本文主要是介绍Weights and Biases使用教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Weights and Biases使用教程
- 安装和初始化
- 实验跟踪
- 跟踪指标
- 跟踪超参数
- 可视化模型
- 检查日志
- 数据和模型版本控制
- 使用Sweeps进行超参数调优
- 数据可视化
- report
Weights and Biases已经成为AI社区中最受欢迎的库之一。该团队在创建了一个平台,使机器深度学习学习工程师能够轻松地:
- 跟踪实验
- 可视化训练过程
- 与团队共享结果
- 改进模型性能
下面我将结合一个示例来介绍如何使用wandb库。我们将使用一个标准的深度学习模型,在CIFAR10数据集上执行图像识别。需要注意的是,模型的具体细节并不会对我们的实验产生真正的影响,因此我选择保持模型尽可能简单。我们将从头开始训练这个模型,以探索如何充分利用wandb库
以下是模型的PyTorch代码以及数据处理的部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
第一步是安装该库并创建一个新账户。
安装和初始化
如果你还没有账户,你需要创建一个新账户才能使用Weights and Biases。该库个人使用是免费的,但对于团队使用则需要每月付费。你可以访问该网站并注册。
地址:https://wandb.ai/site
一旦注册完成,你可以使用pip或conda来安装该库。安装完成后,你需要进行身份验证。这可以通过使用"wandb login"命令来完成。系统将提示你复制粘贴一个授权密钥以继续操作。
$ conda install -c conda-forge wandb$ wandb login
该库可以在我们的代码中使用init方法进行初始化,该方法接受一个可选的项目名称和您的用户名,以及其他参数。
import wandbwandb.init(project='test', entity='serkar')
现在我们已经设置好了,让我们尝试将该库集成到我们的训练循环中。
实验跟踪
wandb库的主要用途是跟踪和可视化不同的机器学习实验、训练过程、超参数和模型。让我们看一些示例。
跟踪指标
Weights and Biases(W&B)库的惊人之处在于它的易用性。在许多情况下,实际上只需要一行代码:
wandb.log({'epoch': epoch, 'loss': running_loss})
′ . l o g ( ) ′ '.log()' ′.log()′命令将捕获所有参数并将它们发送到W&B实例,这将允许我们从用户界面访问和跟踪它们。你可以在W&B网站的项目下找到仪表板。
在应用程序中,一个示例的训练循环可能如下所示:
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))wandb.log({'epoch': epoch+1, 'loss': running_loss/2000})running_loss = 0.0print('Finished Training')
你是否注意到了wandb.log这一行?通过这种方式,我们可以实时查看训练过程。结果会如下所示:

还有另一个命令也可以使用,那就是wandb.watch,它会自动收集模型的梯度和模型的拓扑结构。
wandb.watch(net, criterion, log="all")
除了已定义的指标,我们还可以跟踪许多其他有用的内容,比如可训练参数。

或者梯度:

另一个功能是系统仪表板。在那里,可以检查我们的硬件以及在训练过程中不同组件的行为。例如,可以检查CPU、GPU、内存利用率、功耗、温度等等。

每次执行训练脚本时,都会创建一个新的“运行”并添加到项目的历史记录中。每个“运行”包含不同的元数据的已记录信息。当然,我们可以在单个仪表板中探索所有不同的运行。

跟踪超参数
除了指标,W&B还有另一个很好的功能,可以让我们跟踪训练的超参数。wandb.config对象用于保存训练配置,如超参数。但它不仅限于超参数。我们基本上可以存储我们想要的任何信息。示例包括:数据集名称、模型类型和标志。
可以像这样初始化一个配置:
config = wandb.config
config.learning_rate = 0.01
config.momentum = 0.9
对于复杂的配置,我们还可以使用一个yaml文件或一个Python字典。
所有这些值都可以用于分析实验并重现结果。在下面的仪表板中,我们可以看到五个“运行”以及它们的超参数。请注意,我们可以使用配置值对它们进行分组、筛选或排序。
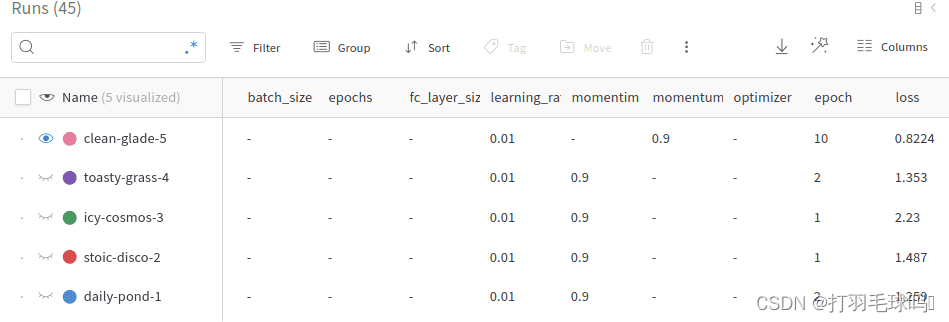
可视化模型
如果我们使用前面提到的watch命令,我们还可以在模型仪表板中检查模型的拓扑结构。在我们的情况下,模型将如下所示:
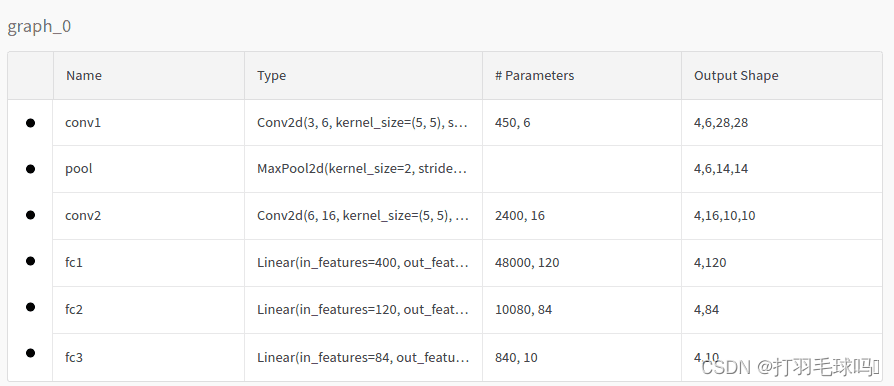
检查日志
对于本地控制台中打印的实际日志也是如此:
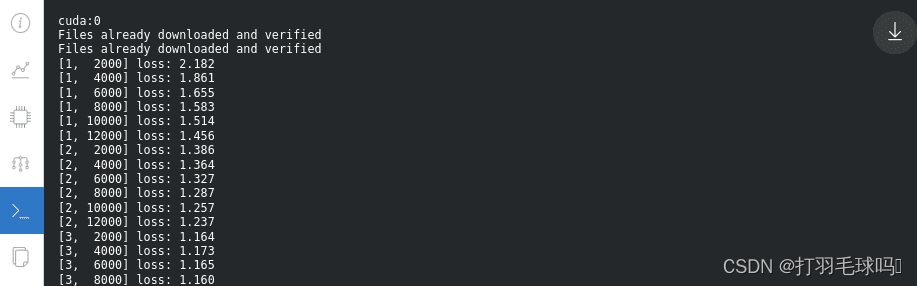
数据和模型版本控制
除了实验跟踪,W&B还具有内置的版本控制系统。Artifact是实现这一目标的主要实体。Artifacts支持数据集版本控制、模型版本控制和依赖跟踪。
Artifact实际上就是一个经过版本控制的数据文件夹。让我们使用我们的项目来看一个示例。为了对我们的数据集进行版本控制,我们只需要创建一个Artifact并上传它。
cifar10_artifact = wandb.Artifact("cifar10", type="dataset")
file_path = './data/cifar-10-batches-py'
cifar10_artifact.add_dir(file_path)
run.log_artifact(cifar10_artifact)
你可以想象,类似的操作也可以用于对模型或依赖项进行版本控制。值得一提的是,我们可以创建一个具有对象的外部引用的Artifact,而不是使用整个数据集,如下所示:
artifact.add_reference('s3://my-bucket/my_dataset)
下载并在我们的代码中使用已上传的Artifact也很简单:
artifact = run.use_artifact('cifar10_artifact')
artifact_dir = artifact.download()

使用Sweeps进行超参数调优
Weights & Biases Sweeps是一种自动化超参数优化和探索工具。它消除了大部分样板代码,并提供了非常好的可视化效果。让我们探讨如何在我们的项目中使用Sweeps。
在我们的用例中,我们想要调整4个不同的参数:模型中最后一个线性层的大小、批处理大小、学习率和优化算法。为了实现这一点,我们首先需要创建一个包含不同选项的配置。以下是一个示例配置:
sweep_config = {'method': 'random','metric': {'goal': 'minimize', 'name': 'loss'},'parameters': {'batch_size': {'distribution': 'q_log_uniform','max': math.log(256),'min': math.log(32),'q': 1},'epochs': {'value': 5},'fc_layer_size': {'values': [128, 256, 512]},'learning_rate': {'distribution': 'uniform','max': 0.1,'min': 0},'optimizer': {'values': ['adam', 'sgd']}}}
首先,我们定义调优方法,即搜索策略。我们有三种选项:随机搜索、网格搜索和贝叶斯搜索。度量标准是应该最小化的最终目标。最后,参数是Sweeps要搜索的超参数。正如你所看到的,我们将调整以下参数:
- 批处理大小在[log(32), log(256)]范围内。批处理大小的选择将遵循分段对数均匀分布。还有其他选择可用。
- 训练周期数始终为5。
- 最后一个线性层的大小为128、256或512。
- 学习率在[0, 0.1]范围内,遵循均匀分布。
- 优化器为SGD或Adam。
Sweeps将尝试所有不同的组合,并计算每个组合的损失。可以使用以下方式初始化Sweeps:
sweep_id = wandb.sweep(sweep_config, project="test")
然后,训练循环应该被修改以读取预定义的配置。请看下面的代码:
def train(config=None):with wandb.init(project='test', entity='serkar', config=config):config = wandb.configtransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=config.batch_size,shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)net = Net(config.fc_layer_size)net.to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=config.learning_rate)if config.optimizer == "sgd":optimizer = optim.SGD(net.parameters(),lr=config.learning_rate, momentum=0.9)elif optimizer == "adam":optimizer = optim.Adam(net.parameters(),lr=config.learning_rate)wandb.watch(net, criterion, log="all")for epoch in range(config.epochs): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / len(trainloader)))wandb.log({'epoch': epoch + 1, 'loss': running_loss / len(trainloader)})print('Finished Training')
这里需要注意两件事:
- 训练循环被包装在with wandb.init(project=‘test’, entity=‘serkar’, config=config)中。这是将W&B库与我们的代码绑定的另一种方式。
- 我们使用config = wandb.config读取配置,然后将每个参数传递到训练代码中。我们必须确保所使用的超参数来自配置文件,以便Sweeps能够正确执行。
最后,我们可以使用以下命令执行调优。
wandb.agent(sweep_id, function=train, count=5)
这会指示Sweeps运行train函数,只选择5个随机的超参数组合来运行。结果如下所示:

注意,我们得到了以下一组最佳超参数的最佳结果:
- 批处理大小 = 55
- 线性层大小 = 256
- 学习率 = 0.02131
- 优化器 = SGD
使用这组组合,损失值降到了0.003。
另一个非常酷的图表如下:

在这里,我们分析哪些参数对损失影响最大以及它们的影响方式。这被称为超参数重要性图,它指示哪些超参数是我们指标的最佳预测因子。特征重要性是使用随机森林模型派生的,相关性是使用线性模型计算的。
数据可视化
我真正喜欢的另一个功能是数据可视化。W&B让我们定义一个数据表,并在平台上可视化它。表格可以包括几乎任何内容:数据,如图像、文本或音频,梯度,可训练参数等。除了可视化,我们还可以过滤、排序、分组,总之可以探索数据。
为了让这一点更清楚,我们将提供一个简单的示例。让我们创建一个小表格,其中包含来自我们数据的第一个批次的所有图像及其标签。可以使用wandb.Table类来创建表格。为了同步表格,我们需要记录它。
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')columns=['image','label']
data = []for i, batch in enumerate(trainloader, 0):inputs, labels = batch[0], batch[1]for j, image in enumerate(inputs,0):data.append([wandb.Image(image),classes[labels[j].item()]])breaktable= wandb.Table(data=data, columns=columns)
run.log({"cifar10_images": table})
请注意,我们使用了内置的wandb.Image数据类型,以便我们可以预览图像。一旦运行上述代码,我们就可以在仪表板中查看我们的表格。

你可以想象,使用相同的逻辑,我们几乎可以可视化任何东西。
report
最后,我想通过一个更加面向团队的功能来结束这个教程。报告。报告使我们开发人员能够组织不同的可视化内容,传达我们的结果并记录我们的工作。
W&B提供了一个具有丰富功能的所见即所得编辑器。它支持文本、代码片段的markdown和latex,以及各种其他图表。示例包括线图、柱图、散点图等。团队正在努力添加更多功能,比如嵌入视频、html、音频等。

这篇关于Weights and Biases使用教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







