本文主要是介绍微耗算力不改结构增加准确度大法来了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
微耗算力不改结构增加准确度大法来了
CBAM: Convolutional Block Attention Module
介绍:
- 在这篇文章中,作者主要在两个卷积feature map之间增加了由(CAM) Channel Attention Module和(SAM)Spatial Attention Module构成的小shortcut类似的网络,虽然使得网络变宽了,但是计算量在大多数情况下是可以忽略不计的。而且最重要的是,这个模块是一个即插即用的模块,只要在CNN的feature map之间都是可以比较自由地添加,并不改变其他的网络结构,也不用更改其他的网络结构。
- 就本文来说,trick不多,但是做的消融实验量比较大,最重要的创新点在于它的实用性。可以不改变网络结构和不增加较大参数量的情况下增加模型的准确度。这是本文最难得的地方。
- 增加这个模块后,模型在(ImageNet-1K, MS COCO, and VOC 2007)三个数据集上都有提高。这个模型是一个具有很强实用性的模型。
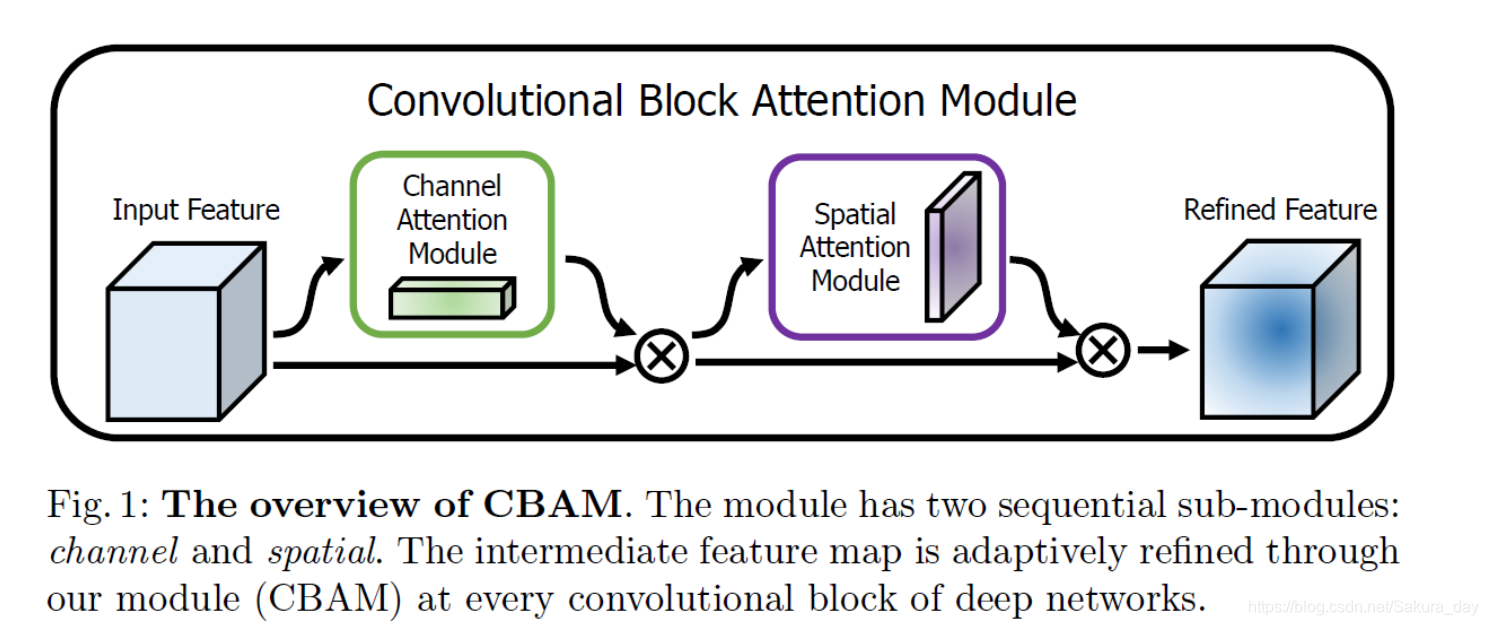
- 上图是CBAM的示意图。在图中其实就是加了两层的有进行处理的shortcut连接层,可以说是另一种形式的resnet。经过这两层的网络计算公式在下面。作者对公式的解释如下,比较清晰:
- Given an intermediate feature map F ∈ R C × H × W \operatorname{map} \mathbf{F} \in \mathbb{R}^{C \times H \times W} mapF∈RC×H×W as input, CBAM sequentially infers a 1 D 1 \mathrm{D} 1D channel attention map M c ∈ R C × 1 × 1 \operatorname{map} \mathbf{M}_{\mathbf{c}} \in \mathbb{\mathbb { R }}^{C \times 1 \times 1} mapMc∈RC×1×1 and a 2 D 2 \mathrm{D} 2D spatial attention map M s ∈ R 1 × H × W \mathbf{M}_{\mathbf{s}} \in \mathbb{R}^{1 \times H \times W} Ms∈R1×H×W as illustrated in Fig. 1. The overall attention process can be summarized as:
- F ′ = M c ( F ) ⊗ F F ′ ′ = M s ( F ′ ) ⊗ F ′ \begin{aligned} \mathbf{F}^{\prime} &=\mathbf{M}_{\mathbf{c}}(\mathbf{F}) \otimes \mathbf{F} \\ \mathbf{F}^{\prime \prime} &=\mathbf{M}_{\mathbf{s}}\left(\mathbf{F}^{\prime}\right) \otimes \mathbf{F}^{\prime} \end{aligned} F′F′′=Mc(F)⊗F=Ms(F′)⊗F′
- 为什么模型要采用这种结构呢?这是因为作者说,他经过大量实验证明,CAM在前效果会比较好,CAM和SAM串行的结果会优于并行的结果。
- 接下来我们就来看这两层具体的实现方法。
Channel Attention Module 和Spatial Attention Module的实现
CAM:
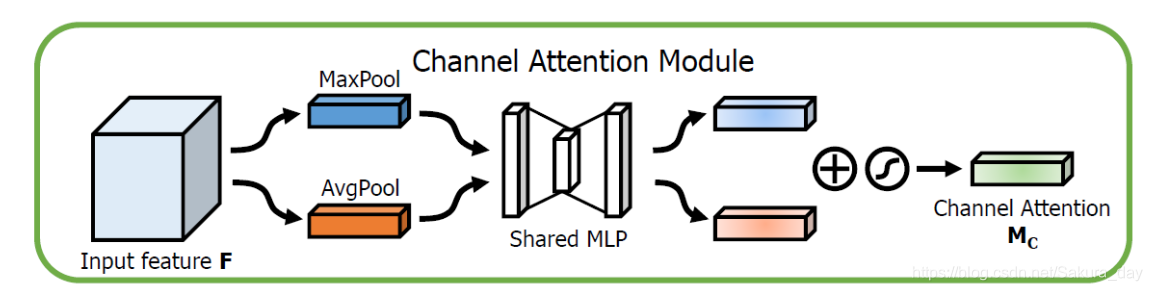
-
CAM的功能就是找到网络需要focus的重要的部分(channel维度上那个channel重要),进行高效的前向推理。先进行在通道上的最大池化和平均池化,之后进入共用的MLP(这里面有一个参数r,在论文中作者设置的值是16,它是用来确定中间的卷积特征图大小的超参数)中一起训练,得到两个feature map,最后输出之后进行相加。具体的结构如下.
-
CAM的功能是给模型一个通道上的attention参数,让模型知道自己在训练的时候要多注意哪些方面。这样能够高效地提升模型的训练精度。
SAM
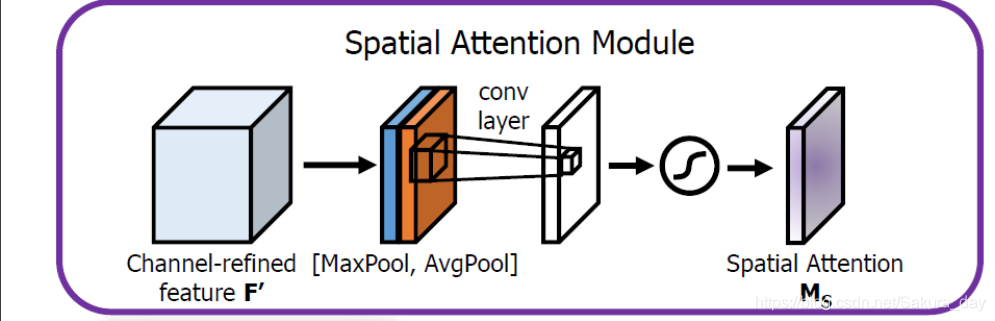
-
首先现在channel维度上进行maxpool和avgpool,先进行contact,再用一个7x7的卷积核进行卷积。计算公式如下: M s ( F ) = σ ( f 7 × 7 ( [ Avg Pool ( F ) ; MaxPool ( F ) ] ) ) = σ ( f 7 × 7 ( [ F avg s ; F max s ] ) ) \begin{aligned} \mathbf{M}_{\mathbf{s}}(\mathbf{F}) &=\sigma\left(f^{7 \times 7}([\operatorname{Avg} \operatorname{Pool}(\mathbf{F}) ; \operatorname{MaxPool}(\mathbf{F})])\right) \\ &=\sigma\left(f^{7 \times 7}\left(\left[\mathbf{F}_{\text {avg }}^{\mathrm{s}} ; \mathbf{F}_{\max }^{\mathbf{s}}\right]\right)\right) \end{aligned} Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favg s;Fmaxs]))
-
σ \sigma σ :sigmoid function | f 7 × 7 f^{7 \times 7} f7×7 : 7 × 7 7 \times 7 7×7.卷积核,默认有padding。
-
这个功能是让模型知道空间上应该注意的地方,用原文的话来说就是:where to focus。为什么使用7x7的卷积核呢,作者做实验得到,使用大的卷积核能够使得结果更好,也就是说,在空间注意力机制的网络设计上,需要用到更大的卷积核,使得模型有更大的感受野。
-
当然这个方法用1x1卷积改变通道数也是可以实现的,但是,在实验中,作者说效果不如用avg和max好
使用的具体图像:
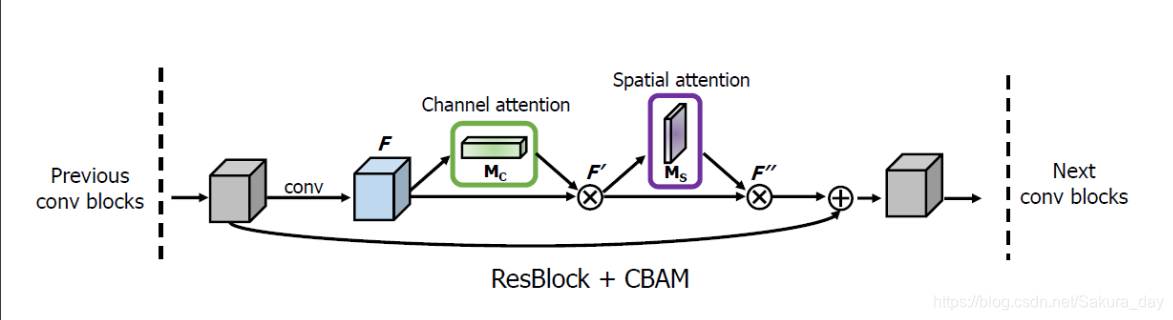
-
作者在resnet中间加入了这些模块进行实验。在模块中,进行CAM得到的Attention和原来的feature map按照channel维度相乘之后,再进行SAM。SAM得到的空间结果继续和F’相乘。最后才和shortcut连接。
-
在实验的时候作者应该是每个resnet block都加了这个东西。经过实验得到,加上CBAM之后模型的错误率都有下降。
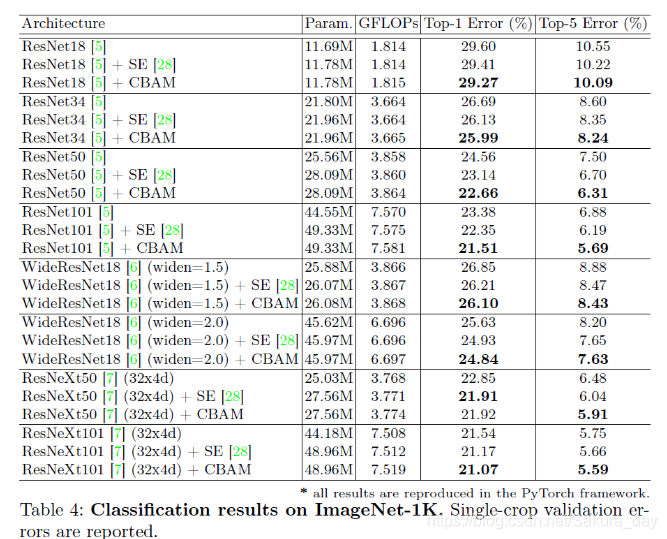
-
作者还用CBAM和SE Net在MobileNet上进行对比实验,CBAM增加的参数量和SE Net增加的参数量基本一致,但是,准确率却提升了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgdMPoHI-1615826089112)(C:\Users\sakura\Desktop\奋斗吧cv\名企课\week16\Snipaste_2021-03-09_15-28-33.png)]](https://img-blog.csdnimg.cn/20210316003701428.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1Nha3VyYV9kYXk=,size_16,color_FFFFFF,t_70)
结果可视化
- 作者在进行结果可视化的时候用了Grad-CAM的方法。通过这个方法,把Attention机制输出的feature map输出成热力图进行比对。在进行判定baseline和加了CBAM的方法哪个好的时候,作者采用了选一些人来投票的方法,得到CBAM效果比较好,当然,确实CBAM的效果会好些。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DoMM9l4L-1615826089113)(C:\Users\sakura\Desktop\奋斗吧cv\名企课\week16\Snipaste_2021-03-09_15-33-49.png)]](https://img-blog.csdnimg.cn/20210316003712991.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1Nha3VyYV9kYXk=,size_16,color_FFFFFF,t_70)
以上是得到的output图片,确实得到的注意力会集中一些。
额外的实验
-
作者还在coco数据集上进行测试,采用了Resnet50作为backbone和Fast-RCNN作为功能头进行检测。backbone加了CBAM的效果都提升了2个百分点甚至以上
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N6Nr4Q6n-1615826089114)(C:\Users\sakura\Desktop\奋斗吧cv\名企课\week16\Snipaste_2021-03-09_15-36-42.png)]](https://img-blog.csdnimg.cn/2021031600372572.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1Nha3VyYV9kYXk=,size_16,color_FFFFFF,t_70)
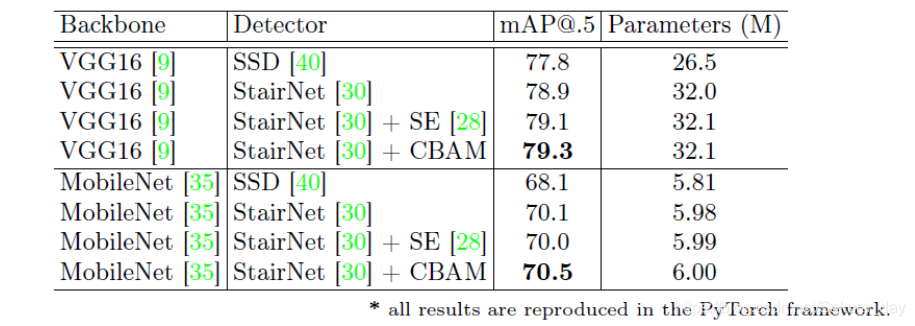
-
本文参考文献:
Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.
这篇关于微耗算力不改结构增加准确度大法来了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







