect results. To illustrate this: assume uncertainty func(# logits)=-abs(logits), a sampled point between two coarse# predictions with -1 and 1 logits has 0 logits, and therefore 0# uncertainty value. However, if we calculate uncertainties for the# coarse predictions first, both will have -1 uncertainty,# and sampled point will get -1 uncertainty.point_uncertainties = uncertainty_func(point_logits)num_uncertain_points = int(importance_sample_ratio * num_points)num_random_points = num_points - num_uncertain_pointsidx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]shift = num_sampled * torch.arange(batch_size, dtype=torch.long, device=seg_logits.device)idx += shift[:, None]point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(batch_size, num_uncertain_points, 2)if num_random_points > 0:rand_point_coords = torch.rand(batch_size, num_random_points, 2, device=seg_logits.device)point_coords = torch.cat((point_coords, rand_point_coords), dim=1)return point_coords
更多可参考这篇何恺明团队开源图像分割新算法 PointRend:性能显著提升,算力仅需 Mask R-CNN 的 2.6%
这篇关于PointRend原理及源码解读--2020.2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






