本文主要是介绍活用向量数据库,普通散户也能找到潜力股!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✏️ 编者按:
在股市里,光是一支股票,其 K 线、形态、指标就已经含有丰富的信息,更何况股市里有大几千支股票,各种信息令人眼花缭乱。普通散户到底如何全盘分析,选出一支潜力股?
向量搜索领域的技术大牛、业余股民老莫给出了他的答案:他尝试将复杂的数组转化成向量,然后使用开源向量数据库 Milvus 辅助分析股票,为「选股」这一世纪难题给出了量化分析选股的思考角度。当今时代,各个领域的数据体量和种类呈几何式增长,为了分析海量的结构化与非结构化数据,将数据转化成高维向量并进行向量相似度分析已逐渐成为一种行之有效的方式。
本文转载自知乎用户 @yhmo,已获得原作者授权。
🤫 小声提醒 🤫
关注公众号并回复「炒股源码」
获取本文辅助选股源代码!
猜想:Milvus 数据库或许可以帮助选股?
Milvus 数据库是什么?
在项目主页上,是这样介绍 Milvus 的:Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。你可以使用 Milvus 向量数据库搭建符合自己场景需求的向量相似度检索系统,比如图片检索系统、视频检索系统、音频检索系统、分子式检索系统、推荐系统、智能问答机器人、DNA 序列分类系统、文本搜索引擎……
那么 Milvus 向量数据库就只能做这些事情么?
Milvus 向量数据库具有计算和检索向量相似度的功能,只要你能把生活中的事物用数字向量表示出来,那么,Milvus 向量数据库就能帮你在这些向量中进行模糊搜索和匹配。
股票就是一种跟数字强相关的事物。笔者不禁联想,Milvus 数据库能在股市上有所作为么?
玩过股票的人应该有体会,散户选股是件令人特别头疼的事情,各种蜡烛图、曲线、数字常常让人眼花缭乱、无所适从。而且股市里有大几千只股票,一个人根本无法看全,基本上只能关注其中几只。
股票的蜡烛图,是以每个交易日的 4 个数值(开盘价、最高价、最低价、收盘价)画出的图形。这 4 个数值就是一组数字,而一组数字在数学上可以转化成一个数字向量。分析这个向量,或许就得出些令人惊喜的结果,并且能帮助我们大幅提升分析效率!
带着这些猜想,笔者在业余时间做了一些尝试:
原理
笔者初步的想法是:假设有 n 个交易日数据,我们把每个交易日的 4 个价格展开,形成 4n 个数值,作为一条向量,它的维度就是 4n。
例如,某只股票最近 3 个交易日的数据如下:
日期 | 开盘价 | 最高价 | 最低价 | 收盘价 |
7/22/2020 | 20.82 | 21.54 | 20.53 | 21.15 |
7/23/2020 | 21.28 | 21.37 | 21.01 | 20.67 |
7/24/2020 | 20.73 | 21.35 | 20.67 | 21.25 |
那么,我们就可以把这些数据转换为一条 12 维的向量:
[20.82, 21.45, 20.53, 21.15, 21.28, 21.37, 21.01, 21.05, 20.73, 21.35, 20.67, 21.25]
如果有另一只股票,其最近 3 个交易日数据如下:
日期 | 开盘价 | 最高价 | 最低价 | 收盘价 |
7/22/2020 | 6.32 | 6.58 | 6.28 | 6.56 |
7/23/2020 | 6.3 | 6.53 | 6.26 | 6.36 |
7/24/2020 | 6.18 | 6.39 | 6.13 | 6.31 |
同样,我们可以把这些数据转换为一条 12 维的向量:
[6.32, 6.58, 6.28, 6.56, 6.30, 6.53, 6.26, 6.36, 6.18, 6.39, 6.13, 6.31]
这两只股票在这 3 个交易日里相似度是多少?我们不能直接用这两条 12 维向量做比较,因为前一只股票 20 多块,后一只 6 块多,这两条向量的模长不同,直接计算距离毫无意义。
笔者是这么处理的:我们将每条向量的 12 个数值分别减去它们的最小值,然后做归一化,再进行比对。
做这些比对有何意义呢?我们得拿出一个逻辑使得这些比对变得有意义。我们经常说股票里有“主力”、有“庄家”,这两个词可能含义不同,但他们都能决定或影响股价的涨跌。要控制股价涨跌,手里必须得有筹码,而且手里的筹码与流通股的比例越高,控制力越强。短时间内,庄家是很难获取足够的筹码的,所以庄家会有一个较长时间的吸筹,短则一两个月,长则几个月甚至一年,在这段时间里上上下下各种洗盘。在股价起飞之前,其形态或多或少有一定的规律。我们要比对的,就是这个吸筹期间的股价形态。
下一个问题是,谁跟谁比?我们是拿最近的 n 天的形态,跟历史上发生大涨之前的 n 天形态比。哪只股不重要,我们是要遍历整个市场中的每只股,看它们最近 n 天的形态,是否和历史上发生大涨之前 n 天形态相似。如果相似,那么我们有理由认为,这只股有可能近期会发生大涨。
准备工作
历史数据怎么来?可以关注“数据即服务”微信公众号(非广告),点击公众号左下角的“下载”选项可以下载到“股票历史行情”,本文下载到的历史数据是从 A 股开市到 2020 年 7 月 24 号的:
其文件格式是 xls,笔者用 Python 转换为 csv 格式。
最新数据怎么来?这要借助于一个 Python 库 Tushare(https://tushare.pro/document/2)。比如要拉取某只股票最新的数据,Python 代码如下:
import tushare
def fetch_stock(dir, stock_id, date):current_path = dir + str(date) + "/"
if not os.path.exists(current_path):os.mkdir(current_path)data = tushare.get_hist_data(stock_id, start='2010-01-01', end=str(date))
# print(data)csv_path = current_path + stock_id + ".csv"
if os.path.exists(csv_path):os.remove(csv_path)data.to_csv(csv_path, encoding="utf-8", index=True, mode='a')print('save csv:', csv_path)提取数据
下一步就是开始提取“历史上发生大涨之前的 n 天形态”了。笔者这里把 n 设为 100,也就是 100 个交易日,大约是 5 个月时间。然后把“大涨”的标准定义一下,笔者是这么定义的:在 5 个交易日里股价上涨了 40%,就认为是“大涨”,并且在大涨之前 100 天里最后 10 天的均价低于头 10 天的均价(这是因为笔者希望得到那些从底部涨起的股票)。根据这个定义,笔者在历史数据中一共找出了将近 3000 个股票,这里笔者忽略掉了 ST 股(Special treatment,财务状况或其它状况出现异常的上市公司股票股票)。
需要注意的是,在笔者之后回溯实验时发现,有些形态并不是那么有效,容易造成误判。比如,下面的一些形态就容易造成误判(有些在大涨前已经上坡一段时间),需要将这些形态的股票筛除:
经过筛选后,大约剩下不到 1000 个形态,比如下面一些:
可以看到,这些形态的股票基本上都是在股价低位起涨。
然后我们把这些 1000 条向量(400 维)输入 Milvus 数据库,因为向量数很少所以不需要建索引,暴搜就足够了。向量的 ID 怎么设比较好?为了方便观察,我们按如下方式定义向量的 ID:
股票 ID + “00” + 100 日的最后一个日期
中间加两个“0”是为了把股票 ID 和日期分开,以利于辨认。比如,我们在某只股票 000629 的历史数据中提取到 2015 年 12 月 16 号这天是大涨日,那么我们把这天的前 100 个交易日的数据转为一条向量,这条向量的 ID 就是:6290020151216
选股
我们需要写一个 Python 脚本,每天拉取股市里的最新数据。每只股票抽取最近 100 天的数据构建成一条 400 维向量,经过处理(减去最小值,归一化)后,使用 L2 的距离计算方式,在 Milvus 数据库搜索出最相似的一条向量。根据距离做排名,我们可以得到前 20 名的 20 只股票。
为了验证这个方法的有效性,笔者还做了一些回溯实验。前面我们说过,拿到的历史数据是截止到 2020 年 7 月份,那我们可以用 2020 年 8 月份之后的数据来做回溯。同样,我们可以写一个 Python 脚本遍历 2020 年 8 月份之后每一天的行情,从每天的行情里推荐出 20 只股票,分别观察它们在 5 个交易日以及 10 个交易日之后的涨幅。
比如对于 2021 年 4 月 6 日的行情,计算得到的前 5 名是:
===== 300207 : 欣旺达 ===== 1
id: 6008440020050422 distance: 101.06045532226562
===== 600340 : 华夏幸福 ===== 2
id: 0026950020170608 distance: 118.332275390625
===== 688313 : 仕佳光子 ===== 3
id: 6002730020120717 distance: 124.2621841430664
===== 603283 : 赛腾股份 ===== 4
id: 0008760020100722 distance: 134.43807983398438
===== 603920 : 世运电路 ===== 5
id: 0026280020180719 distance: 135.54197692871094它们的盈利情况是:
No.1 300207 欣旺达5 days growth: 9.86 (-0.47, 1.82, -4.4, 5.89, 7.02, )10 days growth: 11.709999999999999 (-0.47, 1.82, -4.4, 5.89, 7.02, 3.16, 0.69, -2.0, )
No.2 600340 华夏幸福5 days growth: 4.450000000000001 (10.05, -1.74, -0.29, -0.59, -2.98, )10 days growth: 6.040000000000001 (10.05, -1.74, -0.29, -0.59, -2.98, -0.61, -1.08, 3.28, )
No.3 688313 仕佳光子5 days growth: -5.04 (-0.23, -0.29, 0.59, -4.2, -0.91, )10 days growth: 2.1700000000000004 (-0.23, -0.29, 0.59, -4.2, -0.91, 5.65, 1.16, 0.4, )
No.4 603283 赛腾股份5 days growth: -12.1 (-0.42, -2.85, -2.57, -2.11, -4.15, )10 days growth: -7.239999999999999 (-0.42, -2.85, -2.57, -2.11, -4.15, 0.69, 1.72, 2.45, )
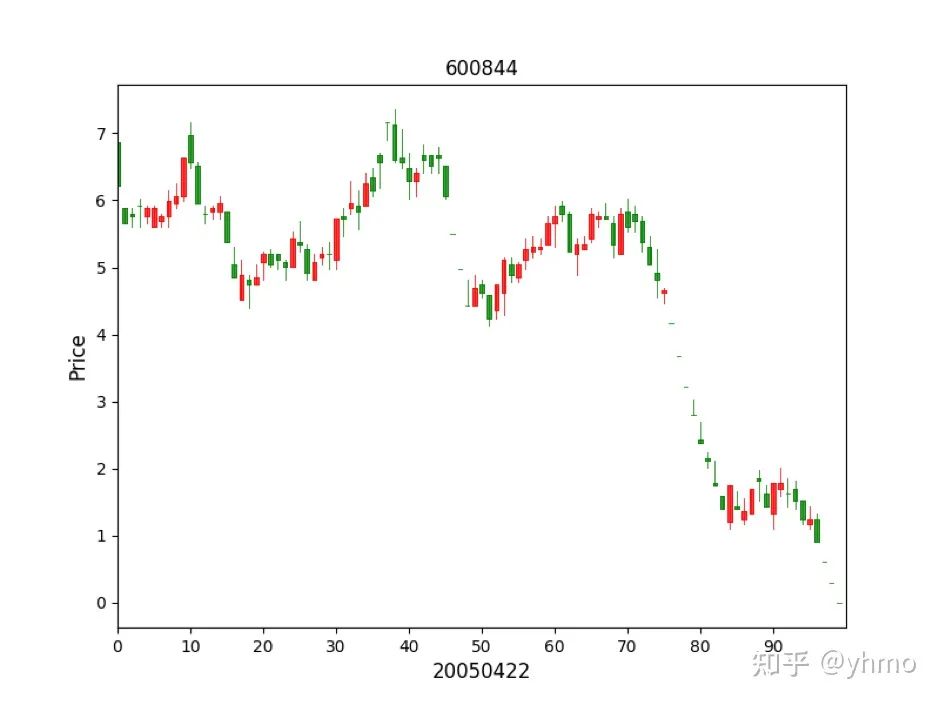
No.5 603920 世运电路5 days growth: -9.040000000000001 (-0.18, -1.58, 1.49, -4.29, -4.48, )10 days growth: 2.0599999999999987 (-0.18, -1.58, 1.49, -4.29, -4.48, 10.03, -2.28, 3.35, )对于第一名的 300207,结果显示它跟 600844 的 2005 年 4 月 22 日的前100天相似度距离为 101,后续 5 到 10 天的盈利为 10% 左右。我们先看一下 600844 的 2005 年 4 月 22 日的前 100 天(笔者使用 Python 的 mpl_finance 库以及 Matplotlib 库来绘制蜡烛图):
再来看看 300207 的 2021 年 4 月 6 号之前 100 天的行情:
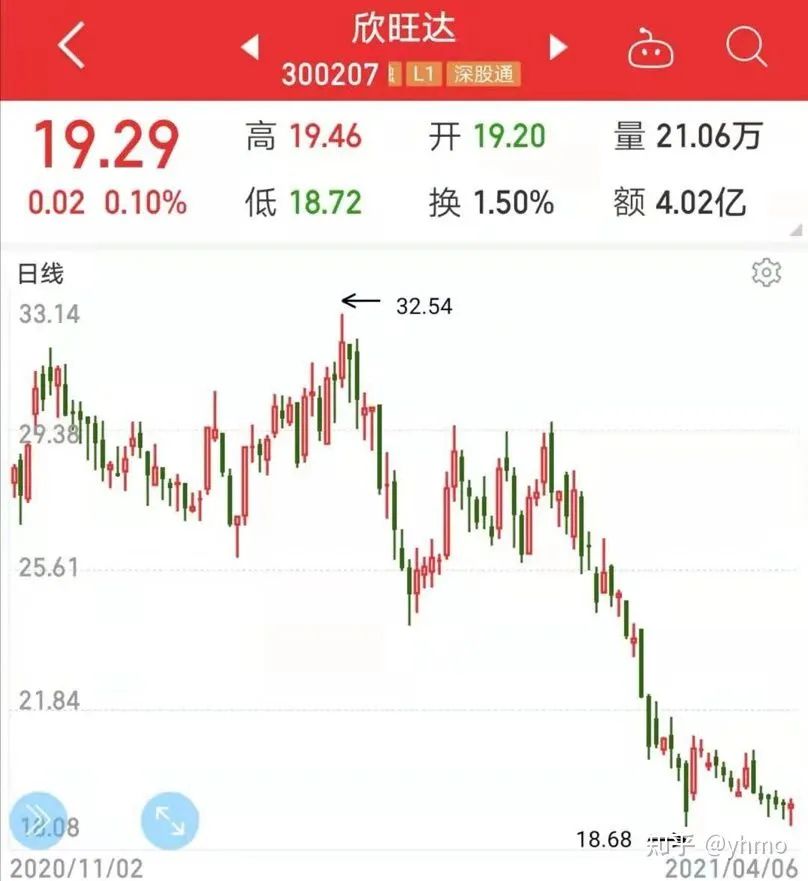
简直神似,对不对?
在回溯实验中也看到不少排名靠前,但后期却还继续下跌的股票。比如,上面第 4 名的 603283,在后续 10 个交易日里又继续下跌了 10% 左右。我们可以想到,虽然和历史上的大涨形态相似,但这只股票还没跌够,还处于下跌趋势中,我们需要根据其他的因素来判断,比如量价的变化,基本面的变化等等。
结论
总体来说,笔者的做法大致是以下几个步骤:
以某种条件定义股票大涨,根据这些条件在历史数据中提取特征 4n 维向量,输入 Milvus 数据库中;从最新的股票行情里遍历每只股票,构建近期的 4n 维向量,大约 4000 条(剔除 ST 股);对第 2 步得到的 4000 条向量,在 Milvus 数据库中搜索最相似的 Top1,只取距离最小的前若干名;对第 3 步得到的前几名若干只股票,做进一步研判。
这样的方法给出的结果并不是绝对盈利的,其最大的价值是给我们提供了一个快速遍历整个市场做比对的手段(在笔者使用了 8 年的苹果笔记本上,拉取近期行情数据大约需要十几分钟,遍历一次 4000 多只股票大约需要 4 分钟,我是一条条搜索的,如果批量搜应该快很多),它得出的结果可以作为我进一步研判的依据。
对股票感兴趣的朋友,希望这篇文章能够对他们有帮助,同时也希望 Milvus 能在这个领域有所帮助。笔者虽然研究过一段时间的股票,不过属于三脚猫的那种水平,如有不当请多担待。
注:Milvus 数据库应用面非常广泛,可以解决很多日常生活中的数字问题,不仅限于辅助选股需要注意的是,本文写于约半年前,文中推荐的五支股票现在有两支跌得很惨,所以本文并不是财经指导类文章,而是一个采用数据分析方法进行的炒股实验。欢迎大家一起探索更多 Milvus 数据库的打开方式!
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。
 解锁更多应用场景
解锁更多应用场景
这篇关于活用向量数据库,普通散户也能找到潜力股!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







