本文主要是介绍轻松带你掌握Scrapy框架(以爬取古诗文网为例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
安装Scrapy框架
- pip install scrapy。
- 可能会出现问题:
- 在ubuntu下要先使用以下命令安装依赖包:
sudo apt-get install python3-dev build-essential python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev,安装完成后再安装scrapy。 - 在windows下安装可能会提示
No module named win32api,这时候先使用命令:pip install pypiwin32,安装完成后再安装scrapy。 - 在windows下安装Scrapy可能会提示
twisted安装失败,那么可以到这个页面下载twisted文件:https://www.lfd.uci.edu/~gohlke/pythonlibs/,下载的时候要根据自己的Python版本来选择不同的文件。下载完成后,通过pip install xxx.whl
这里重点说一下第三条
登陆https://www.lfd.uci.edu/~gohlke/pythonlibs/,调出搜索框,搜索twisted,根据你的python版本进行下载(在命令提示符下输入python回车即可看到自己的python)
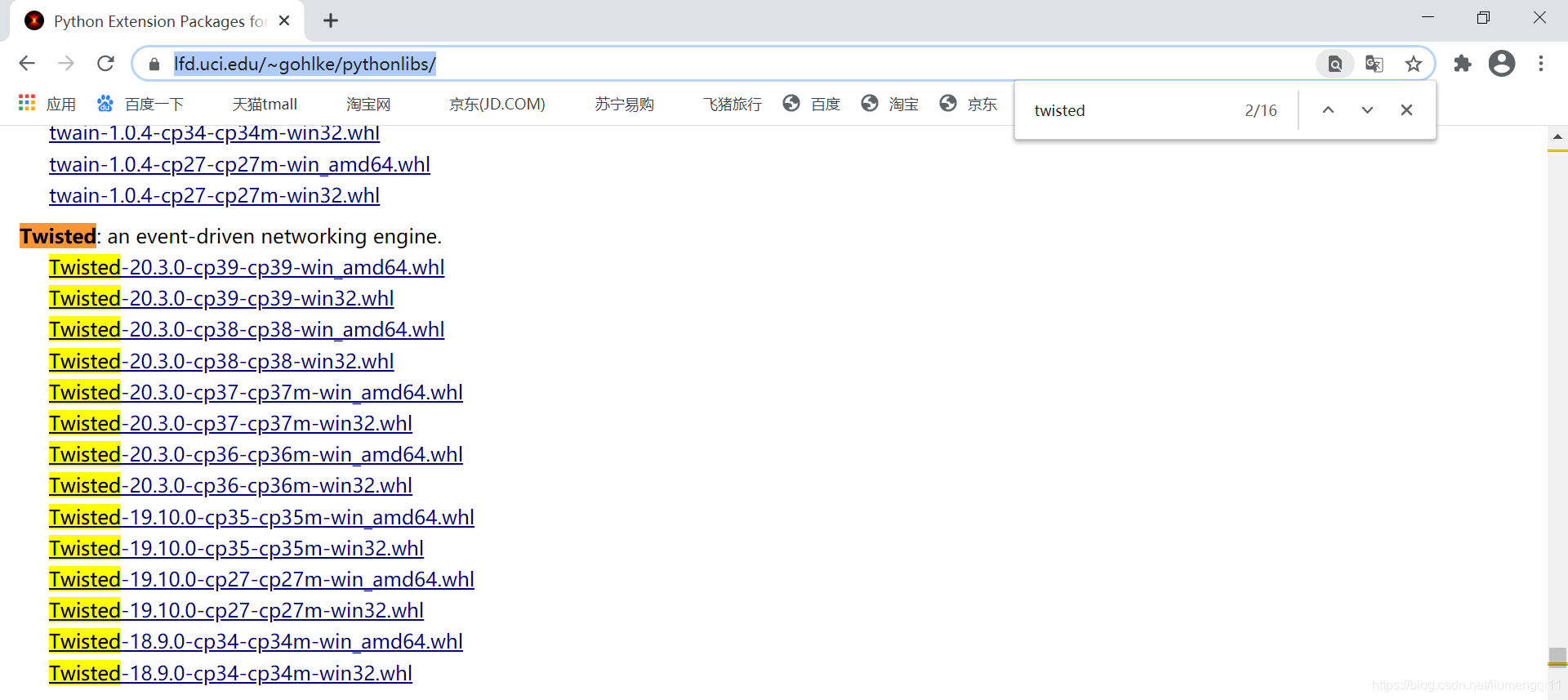
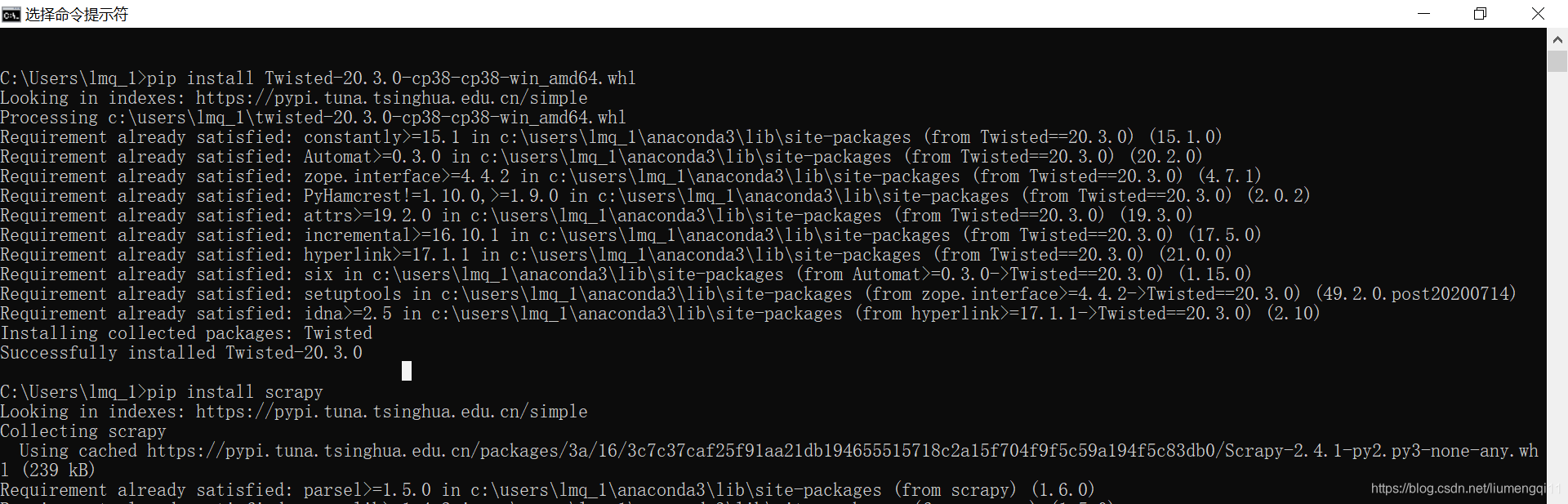
 下载完成后,在命令提示符中输入
下载完成后,在命令提示符中输入pip install xxx.whl即可
- 在ubuntu下要先使用以下命令安装依赖包:
Scrapy框架架构
- Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
创建Scrapy项目
-
创建项目:
scrapy startproject [项目名称]. -
创建爬虫:
cd到项目中->scrapy genspider [爬虫名称] [域名].#创建项目(以古诗文网https://www.gushiwen.org/为例)scrapy startproject gswwcd gswwscrapy genspider gushiwen gushiwen.org用pycharm打开gsww

项目文件作用
settings.py:用来配置爬虫的。middlewares.py:用来定义中间件。items.py:用来提前定义好需要下载的数据字段。pipelines.py:用来保存数据。scrapy.cfg:用来配置项目的。
过程
古诗文网界面如下,我们意在爬取诗名、作者、朝代、诗的内容四个变量https://www.gushiwen.cn/default_1.aspx
-
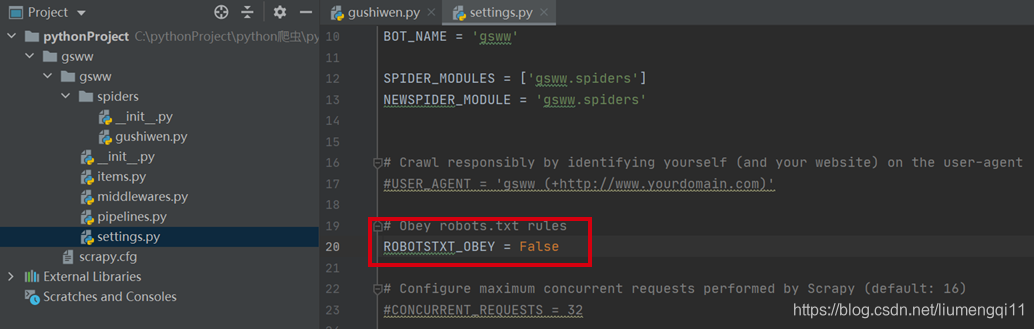
在setting.py中把机器人协议设置为False,并设置user-agent,解开ITEM_PIPELINES的注释

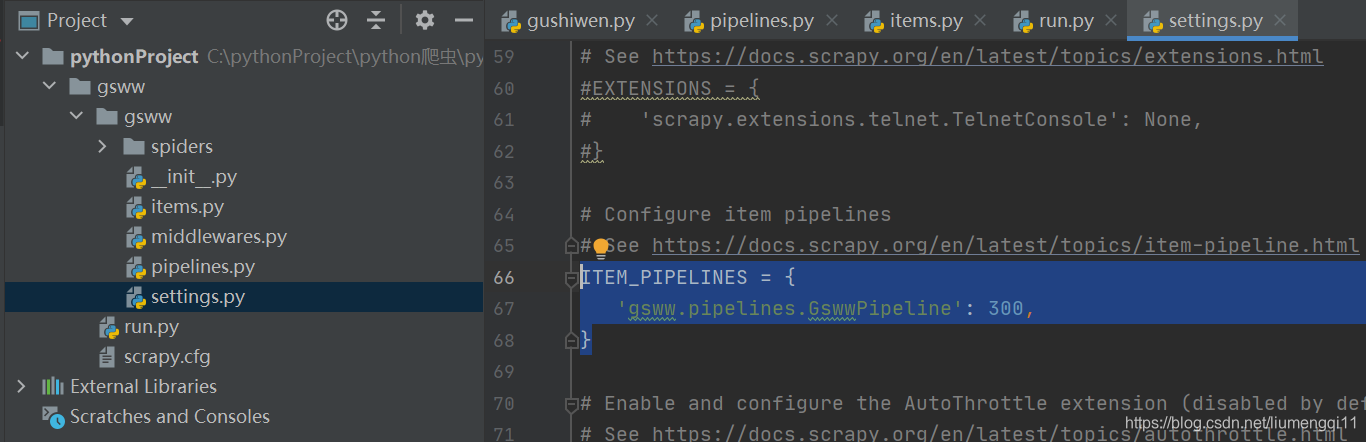
-
在gushiwen.py中更改url,并打印网页源代码测试一下看能不能正常返回
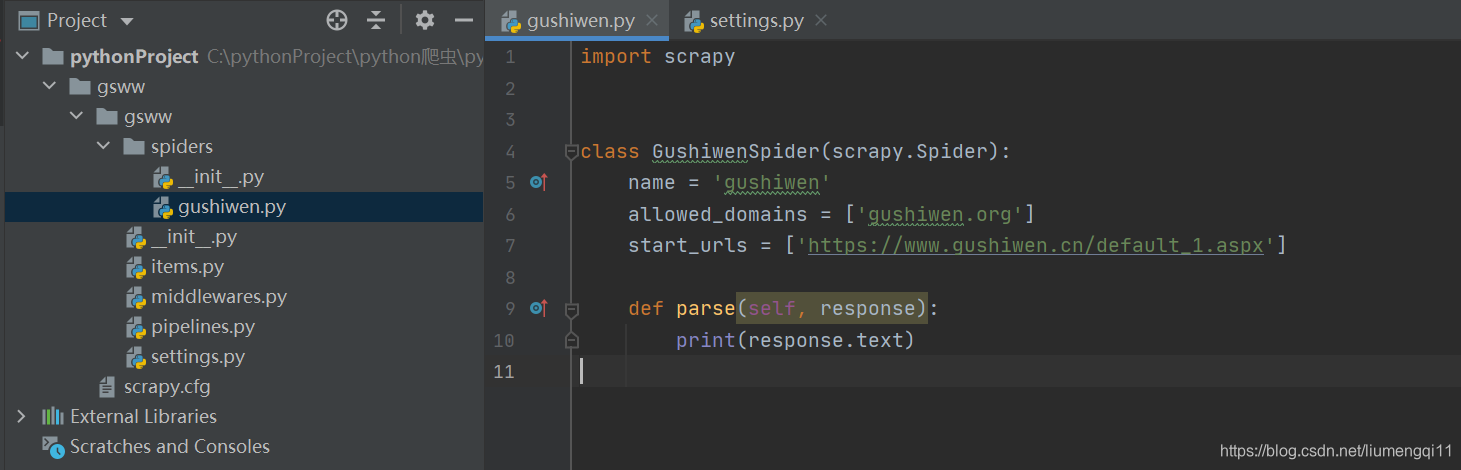
-
这是一个文件夹,在终端才能运行,在gsww目录下输入
scrapy crawl gushiwen即可返回网页源代码
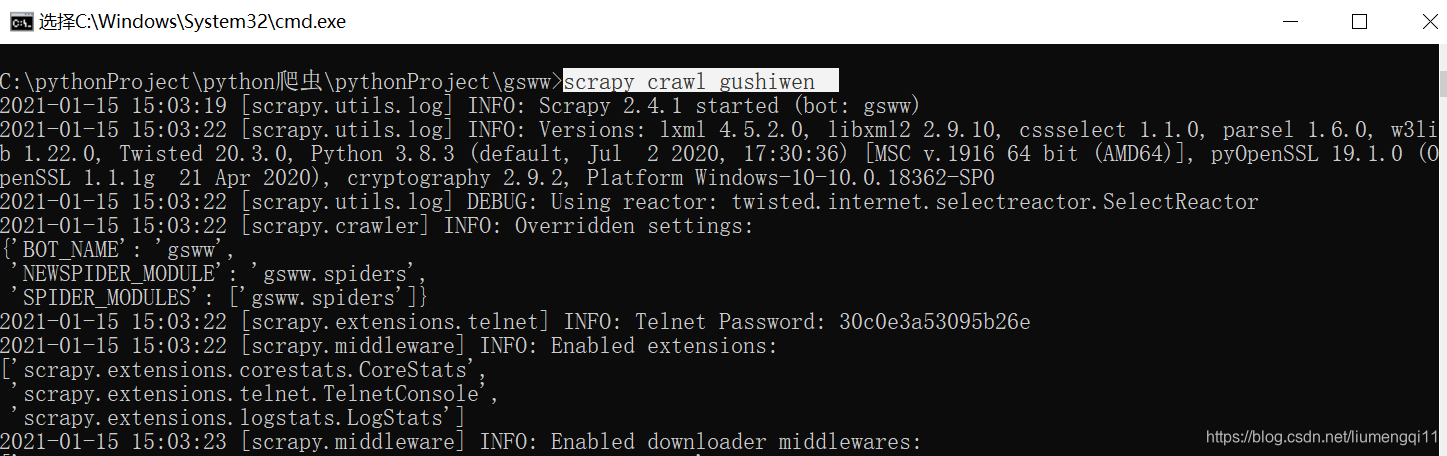
-
更改代码,看一下response是什么类型
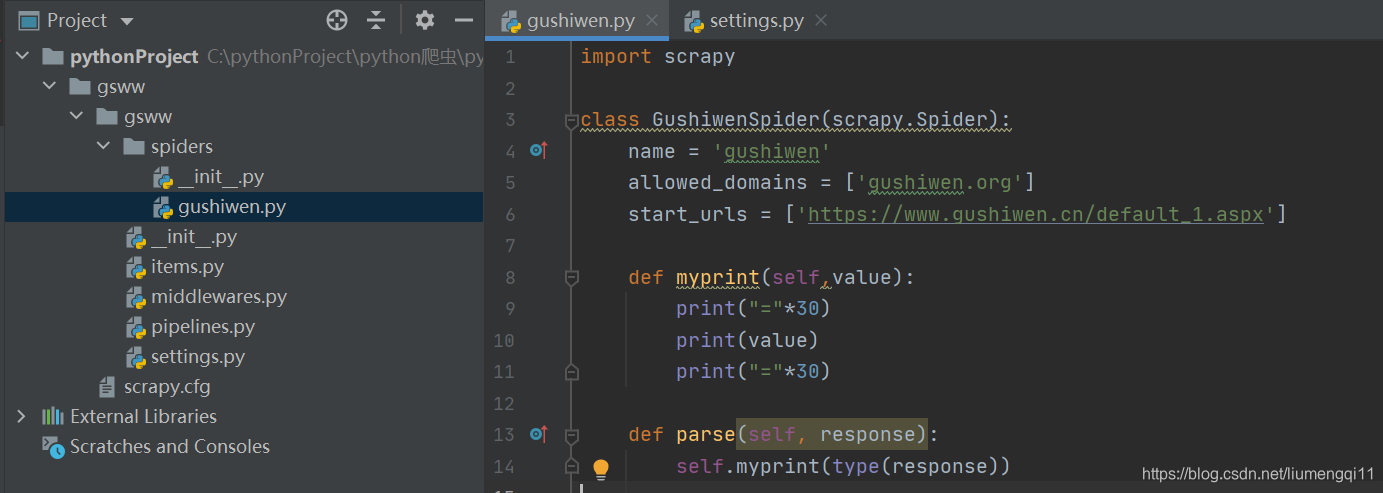
-
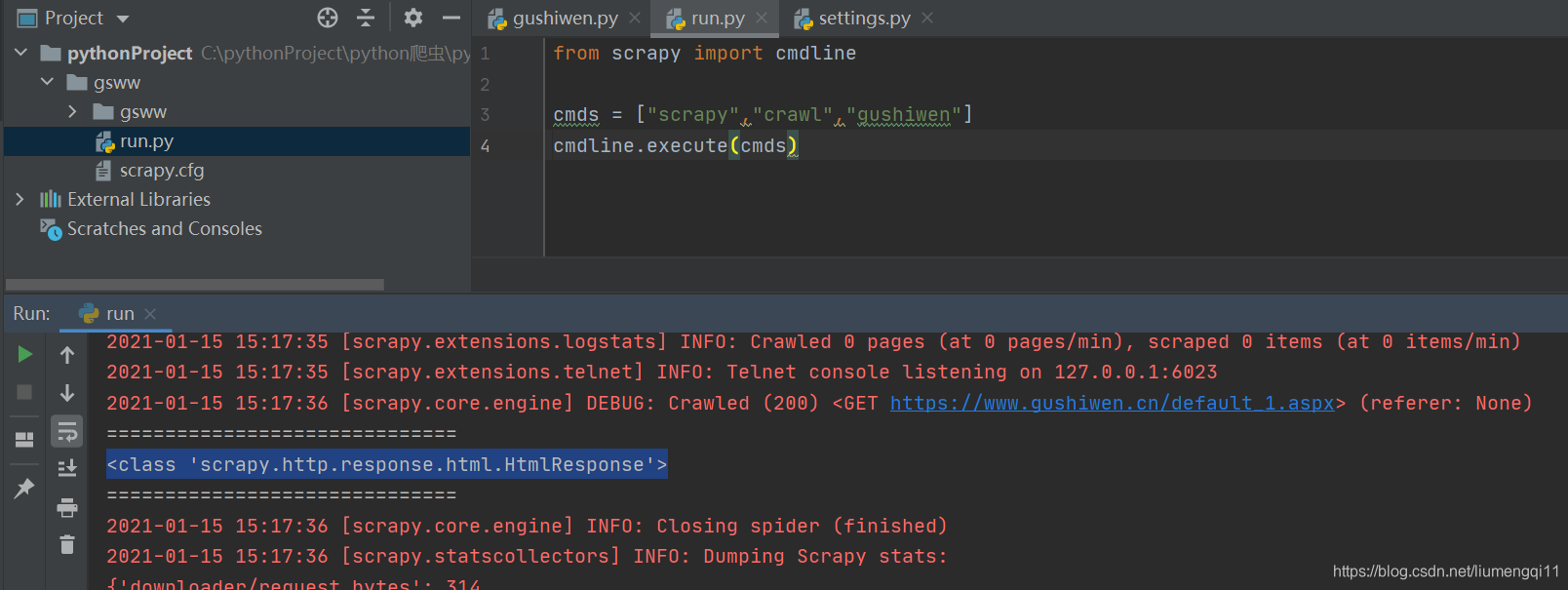
每次都在终端上运行会比较麻烦,可以在gsww下新建一个.py文件,里面写上如下代码,运行这个文件即可,这里我们看到
response是<class 'scrapy.http.response.html.HtmlResponse'>类型
-
下面就可以在gushiwen.py这个文件中写xpath语法了(需要有一定的xpath功底),这里爬取了古诗的标题、作者、作者朝代和诗的内容四个属性,同时爬取前十页。
gushiwen.py(爬虫文件)代码如下:
import scrapy
from ..items import GswwItem
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import Selectorclass GushiwenSpider(scrapy.Spider):name = 'gushiwen'allowed_domains = ['gushiwen.cn','gushiwen.org']start_urls = ['https://www.gushiwen.cn/default_1.aspx']def myprint(self,value): # 为了输出美观print("="*30)print(value)print("="*30)def parse(self, response):# self.myprint(type(response)) #<class'scrapy.http.response.html.HtmlResponse'># 用xpath进行提取gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']")# self.myprint(type(gsw_divs)) # <class 'scrapy.selector.unified.SelectorList'>for gsw_div in gsw_divs:# self.myprint(type(gsw_div)) # <class 'scrapy.selector.unified.Selector'># SelectorList:里面存储的都是Selector对象# SelectorList.getall:可以直接获取xpath中指定的值# SelectorList.get:可以直接提取第一个值try:title = gsw_div.xpath(".//b/text()").getall()[0]source = gsw_div.xpath(".//p[@class='source']/a/text()").getall()dynasty = source[1]author = source[0]# 下面的//text()代表的是获取class='contson'下的所有子孙文本content_list = gsw_div.xpath(".//div[@class='contson']//text()").getall()content = "".join(content_list).strip()item = GswwItem(title=title, dynasty=dynasty, author=author, content=content)yield itemexcept:self.myprint(gsw_div)# 为了爬取多页next_href = response.xpath("//a[@id='amore']/@href").get()if next_href:next_url = response.urljoin(next_href)request = scrapy.Request(next_url)yield request
item.py(定义字段)代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy
class GswwItem(scrapy.Item):title = scrapy.Field()dynasty = scrapy.Field()author = scrapy.Field()content = scrapy.Field()
pipelines.py(保存数据)代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import jsonclass GswwPipeline:def open_spider(self,spider):self.fp = open("古诗文.txt",'w',encoding="utf-8")def process_item(self, item, spider):self.fp.write(json.dumps(dict(item),ensure_ascii=False)+'\n')return itemdef close_spider(self,spider):self.fp.close()
爬取结果如下:
 掌握Scrapy框架的核心是要清楚左边的每一个文件的用途,再对文件做出适当修改,就可以了。♥♥♥希望对大家有所帮助♥♥♥
掌握Scrapy框架的核心是要清楚左边的每一个文件的用途,再对文件做出适当修改,就可以了。♥♥♥希望对大家有所帮助♥♥♥
这篇关于轻松带你掌握Scrapy框架(以爬取古诗文网为例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





