本文主要是介绍Python 升级之路( Lv3 ) 序列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python系列文章目录
第一章 Python 入门
第二章 Python基本概念
第三章 序列
序列
- Python系列文章目录
- 前言
- 一、序列是什么
- 二、列表
- 介绍
- 操作
- 访问 & 计数
- 常见用法
- 多维列表
- 三、其他序列类型
- 元组
- 介绍
- 操作
- 字典
- 介绍
- 操作
- 字典核心底层原理(重要)
- 集合
- 介绍
- 操作
- 四、思考
前言
本章主要主要讲述什么是序列, 以及序列的几种类型: 列表, 元组, 字典, 集合等
熟悉相关概念以及操作方式(创建, 修改, 删除, 查询). 注意他们之间的使用区别并在不同情况下选取合适的序列
一、序列是什么
序列是一种数据存储方式,用来存储一系列的数据。
在内存中,序列就是一块用来存放多个值的连续的内存空间。
比如一个整数序列[10,20,30,40],示意表示:
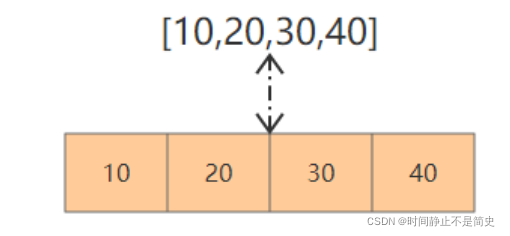
序列分类
序列可分为以下五类:
- 列表
- 元组
- 字典
- 集合
- 字符串序列
特别注意
序列类似Java中的集合的概念, 但是, 序列中的集合和Java中的集合却不一样 (约等于Java中的list 集合).
二、列表
介绍
列表:用于存储任意数目、任意类型的数据集合。
列表是内置可变序列,是包含多个元素的有序连续的内存空间。
特点: 有序, 可变, 中括号[]
列表的标准语法格式:a = [10,20,30,40] . 其中,10,20,30,40这些称为:列表a的元素。
注意:
- 字符串和列表都是序列类型,一个字符串是一个字符序列,一个列表是任何元素的序列。
- 前面学习的很多字符串的方法,在列表中也有类似的用法,几乎一模一样。
操作
列表的创建
- 使用list()可以将任何可迭代的数据转化成列表
- range()创建整数列表
- 推导式生成列表
# 列表:用于存储任意数目、任意类型的数据集合
# list()创建
import randoma = [10086, 10010, 10000, "中国移动", "中国联通", "中国电信"]
b = [] # 创建一个空列表对象
print(a)
print(b)# list()创建
# 使用list()可以将任何可迭代的数据转化成列表
a = list()
b = list(range(9))
c = list("中国移动,10086")
print(a)
print(b) # [0, 1, 2, 3, 4, 5, 6, 7, 8]
print(c) # ['中', '国', '移', '动', ',', '1', '0', '0', '8', '6']# range()创建整数列表
# range()可以帮助我们非常方便的创建整数列表,这在开发中极其有用. 语法格式为:range([start,] end [,step])
# start参数:可选,表示起始数字。默认是0
# end参数:必选,表示结尾数字
# step参数:可选,表示步长,默认为1
a = list(range(3, 15, 2)) # 结果:[3, 5, 7, 9,11, 13]
b = list(range(15, 9, -1)) # 结果:[15, 14, 13,12, 11, 10]
c = list(range(3, -4, -1)) # 结果:[3, 2, 1, 0,-1, -2, -3]
print(a, b, c)# 推导式生成列表
# 使用列表推导式可以非常方便的创建列表,在开发中经常使用
a = [x * 2 for x in range(5)]
# #通过if过滤元素[0, 18, 36, 54, 72, 90, 108, 126, 144, 162, 180, 198]
b = [x * 2 for x in range(100) if x % 9 == 0]
print(a, b)
列表的新增
- append()方法( 速度最快, 推荐使用 )
+运算符操作 ( 生成新对象 )- extend()方法 ( 尾插, 不生成新对象 )
- insert()插入元素 ( 插入到指定位置, 慎用 )
- 使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复
# 列表元素的增加
# 1. append()方法 原地修改列表对象,是真正的列表尾部添加新的元素,速度最快,推荐使用
a = [20, 40] # 此列表创建可以重写为列表文字
a.append(80)
print(a) # 结果:[20, 40, 80]
# 2. +运算符操作 并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中
a = [20, 40]
print("测试第一次时对象的引用: ", id(a))
a = a + [50]
print("测试第二次时对象的引用: ", id(a)) # 两次地址不一样,创建了新的对象
# 3. extend()方法 将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象
a = [20, 40]
print(id(a))
b = [50, 60]
a.extend(b) # 原对象修改
print(id(a), a)
a = a + b # 产生新对象
print(id(a), a)
# 4. insert()插入元素
# 使用 insert() 方法可以将指定的元素插入到列表对象的任意制定位置.
# 这样会让插入位置后面所有的元素进行移动,会影响处理速度. 涉及大量元素时,尽量避免使用。
a = [10, 20, 30]
a.insert(2, 100) # 在2号下标位置(起点为0)放入100
print(a) # 结果:[10, 20, 100, 30]
# 5. 乘法扩展 使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复
a = ["托尼斯塔克", "爱你三千遍"]
d = a * 30 # 3000是在太多了...
print(a)
print(d)
列表的删除:
- del() 删除列表指定位置的元素
- pop()删除并返回指定位置元素
- 删除首次出现的指定元素,若不存在该元素抛出异常
# 列表元素的删除
# 1. del删除, 删除列表指定位置的元素
a = [100, 200, 888, 300, 400]
del a[2]
print(a) # 结果:[100,200,300,400]
# 2. pop()方法
# pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素
a = [10, 20, 30, 40, 50]
b1 = a.pop() # 结果:b1=50
print(a, b1) # 结果:[10, 20, 30, 40] 50
b2 = a.pop(1)
print(a, b2) # 结果:[10, 30, 40],20
# 3.remove()方法
# 删除首次出现的指定元素,若不存在该元素抛出异常
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
a.remove(20) # [10, 30, 40, 50, 20, 30, 20,30]
print(a)
# a.remove(90) # ValueError: list.remove(x): x not in list
复制列表所有的元素到新列表对象:
# 复制列表所有的元素到新列表对象
# 只是将list2也指向了列表对象,也就是说list2和list2持有地址值是相同的. 列表对象本身的元素并没有复制。
list1 = [30, 40, 50]
list2 = list1
print(list2)
访问 & 计数
访问:
- 通过索引直接访问元素
- index()获得指定元素在列表中首次出现的索引
# 列表元素访问和计数
# 1. 通过索引直接访问元素
# 我们可以通过索引直接访问元素。索引的区间在 [0, 列表长度-1] 这个范围。超过这个范围则会抛出异常。
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
print(a[2]) # 结果:30
# print(a[10]) # 报错:IndexError: list index out of range
# 2. index()获得指定元素在列表中首次出现的索引
# index() 可以获取指定元素首次出现的索引位置。语法是: index(value,[start, [end]]) 。其中, start 和 end 指定了搜索的范围。
print(a.index(20)) # 1
print(a.index(20, 3)) # 5
print(a.index(30, 5, 7)) # 6
print(a[a.index(20)])
print(a[a.index(20, 3)])
print(a[a.index(30, 5, 7)])
计数:
- count()获得指定元素在列表中出现的次数
- len()返回列表长度,即列表中包含元素的个数
# 3. count()获得指定元素在列表中出现的次数
print("20在列表中出现的次数:", a.count(20))
# 4. len()返回列表长度,即列表中包含元素的个数。
a = [10, 20, 30]
print(len(a))
列表的遍历:
# 列表的遍历
print("测试列表的遍历")
a = [10, 20, 30, 40]
for o in a:print(o)
常见用法
列表常见方法如下图所示, 下面我们对部分用法进行操作
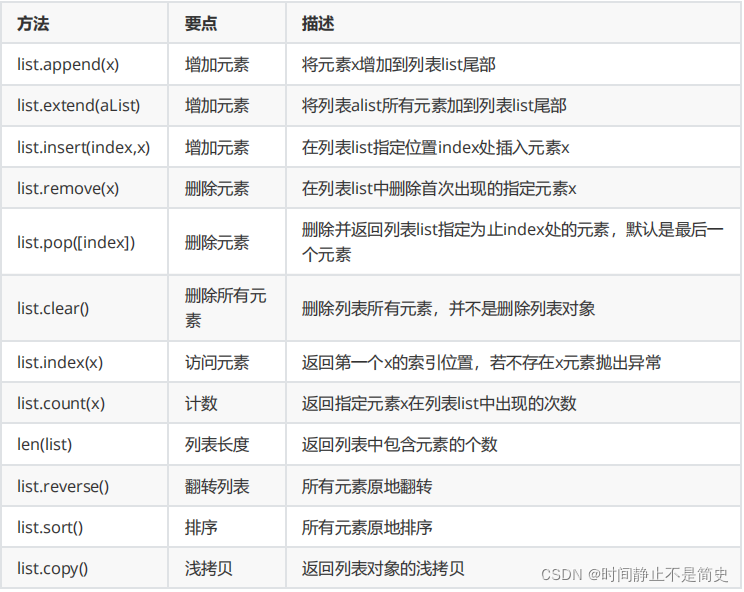
切片操作:
# 切片操作
# 类似字符串的切片操作,对于列表的切片操作和字符串类似.
# 标准格式为:[起始偏移量start:终止偏移量end[:步长step]]
# 切片操作时,起始偏移量和终止偏移量不在 [0,字符串长度-1] 这个范围,也不会报错。
# 起始偏移量 小于0 则会当做 0 ,终止偏移量 大于 “长度-1” 会被当成 ”长度-1”
print([10, 20, 30, 40][1:30])
成员资格判断:
# 成员资格判断
# 判断列表中是否存在指定的元素,我们可以使用 count() 方法,返回0则表示不存在,返回大于0则表示存在
# 但是,一般我们会使用更加简洁的 in 关键字来判断,直接返回 True 或 False
a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
print(20 in a)
print(20 not in a)
print(60 not in a)
列表排序:
sort(): 修改原列表,不建新列表的排序sort(): 建新列表的排序reversed(): 返回迭代器
# 列表排序
# 1.修改原列表,不建新列表的排序
# sort() 默认升序, 参数 reverse 代表降序
a = [2, 3, 1, 5, 4]
print(id(a))
print(a.sort())
print(a)
a.sort(reverse=True)
print(a)
random.shuffle(a) # 打乱顺序
print(a)
# 2. 建新列表的排序
# 我们也可以通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
a = [20, 10, 30, 40]
print(id(a))
b = sorted(a)
c = sorted(a, reverse=True)
print(b, c)
# 3. reversed()返回迭代器
# 内置函数reversed()也支持进行逆序排列,与列表对象reverse()方法不同的是,
# 内置函数reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象
a = [20, 10, 30, 40]
b = reversed(a)
print(type(c))
print(list(c))
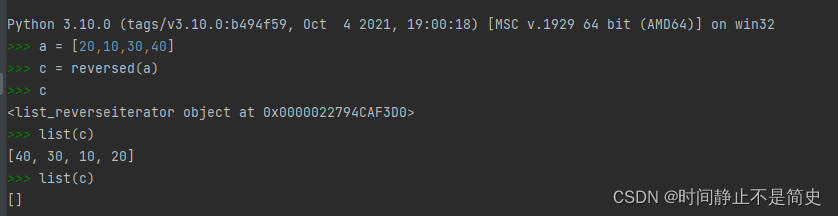
关于reversed()
我们打印输出c发现提示是:list_reverseiterator。也就是一个迭代对象。
同时,我们使用list(c)进行输出,发现只能使用一次。
第一次输出了元素,第二次为空。那是因为迭代对象在第一次时已经遍历结束了,第二次不能再使用。
max, min 和 sum
max, min用于返回列表中最大和最小值
sum 用于统计列表中各元素的和
# 列表相关的其他内置函数汇总
# 1. max和min
a = [3, 10, 20, 15, 9]
print(max(a))
print(min(a))
# 2. sum
print(sum(a))
多维列表
二维列表
- 一维列表可以帮助我们存储一维、线性的数据。
- 二维列表可以帮助我们存储二维、表格的数据。例如下表的数据:
| 队名 | 第几季 | 胜者 |
|---|---|---|
| 才子队 | 1 | 比尔 |
| 九头蛇队 | 2 | 皮尔斯 |
| 巨亨队 | 3 | 卡罗尔 |
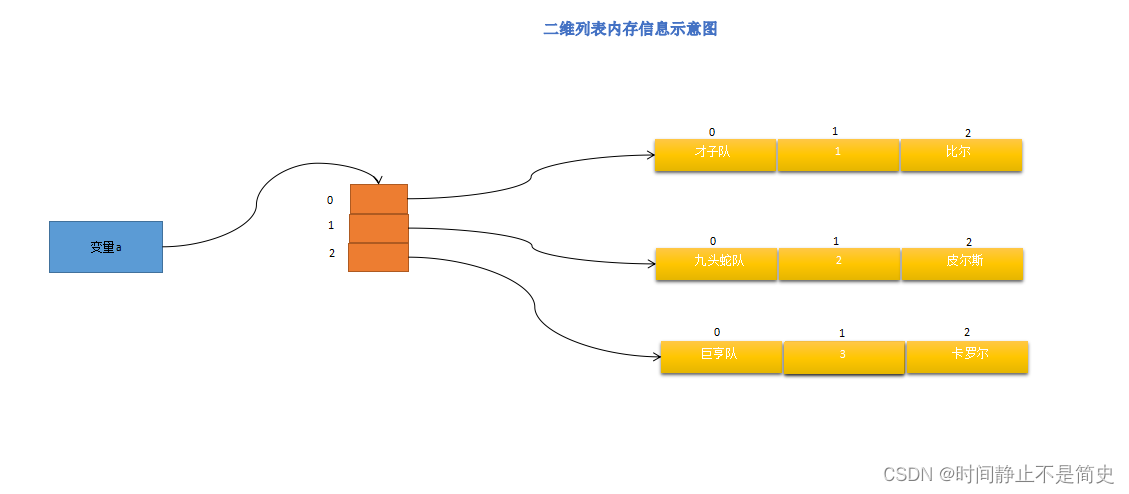
二维表的访问方式:
a = [["才子队", 1, "比尔"],["九头蛇队", 2, "皮尔斯"],["巨亨队", 3, "卡罗尔"],
]
# 输出单个元素
# print(a[0][0], a[1][1], a[1][2])# 嵌套循环打印二维列表所有的数据
for m in range(3):for n in range(3):print(a[m][n], end="\t")print()
三、其他序列类型
元组
介绍
列表属于可变序列,可以任意修改列表中的元素。
元组属于不可变序列,不能修改元组中的元素。
元组特点: 有序, 不可变, 小括号( )
操作
元组没有增加元素、修改元素、删除元素相关的方法。
只需学元组的创建和删除,元素的访问和计数即可。
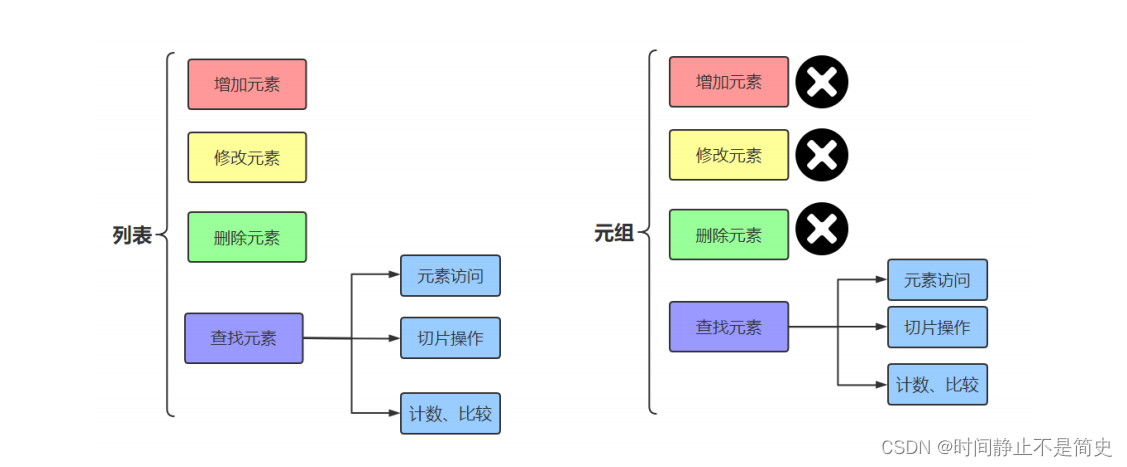
元组支持如下操作:
- 索引访问
- 切片操作
- 连接操作
- 成员关系操作
- 比较运算操作
- 计数:元组长度len()、最大值max()、最小值min()、求和sum()等
元组的创建
tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组
list()可以接收元组、字符串、其他序列类型、迭代器等生成列表
# 元组tuple
# 列表属于可变序列,可以任意修改列表中的元素
# 元组属于不可变序列,不能修改元组中的元素. 因此,元组没有增加元素、修改元素、删除元素相关的方法
a = (1)
print(type(a))
# 一般创建方式
# 如果元组只有一个元素,则必须后面加逗号。这是因为解释器会把(1)解释为整数1,(1,)解释为元组。
a = (1,)
b = 2,
print(type(a), type(b))
# 通过tuple()创建元组
a = tuple()
b = tuple("abc")
c = tuple(range(3))
d = tuple([2, 3, 4])
print(a, b, c, d)
元组的访问和计数
# 元组的元素访问和计数
# 1 元组的元素不能修改
a = [20, 10, 30, 9, 8]
# 元组的元素访问、index()、count()、切片等操作,和列表一样
print(a[1])
print(a[1:3])
print(a[:4])
print(a[2:])
print("元组的计数:", len(a))
print("指定元素出现的个数:", a.count(8))# 列表关于排序的方法list.sorted()是修改原列表对象,元组没有该方法
# 如果要对元组排序,只能使用内置函数sorted(tupleObj),并生成新的列表对象
a = (20, 10, 30, 9, 8)
b = sorted(a)
print(b) # [8, 9, 10, 20, 30]
zip
zip(列表1,列表2,…)将多个列表对应位置的元素组合成为元组,并返回这个zip对象
# zip(列表1,列表2,...)将多个列表对应位置的元素组合成为元组,并返回这个zip对象
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
a = [1, 2, 3]
b = [4, 5, 6]
c = [7, 8, 9]
d = zip(a, b, c)
print(d) # <zip object at 0x000001F1E4FBE280>
e = list(d)
print(e)
生成器推导式创建元组
# 生成器推导式创建元组
# 1.从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号
# 2.列表推导式直接生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象
# 3.我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的 __next__() 方法进行遍历,或者直接作为迭代器对象来使用。
# 不管什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象
# 列表推导式: [0, 2, 4, 6, 8]
a = [x * 2 for x in range(5)]
print(a)
# 列表推导式直接生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象
s = (x * 2 for x in range(5))
print(s)
# 我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的 __next__() 方法进行遍历,或者直接作为迭代器对象来使用
b = tuple(s)
print(b) # (0, 2, 4, 6, 8)
c = tuple(s)
# 不管什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象
print(c) # ()s2 = (x for x in range(3))
print(s2.__next__()) # 0
print(s2.__next__()) # 1
print(s2.__next__()) # 2
# print(s2.__next__()) # 报错:StopIteration
字典
介绍
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:“键对象”和“值对象”。
可以通过“键对象”实现快速获取、删除、更新对应的“值对象”
字典特点: 无序, 可变, 大括号{}+ 键值对k,v
字典是 Python 项目中最常用的序列类型之一, 对应Java 中常用的 Json 数据类型
操作
字典的创建
- 通过 {} + kv 来创建
- 通过dict()来创建字典对象(两种方式)
- 过zip()创建字典对象
- 通过fromkeys创建值为空的字典
# 字典(类比Json)
# “键”是任意的不可变数据,比如:整数、浮点数、字符串、元组. 但是:列表、字典、集合这些可变对象,不能作为“键”. 并且“键”不可重复。
# “值”可以是任意的数据,并且可重复
# 1. 通过{} 创建字典
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
print(a)
# 2. 通过dict()来创建字典对象(两种方式)
b = dict(name='TimePause', age=18, sex='man')
a = dict([("name", "TimePause"), ("age", 18)])
print(b)
print(a)
c = {} # 空的字典对象
d = dict() # 空的字典对象
print(c)
print(d)
# 3. 通过zip()创建字典对象
k = ["name", "age", "sex"]
v = ["TimePause", 18, "man"]
d = dict(zip(k, v))
print(d) # {'name': 'TimePause', 'age': 18, 'sex': 'man'}
# 4. 通过fromkeys创建值为空的字典
f = dict.fromkeys(["name", "age", "sex"])
print(f) # {'name': None, 'age': None, 'sex': None}
元素的访问:
# 字典元素的访问
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
# 1. 通过 [键] 获得“值”。若键不存在,则抛出异常。
b = a["name"]
print(b)
# c = a["birthday"] # KeyError: 'birthday'
# print(c)
# 2. 通过get()方法获得“值”. 推荐使用.
# 优点是:指定键不存在,返回None;也可以设定指定键不存在时默认返回的对象. 推荐使用get()获取“值对象”
b = a.get("name")
c = a.get("birthday")
d = a.get("birthday", "值不存在")
print(b)
print(c)
print(d)
# 3. 列出所有的键值对
b = a.items()
print(b) # dict_items([('name', 'TimePause'), ('age', 18), ('sex', 'man')])
# 4. 列出所有的键,列出所有的值
k = a.keys()
v = a.values()
print(k, v) # dict_keys(['name', 'age', 'sex']) dict_values(['TimePause', 18, 'man'])
# 5. len() 键值对的个数
b = len(a)
print(b)
# 6. 检测一个“键”是否在字典中
print("name" in a) # True
字典元素添加、修改、删除
# 字典元素添加、修改、删除
# 1. 给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对;如果“键”不存在,则新增“键值对
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
a['name'] = "时间静止"
a['phone'] = 18322222222
print(a)
# 2. 使用 update() 将新字典中所有键值对全部添加到旧字典对象上。如果 key 有重复,则直接覆盖
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
b = {'name': '时间静止', 'age': 18, 'phone': 18322222222}
a.update(b) # 旧字典.update(新字典)
print(a)
# 3. 字典中元素的删除,可以使用 del() 方法;或者 clear() 删除所有键值对; pop() 删除指定键值对,并返回对应的“值对象
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
del (a["name"])
print(a) # {'age': 18, 'sex': 'man'}
a.pop("age")
print(a) # {'sex': 'man'}
# 4. popitem() :以后入先出的方式删除和返回该键值对
# 删除并返回一个(键,值)对作为 2 元组。对以 LIFO(后进先出)顺序返回。如果 dict 为空,则引发 KeyError。
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
a.popitem()
print("第一次调用popitem", a)
a.popitem()
print("第二次调用popitem", a)
a.popitem()
print("第三次调用popitem", a)
# a.popitem() # KeyError: 'popitem(): dictionary is empty'
# print("第四次调用popitem", a)
序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值
# 序列解包
# 序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值
x, y, z = (20, 30, 10) # 变量
(a, b, c) = (9, 8, 10) # 元组
[m, n, p] = [10, 20, 30] # 列表
# 序列解包用于字典时,默认是对“键”进行操作;
a = {'name': 'TimePause', 'age': 18, 'sex': 'man'}
name, age, sex = a
print(name)
# 如果需要对键值对操作,则需要使用items()
name, age, sex = a.items()
print(name)
# 如果需要对“键”进行操作,则需要使用keys()
name, age, sex = a.keys()
print(name)
# 如果需要对“值”进行操作,则需要使用values()
name, age, sex = a.values()
print(name)
表格数据使用字典和列表存储访问
# 表格数据使用字典和列表存储访问
# 定义字典对象
a1 = {"name": "才子队", "season": 1, "winner": "比尔"}
a2 = {"name": "九头蛇队", "season": 2, "winner": "皮尔斯"}
a3 = {"name": "巨亨队", "season": 3, "winner": "卡罗尔"}
# 定义列表对象tl
tl = [a1, a2, a3]
print(tl)
print(tl[1].get("name"))
# 输出所有获胜人员名称
for x in range(3):print(tl[x].get("winner"))
# 打印表的所有数据
for i in range(len(tl)):print(tl[i].get("name"), tl[i].get("season"), tl[i].get("winner"))
字典核心底层原理(重要)
一 : 将一个键值对放进字典的底层过程
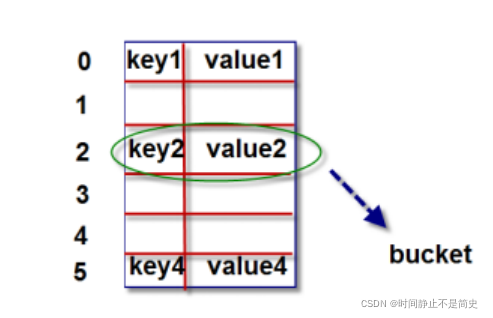
- 字典对象的核心是散列表. 散列表是一个稀疏数组(总是有空白元素的数组)
数组的每个单元叫做 bucket. 每个 bucket 有两部分:一个是键对象的引用,一个是值对象的引用
由于所有 bucket 结构和大小一致,我们可以通过偏移量来读取指定bucket
-
下面操作将一个键值对放入字典
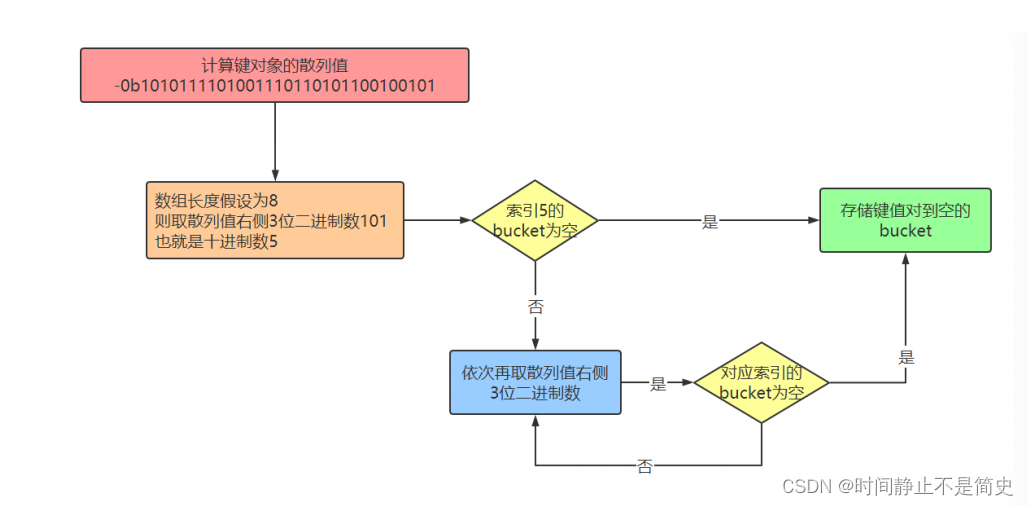
假设字典a对象创建完后,数组长度为8a = {} a["name"]="比尔"我们要把”name”=”比尔”这个键值对放到字典对象a中,
首先第一步需要计算键”name”的散列值。Python中可以通过hash()来计算。
下面我们通过 Python Console 来查看 name 的hash值bin(hash("name")) '-0b1010111101001110110101100100101'由于数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即“101”,十进制是数字5。
我们查看偏移量6对应的bucket是否为空
如果为空,则将键值对放进去。如果不为空,则依次取右边3位作为偏移量,即“100”,十进制是数字4
再查看偏移量为7的bucket是否为空。直到找到为空的bucket将键值对放进去. 流程图如下:
-
字典扩容
python会根据散列表的拥挤程度扩容。“扩容”指的是:创造更大的数组,将原有内容拷贝到新数组中。
接近2/3时,数组就会扩容
二. 根据键查找“键值对”的底层过程
-
通过 Python console() 查看字典元素值如下
>>> a.get("name")'比尔' -
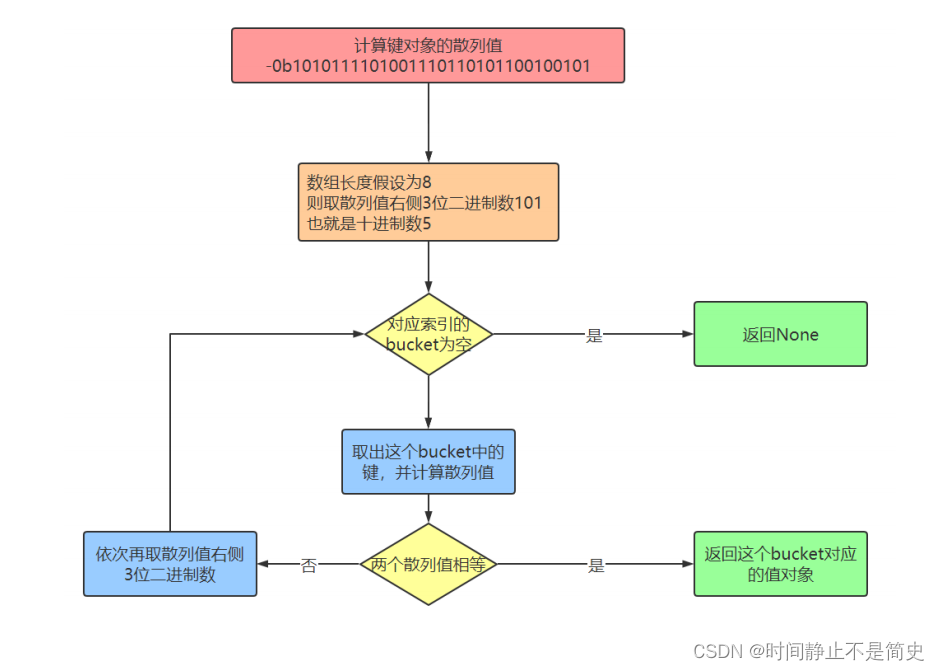
当调用a.get(“name”),就是根据键“name”查找到“键值对”,从而找到值对象“比尔”。
我们仍然要首先计算“name”对象的散列值:>>> bin(hash("name")) '-0b1010111101001110110101100100101'和存储的底层流程算法一致,也是依次取散列值的不同位置的数字。
假设数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即 101 ,十进制是数字5。
我们查看偏移量5,对应的 bucket 是否为空。如果为空,则返回 None 。
如果不为空,则将这个 bucket 的键对象计算对应散列值,和我们的散列值进行比较,
如果相等。则将对应“值对象”返回。
如果不相等,则再依次取其他几位数字,重新计算偏移量。依次取完后,仍然没有找到。则返回None 。
流程图如下:
用法总结:
- 字典在内存中开销巨大 (空间换时间)
- 键查询速度很快 (通过位运算+Hash运算)
- 往字典里面添加新键值对可能导致扩容,导致散列表中键的次序变化。
因此,不要在遍历字典的同时进行字典的修改 - 键必须可散列
数字、字符串、元组,都是可散列的
如果是自定义对象, 需要支持下面三点:
(1) 支持 hash() 函数 (2) 支持通过__eq__()方法检测相等性 (3) 若 a==b 为真,则 hash(a)==hash(b) 也为真
集合
介绍
集合: 集合是无序可变,元素不能重复
实际上,集合底层是字典实现,集合的所有元素都是字典中的“键对象”,因此是不能重复的且唯一的
集合特点: 无需, 可变, 大括号{}, 底层基于字典, 键不能重复
操作
创建和删除
# 集合创建和删除(类似set)
# 1 使用{}创建集合对象,并使用add()方法添加元素
a = {3, 5, 7}
a.add(9)
print(a) # {9, 3, 5, 7}
# 2 使用set(),将列表、元组等可迭代对象转成集合. 如果原来数据存在重复数据,则只保留一个
a = ['a', 'b', 'c', 'b']
b = set(a) # {'b', 'a', 'c'}
print(b)
# remove()删除指定元素;clear()清空整个集合
a = {10, 20, 30, 40, 50}
a.remove(20) # {10, 50, 40,30}
print(a)
集合相关操作
# 集合相关操作
# 像数学中概念一样,Python对集合也提供了并集、交集、差集等运算
a = {1, 2, 3}
b = {3, 4, 5}
print("求并集: ", a | b)
print("求并集: ", a.union(b))
print("求交集: ", a & b)
print("求交集: ", a.intersection(b))
print("求差集: ", a - b)
print("求差集: ", a.difference(b))
四、思考
根据上面的学习, 思考如下问题
- a = [100,200,300] 的内存存储示意图
- 使用 range 生成序列: 30,40,50,60,70,80
- 推导式生成列表: a = [x*2 for x in range(100) if x%9==0] ,手写出结果
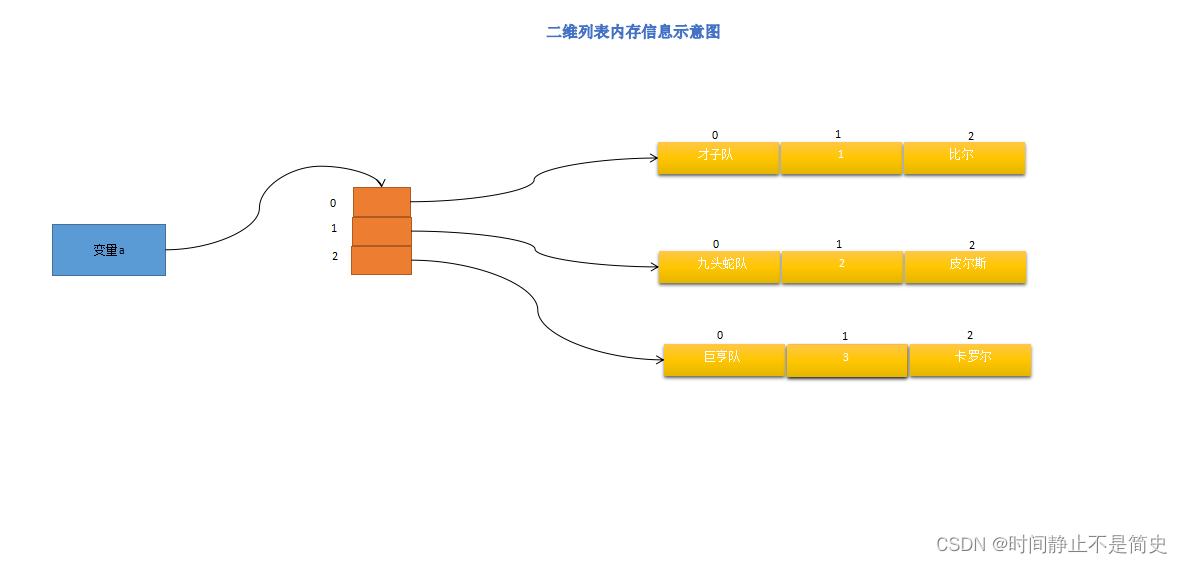
- 使用二维列表存储表格信息,并画出简单的内存存储示意图
name season winner 才子队 1 比尔 九头蛇队 2 皮尔斯 巨亨队 3 卡罗尔 - 元组和列表有哪些共同点?有哪些不同点?
- 创建一个字典对象,包含如下信息:支出金额:300.15,支出日期:2022.04.27,支出人:拿破仑
- 使用字典存储行数据,最后将整个表使用列表存储起来
name season winner 才子队 1 比尔 九头蛇队 2 皮尔斯 巨亨队 3 卡罗尔 - 用文字和自己画的示意图描述:字典存储一个键值对的底层过程。
- 集合和字典有什么关系
答案
# 1. a = [100,200,300] 的内存存储示意图, 如图1
a = [100, 200, 300]
print(id(a[0]))
print(id(a[1]))
print(id(a[2]))# 2. 使用 range 生成序列: 30,40,50,60,70,80
a = [i * 10 for i in range(3, 9)]
print(a)# 3. 推导式生成列表: a = [x*2 for x in range(100) if x%9==0] ,
a = [x * 2 for x in range(100) if x % 9 == 0]
print(a) # 输出 0-198中对9整除的数, 包括0# 4. 使用二维列表存储表格信息,并画出简单的内存存储示意图, 如图2
a = [["才子队", 1, "比尔"],["九头蛇队", 2, "皮尔斯"],["巨亨队", 3, "卡罗尔"],
]# 5. 元组和列表有哪些共同点?有哪些不同点?
# 1.相同点
# ( 1 )索引相同,从左到右都为0~~n-1。
# ( 2 )拼接相同,都可以用“+”拼接。
# ( 3 )计数相同,都使用len()函数统计元素个数、使用count()函数统计指定元素的出现次数。
# ( 4 )都属于有序序列。
# ( 5 )都可以使用del删除。
# ( 6 )都可以使用“*”来使本身重复。
# ( 7 )都可以强制转换。
# ( 8 )切片方法都一致。
# ( 9 )都可以使用for循环来进行元素遍历、索引遍历以及枚举遍历。
# ( 10 )使用index()方法获取指定元素的索引。
# ( 11 )使用运算符in测试是否包含某个元素
# 2. 不同点
# 类型不同: 元组类型为:tuple; 列表类型为:list
# 修改方式不同: 元组是不可变序列,不能修改; 列表可以根据索引来修改元素值
# 查找方式不同: 元组只能用Index()函数来查看; 列表只能用Index()函数来查看
# 查询速度不同: 元组的访问和处理速度比列表快# 6. 创建一个字典对象,包含如下信息:支出金额:300.15,支出日期:2022.04.27,支出人:拿破仑
# 方式一
order = {"支出金额": 300.15, "支出日期": "2022.04.27", "支出人": "拿破仑"}
print(order)
# 方式二
order2 = dict([("支出金额", 300.15), ("支出日期", "2022.04.27"), ("支出人", "拿破仑")])
print(order2)
# 7.使用字典存储行数据,最后将整个表使用列表存储起来
a1 = {"name": "才子队", "season": 1, "winner": "比尔"}
a2 = {"name": "九头蛇队", "season": 2, "winner": "皮尔斯"}
a3 = {"name": "巨亨队", "season": 3, "winner": "卡罗尔"}# 8. 用文字和自己画的示意图描述:字典存储一个键值对的底层过程。 见字典核心底层原理# 9. 集合和字典有什么关系
# 字典:
# 由key和value组成,字典是有序的(python3.7中)
# 字典是可变的
# 字典支持索引操作
# 字典对应的哈希表中存储了哈希值、key和value
# 字典的key不能重复
#
# 集合:
# 集合没有key和value的配对,是无序的,且元素值唯一
# 集合是可变的
# 集合不支持索引/切片操作
# 集合对应的哈希表中仅存储了哈希值
# 集合的值不能重复
# 注意:
# 在 Python3.7+以后字典都被确定为有序,而集合是无序的元素集。
# 集合和字典基本相同,区别是集合没有键和值的配对,是一系列无序的、唯一的元素组合。
图1
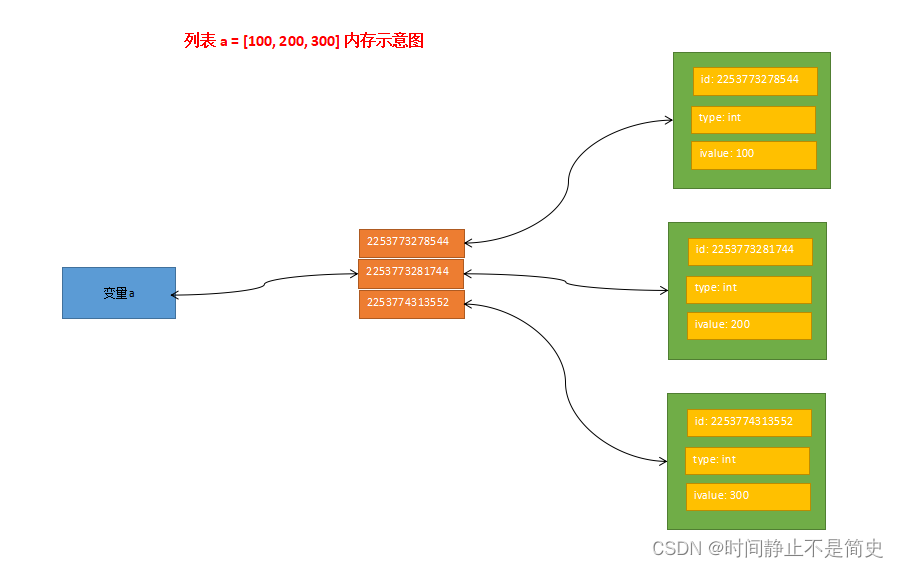
图2
这篇关于Python 升级之路( Lv3 ) 序列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



