摘要:在2017杭州云栖大会阿里云HTAP技术专场上,上海秦苍信息科技有限公司DBA负责人赵怀刚为大家分享了HTPA型数据库产品在现实中的落地应用以及企业级数据库架构设计中的HTPA的应用。
本文内容根据嘉宾演讲视频以及PPT整理而成。 本次分享的主题是买单侠数据库架构之路。秦苍科技是一家互联网消费金融公司,我们所有的产品基本都是托管在阿里云上的,在自己的系统中大概应用了20多种阿里云数据库产品。基于阿里云平台,秦苍科技的数据库架构与传统RDS数据运维相比存在着本质的区别。接下来着重介绍一下在产品公司业务快速发展的情况下,系统数据库架构的演变历程。
本次分享的主题主要分为以下四个部分:
一、关于秦苍科技
二、在业务的快速发展中遇到的问题
三、数据库架构演变过程和案例分析
四、基于云数据库运维的思考
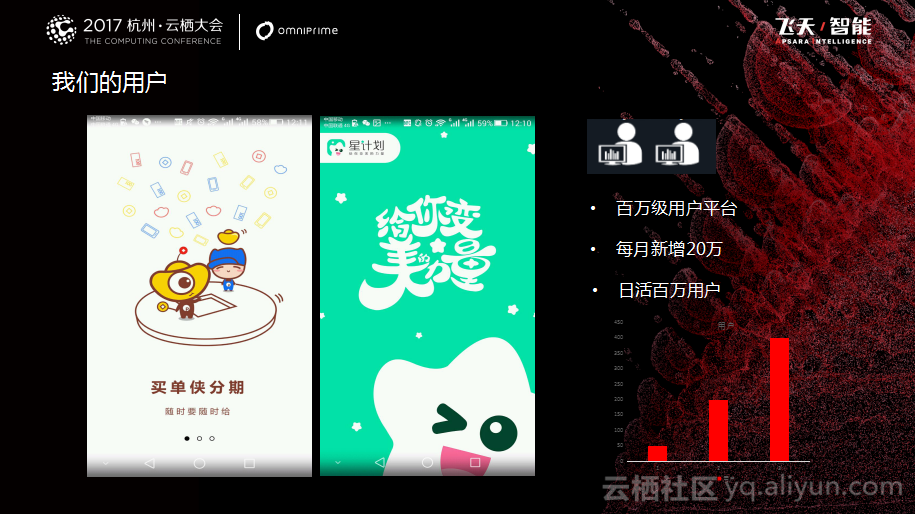
一、关于秦苍科技 如图所示的是秦苍科技的两个产品,最左边叫做买单侠,主要针对的是年轻蓝领客户群体,主要提供一些消费场景下的分期金融服务。右边这个产品主要目标用户群体是年轻的女性白领,主要为她们提供一些医疗美容的消费分期金融服务。目前秦苍科技公司的用户数大概为400多万,每个月新增大概20万用户,每天日活用户大概是在百万左右。秦苍科技目前做单的模式并没有完全放在线上,还是偏传统一点,会与线下的手机门店、医院、电动车销售商等这些商家合作,通过线下入口而不是直接通过APP进行操作,所以可以说秦苍科技的商业模式还是比较偏传统的。
如图所示的是秦苍科技的技术栈,主要是用的后台技术是基于Spring Cloud的微服务架构,部署则采用的是Docker技术,当然用的也是阿里云的容器服务。
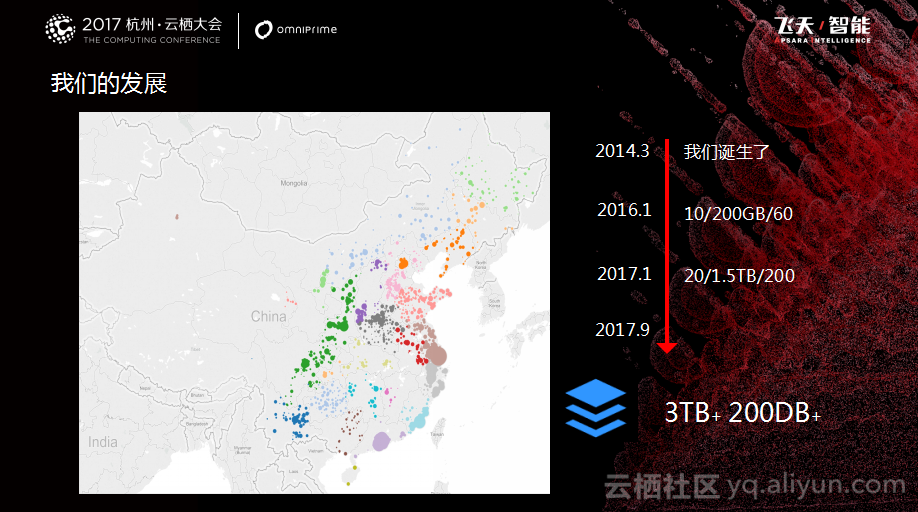
秦苍科技公司成立于2014年3月,到现在大概经历了三年半的时间,目前大概遍布了全国的300个城市。系统最开始的数据库是单体架构的,所有东西都放到一起。而现在数据库有将近200个,并且对于数据库也做了拆分,目前线上的数据量已经达到了3 TB。
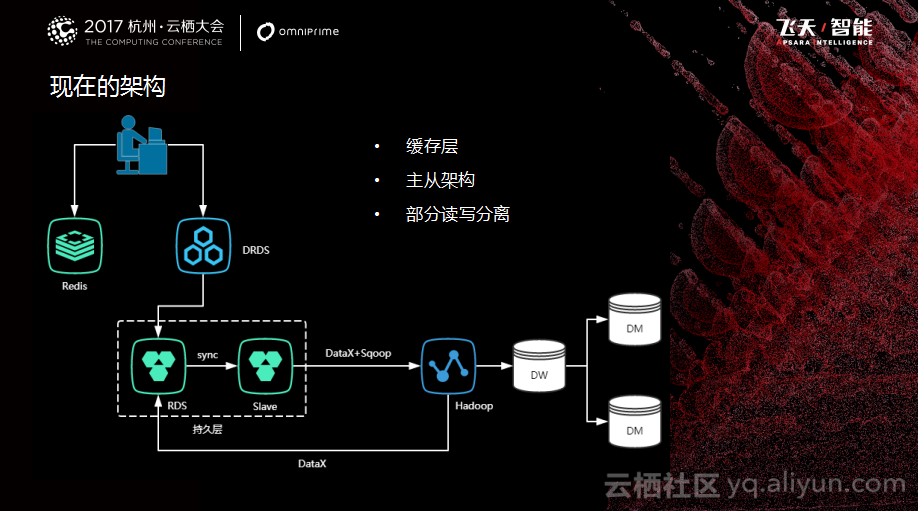
目前所使用的数据库架构主要采用了阿里云RDS。秦苍科技所处的是一个互金行业,所以会从一些第三方数据源那里拿数据,并与资方做交互。这些数据的变更可能比较频繁,需要依赖于第三方。对于这些数据而言,我们采取MongoDB进行存储,缓存层采用阿里云的Redis,总体而言都是采用阿里云RDS服务。
互金行业核心就是风控,秦苍科技自研了一个风控模型,这个模型叫做抱团算法,接下来大概简单介绍一下它的实现。什么是抱团呢?比如你的身边有十个朋友,如果十个朋友当中有八个朋友信用都存在问题,或者之前发生过借贷关系,但信用不是太好,就会认为你这个人有可能信用上存在问题。这个风控模型的后台采用的是neo4j图数据库集群,目前RDS的规模大概在150个MySQL、20多个MongoDB以及20个Redis。刚开始的时候采取.Net + SQL server构建的,后来把数据从SQL server迁移到了MySQL,这是因为在使用SQL server的过程当中遇到很多问题,SQL server目前不支持只读实例,在扩展性和灵活性上对业务造成了很大困扰。因为数据中心需要做数据分析,要从线上取数据,这样OLTP以及一些分析的提取都耦合不到一起。
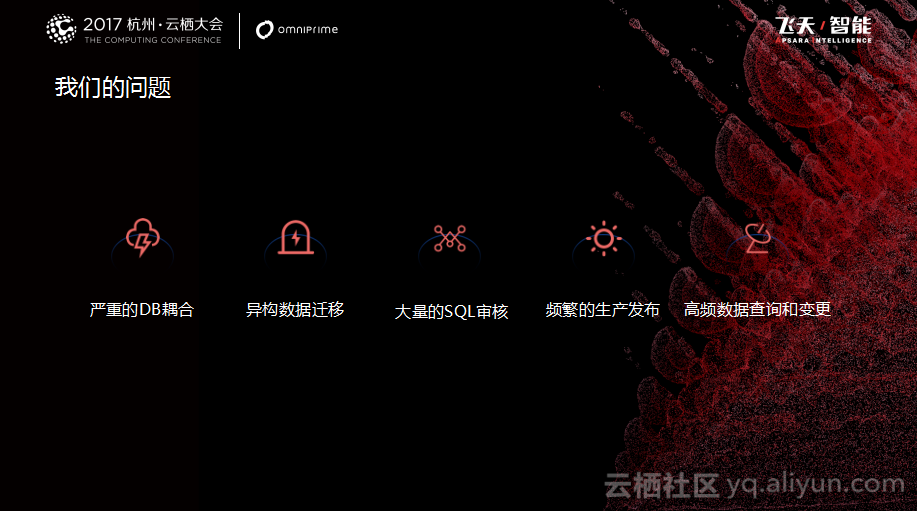
二、在业务的快速发展中遇到的问题 数据库架构演变的过程当中遇到了很多问题,所以秦苍科技的所有的技术全部选择都是在阿里云上的,包括了对于数据库的选择。使用阿里云RDS比较直接的好处就是它可以开箱即用并且可以弹性扩容。随着业务量的增加,可以轻松地升级,比如硬件上的升级,以及外围辅助的升级,还可以非常方便地实现数据迁移,后来阿里云还提供了DTS服务,可以轻松实现异构数据迁移。最初因为设计的问题,所有的数据是放在同一个实例库下,所以当出现比较高的并发时就会导致实例的CPU爆掉,进而导致数据库服务不可用。这就是所面临的问题,也是这两年时间一直在做的事情——迁移、解耦和拆分。
在这个过程中,我们遇到了异构数据迁移的问题。另外随着公司业务的发展,规模的不断变大,在整个数据库运维当中出现了效率上的问题,主要是现在有大量的SQL审核工作要做,而且有频繁的生产发布,而每次发布都要等到比较晚的时间比如业务的低谷期来发布。还有一些高频的数据查询和变更需求。主要是研发同学需要去定位Bug要获取一些数据,以上这些就是之前面临的一些问题。在开始数据规模比较小的时候使用的是比较粗暴的做法也就是人肉支撑。当发展到现在的量级,现在有3个研发中心,300多个研发同学,而DBA只有四个人,需要从DevOps角度考虑如何去支撑这么多的用户。
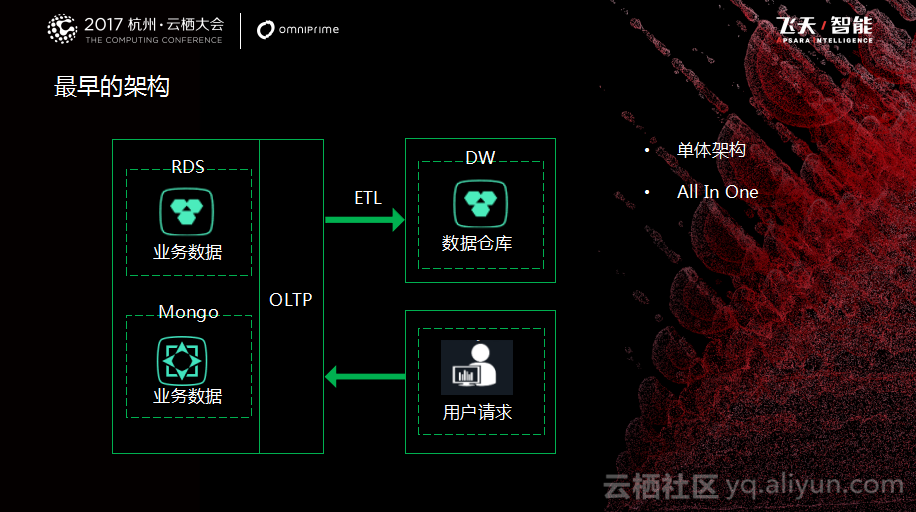
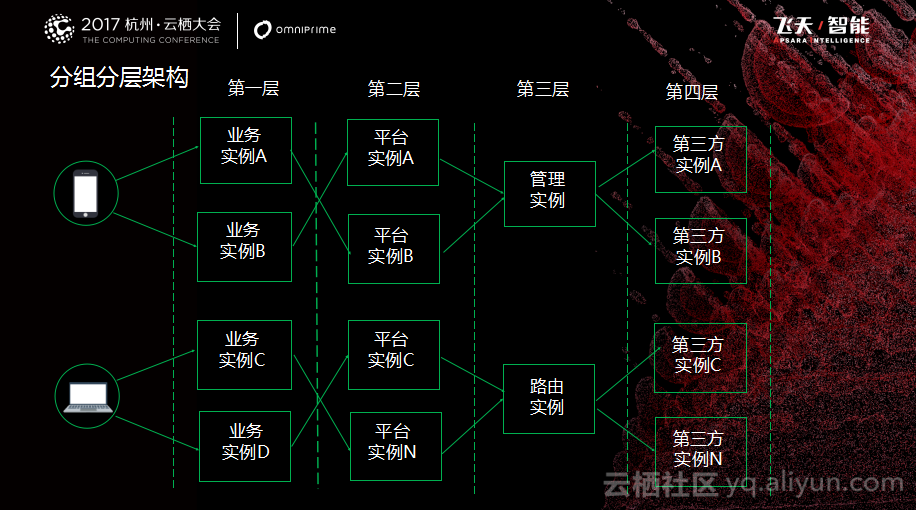
三、数据库架构演变过程和案例分析 如图所示是秦苍科技最早数据库的架构设计,是一个比较简单的单体架构,all in one,所有数据全部放在一个库里,可能有好几百张表。而且随着数据量的增加,OLTP都达到千万级,对于数据可用性就没法保障了。随着业务的发展,后台服务要进行微服务化架构,进行服务改造。数据库应该尽量配合后台进行微服务化的改造,这是需要思考的问题。如何进行微服务拆分呢?后来数据库团队也是在不断地摸索和思考这个问题,最后总结出拆分的大致思路,就是采取分组分层的方法,对于整个数据库进行架构的调整。
分层就是根据业务的需求特征进行分类划分主题域,这有点像数仓分析建模的概念。我们会将数据库分成不同的层次,比如可以根据需求特征分为业务、平台等层次。分组就是对主题域数据进行进一步抽象和归纳,可以抽象出来很多的逻辑组,并将逻辑组再根据具体的功能模块进一步做拆分,这可能会包含多个实例或者多个库。而针对一些业务量特别大的场景,也有使用阿里云DRDS实现水平的分表分库方案。
在分组分层时,为了节省资源和方便管理,我们做了一个小技巧,就是把不同的数据库暂时放在同一个实例上,但数据库的账号却是完全隔离的,这个账号只拥有访问某些数据库的权限。刚开始时业务量比较小,所以基于成本的考虑会放到一起。随着业务量的增加,如果出现性能问题,就可以基于阿里云DTS数据迁移服务,把数据拆分开迁入到性能比较好的实例上去。
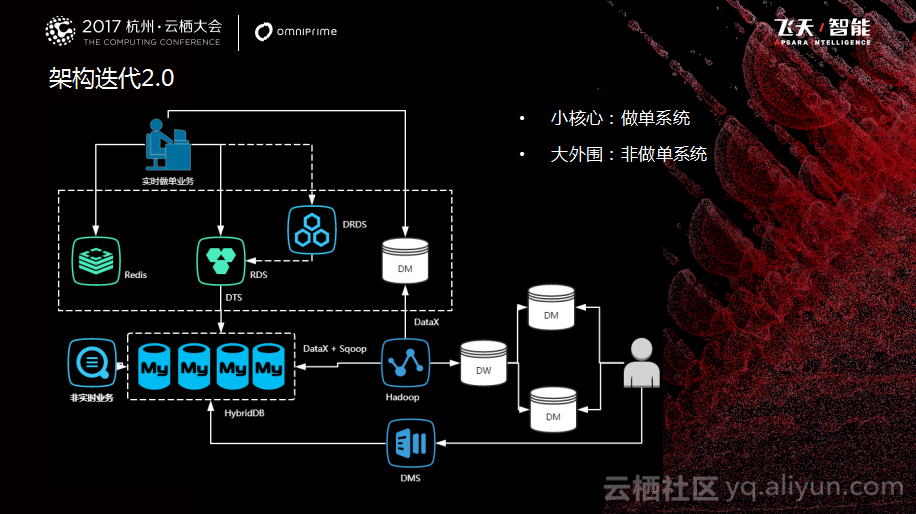
基于上面分组分层的思想,出现了一个中间的过渡架构,这个架构也没有什么特别的,主要跟之前单体架构相比多了一个缓存层。之前的SQL Server不支持读写分离,全部迁入到MySQL之后就做了读写分离,来满足业务上读负载的瓶颈。再看一下如下图所示的现在的架构。根据业务的重要性,把整个系统分为两类,核心系统和外围系统。核心系统就是做单的系统,相当于大家到淘宝买东西,用户从商品选择到最后下单,整个流程走完是一个订单核心的系统。剩下的非做单系统,也就是大外围的系统。后台架构采用了分布式的微服务架构,服务的拆分粒度也比较细,但是这样也会遇到一些问题。
现在线上做单数据调用的服务,也会被用于分析的运营支撑系统调用,取用户订单相关信息要调多个服务,才能满足运营或分析的需求。这样,做单系统和运营支撑系统访问,数据层是耦合到一起的。于是,又找了一个折中的方法。这个折中的方法,就是选择HybirdDB,它就相当于一个大数据资源池,于是增加了Hybird DB作为数据的交换平台,主要提供核心系统和外围系统数据交换,内部叫做数据交换平台。
数据交换平台会把所有线上数据进行汇总,这样一些外围系统或者非实时请求就可以通过访问数据交换平台获取数据,这样其实对于数据交换平台提出了很大的要求:首先这个平台需要足够的大,因为现在线上数据也有3 TB,RDS实例本身没法支撑到这么大的数据量。第二,要能够很好地进行水平拆分和扩展。此外,还要完全兼容MySQL的协议。于是我们选择了HybirdDB,它解决了大的数据资源池问题。
我们同时引入了阿里运数据管理的工具——DMS,主要解决了线上实时数据的查询问题,能够做到安全的管控。另外对大数据平台计算之后的数据也做了集中的管控,可以为线上提供一些数据支撑。
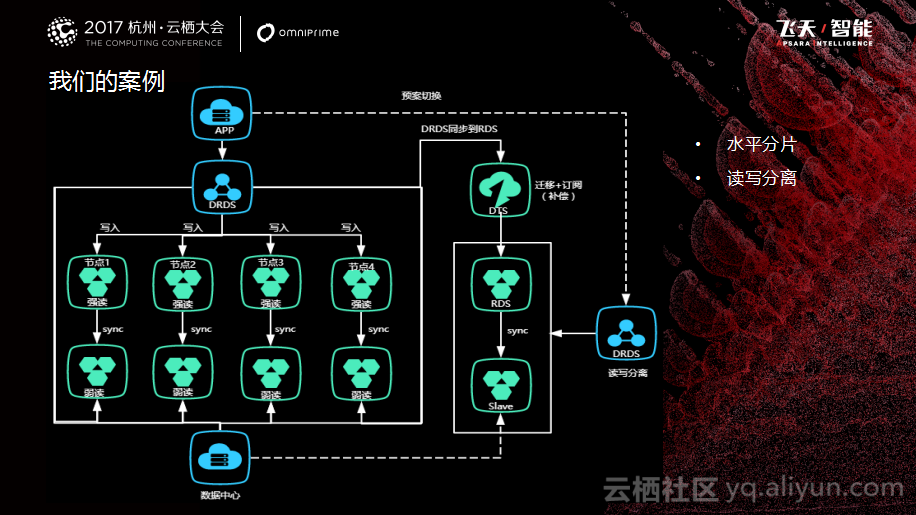
微服务分布式架构演变过程中少不了数据迁移,数据迁移必然会涉及到对老模型分析、新模型设计以及新老模型之间的映射和转码等问题,所以迁移之前要做好充分准备。首先要制定迁移总体方案,包括迁移准备、实施步骤、关键点控制、应急预案等。我们借助阿里云DRDS中间件实现对核心表的水平拆分,图中的虚线部分是预案,因为属于核心的系统,这里不能有太多停机时间,需要保证数据同步。在上线过程当中,借助阿里云DTS数据迁移和订阅服务大大降低了停机时间并实现了应急预案。
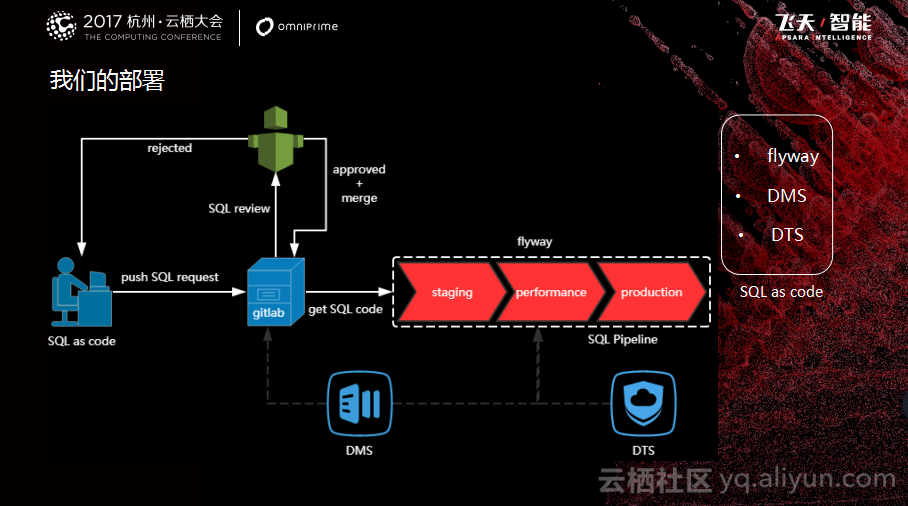
如图所示的是数据库的自动化部署。SQL脚本的部署借鉴了系统发布的思路,首先要有个思维上的转变,把SQL当做是代码的一部分来运维,即:SQL as code;研发设计好数据库后,会提交一个SQL request到gitlab代码仓库,DBA收到请求后做脚本的审核,通过后会把SQL代码merge到release分支(只能DBA merge),未通过的SQL DBA会备注审核建议后驳回到研发进行调整,调整后继续走刚才审核流程。数据库发布我们采用的是flyway,在部署服务时,首先会检测本次上线发布是否有数据库的变更,如果有的话就去执行,没有就跳过。如果在执行过程当中报错或者有问题,就会通知运维进行处理,但是这种机率很小,99%以上都会成功。目前阿里云DMS实现了一些自主化审核的功能,基于定义好的规范、规则进行自动化的审核,这样就可以把上面对人依赖的点解决掉。
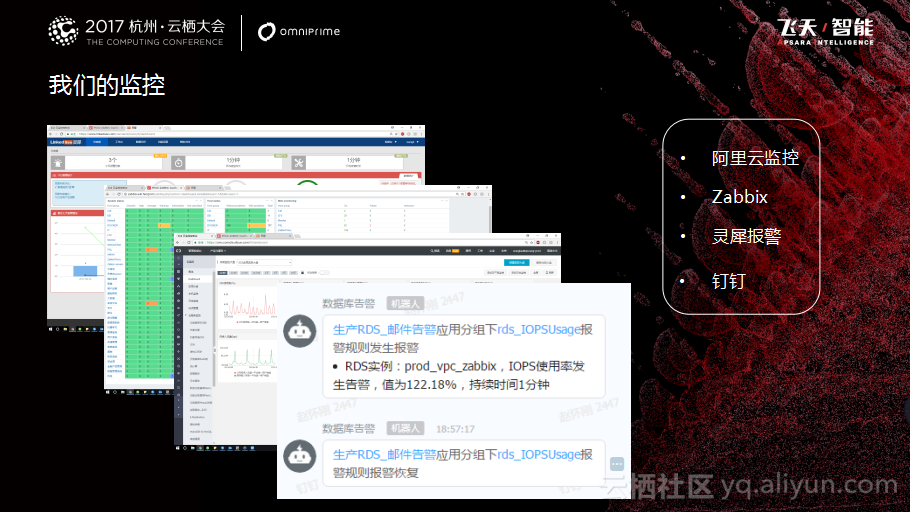
如图所示的是我们的监控,主要分为两个部分:对于基础资源的监控和数据的监控。基础资源的监控,是借助阿里云的监控实现的。阿里云的云监控支持短信、邮件等方式,但是不支持电话报警,所以我们又开发了自己一套电话报警机制。数据监控我们主要借助Zabbix对数据库的业务数据进行探测,如果发现异常之后会上报到电话报警平台,其也是一个第三方监控平台,它会电话通知到第一责任人。而且这个电话报警支持报警升级,如果接听人没有处理,就会打电话给负责人,使问题得到解决。上面两种监控都属于事中监控,事前监控现在比较传统主要靠DBA主动优化和巡检提前发现并解决。因为RDS会提供丰富的API,目前所有数据都可以通过API获取到,把这些数据丢到HybirdDB里进一步做分析,进行主动监控,目前我们正在尝试。
四、基于云数据库运维的思考
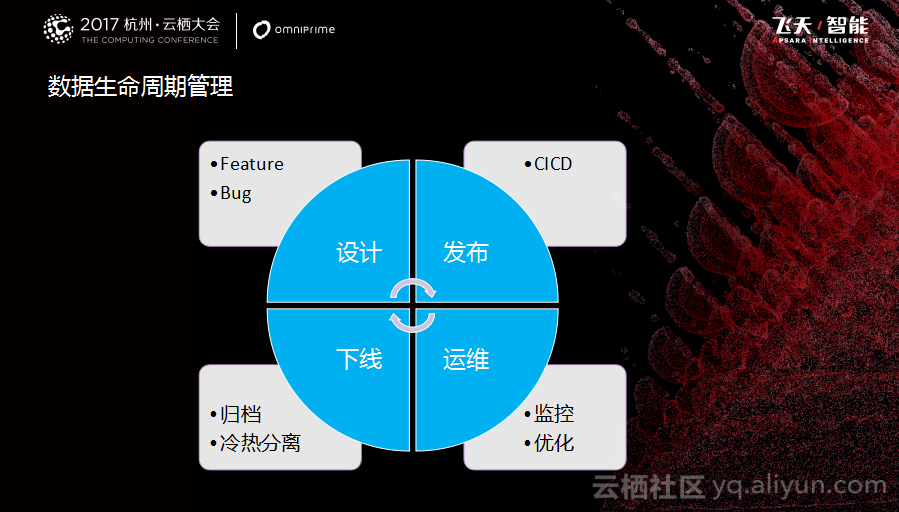
最后一部分是基于云数据库运维的思考。其实将所有的东西放在阿里云上使我们的工作发生了本质变化。第一个是工作前置化成为可能,使DBA向DA转变成为了可能,从之前数据库运维管理到数据的应用。向数据生命周期管理的方向靠拢是目前一个工作重心,系统有生命周期,数据一样也应该有生命周期。数据的生命周期从最初的设计到发布、维护,再到下线。而现在好多数据在设计时没有考虑它的生命周期,数据很难产生最大价值,如果把一个比较小的系统设计成高并发或者高可用的方案,会造成额外的运维和经济成本。
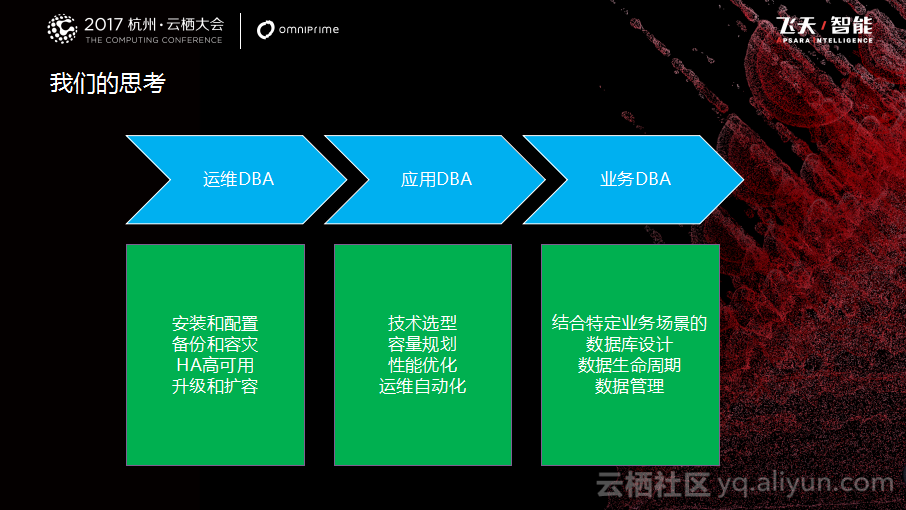
我们对整个DBA行业做了分类,大概分为运维DBA、应用DBA以及业务DBA。每个角色的工作重点各不一样,运维DBA更加偏重于数据库的安装和配置、HA高可用、备份容灾以及升级扩容等,这些已经被云做掉了;应用DBA是我们当前所处的阶段,主要偏重于数据库相关技术选型、容量规划、性能优化和运维自动化等,其实阿里云也在将该部分工作实现自动化和智能化,包括CloudDBA、DMS、DTS等外围增值服务,推动我们从应用DBA转向业务DBA。目前我们也在向这方面去靠拢和思考,后面的工作重心会更多地放在数据库的架构以及数据的应用上,让数据产生更多的价值,为业务提供数据支持。
下图是秦苍科技的技术公众号,上面会定期公布一些技术文章,感兴趣的同学可以关注一下。