本文主要是介绍Kafka简单入门02——ISR机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
ISR机制
ISR 关键概念
HW和LEO
Java使用Kafka通信
Kafka 生产者示例
Kafka 消费者示例

ISR机制
Kafka 中的 ISR(In-Sync Replicas)机制是一种用于确保数据可靠性和一致性的重要机制。ISR 是一组副本,它包括分区的领导者(Leader)和追随者(Follower)副本,这些副本与领导者保持数据同步。
ISR 关键概念
-
领导者和追随者:每个分区有一个领导者和零个或多个追随者。领导者负责处理客户端的写请求,而追随者主要用于数据复制。
-
ISR 集合:ISR 集合是分区领导者的一组追随者副本,它们与领导者保持数据同步。只有在 ISR 集合中的追随者副本可以参与数据的写入和读取操作。
-
数据复制:领导者将消息写入其本地日志,并定期将这些消息发送给 ISR 集合中的追随者。追随者接收消息后,将其写入本地日志,以保持数据同步。
-
Leader Epoch 和 Log Start Offset:ISR 集合中的每个追随者都维护了领导者的日志信息,包括领导者的 Leader Epoch 和 Log Start Offset。这些信息用于确保数据的正确复制和同步。
-
数据一致性:只有在 ISR 集合中的所有追随者都成功复制了一条消息后,领导者才会将该消息标记为已提交,确保数据的一致性。
-
故障处理:如果某个追随者发生故障或者追赶进度过慢,那么该追随者可能会被从 ISR 集合中移除。这有助于保持数据的可靠性和避免影响性能。
其中,需要注意的的概念:
-
分区中的所有副本统称为AR(Assigned Replicas)。
-
所有Leader副本加上和Leader副本保持同步的Follower副本组成ISR(In-Sync Replicas)。
-
所有没有保持同步的Follower副本组成OSR(Out-of-Sync Replicas)。
-
AR = ISR + OSR。正常情况下,所有Follower副本都应该和Leader副本一致,即AR=ISR。
-
当Leader故障时,在ISR集合中的Follower才有资格被选举为新的Leader。
HW和LEO
在 Kafka 中,HW(High Watermark)和 LEO(Log End Offset)是与数据复制和消费有关的两个重要概念。
HW(High Watermark):HW 是指在分区中,已经被所有追随者(Follower)副本复制的消息的位置。HW 是每个分区的属性,它表示已经提交的消息。只有在 HW 之前的消息才被认为是已经提交的,这些消息已经被写入分区的所有追随者副本,并且被认为是安全的,不会丢失。HW 是为了确保数据一致性和可靠性而引入的。
LEO(Log End Offset):LEO 是指在分区中当前最新消息的位置。LEO 表示分区日志中的最后一条消息的偏移量。LEO 包括已经被写入但尚未被所有追随者副本复制的消息,以及正在等待被写入的消息。LEO 是一个动态的属性,它会随着新消息的写入而逐渐增加。
HW 和 LEO 之间的关系非常重要,它们可以帮助确保数据的可靠性和一致性:
-
HW 之前的消息是已经提交的消息,它们在数据复制中是安全的,不会丢失。
-
LEO 之前的消息是已经写入但尚未被所有追随者副本复制的消息。这些消息可能会在 HW 之前被提交,也可能会在之后被提交。
-
一旦 HW 追赶上 LEO,表示所有的消息都已经提交,分区的数据一致性得到了保障。
Kafka的消息同步流程:
-
初始状态,HW和LEO在同一位置。消费者可以读取的有效消息为0,1,2,3.

-
消息写入Leader,LEO位置改变。Follower进行同步。

-
Follower同步进度决定HW位置,消费者可读的有效消息0,1,2,3,4。
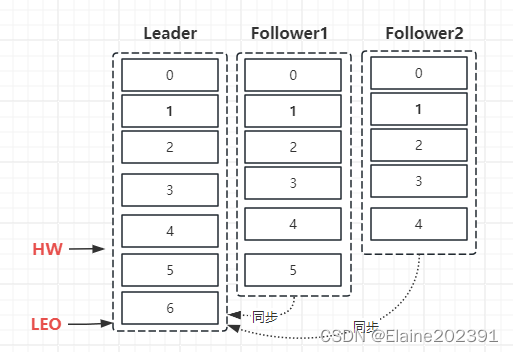
-
完成同步,消费者可读的有效消息0,1,2,3,4,5,6。
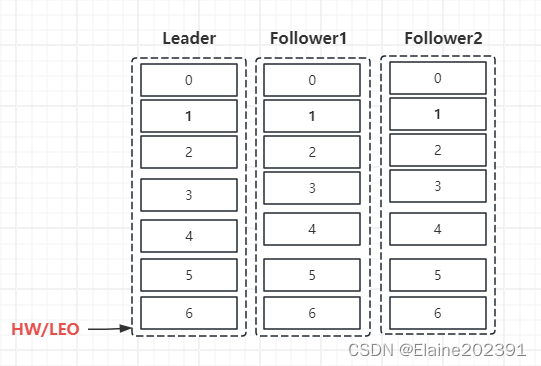
可以看出,Kafka的复制机制既不是完全的同步复制,也不是单纯异步复制。
-
同步复制要求所有Follower副本都复制完,太影响性能了。
-
异步复制只要数据被写入Leader副本就认为提交成功,在这种情况下,如果Leader宕机时候Follower还是落后于Leader就会造成数据丢失。
而Kafka使用的ISR机制则有效地权衡了数据可靠性和性能之间的关系。
Java使用Kafka通信
以下是 Kafka 生产者和消费者的简单示例,使用 Kafka 的 Java 客户端库(Kafka Producer 和 Kafka Consumer)来创建一个基本的消息传递示例。
Kafka 生产者示例
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerExample {public static void main(String[] args) {String bootstrapServers = "localhost:9092"; // Kafka 服务器地址String topic = "my-topic"; // Kafka 主题名称
Properties properties = new Properties();properties.put("bootstrap.servers", bootstrapServers);properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
// 发送消息producer.send(new ProducerRecord<>(topic, "key", "Hello, Kafka!"), (metadata, exception) -> {if (exception == null) {System.out.println("Message sent to partition " + metadata.partition() + ", offset " + metadata.offset());} else {System.err.println("Error sending message: " + exception.getMessage());}});
producer.close();}
}
Kafka 消费者示例
import org.apache.kafka.clients.consumer.*;
import java.util.Properties;
import java.time.Duration;
import java.util.Collections;
public class KafkaConsumerExample {public static void main(String[] args) {String bootstrapServers = "localhost:9092"; // Kafka 服务器地址String groupId = "my-group"; // 消费者组 IDString topic = "my-topic"; // Kafka 主题名称
Properties properties = new Properties();properties.put("bootstrap.servers", bootstrapServers);properties.put("group.id", groupId);properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);consumer.subscribe(Collections.singletonList(topic));
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.println("Received message: key = " + record.key() + ", value = " + record.value());}}}
}
这篇关于Kafka简单入门02——ISR机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







