本文主要是介绍Pytorch(一):动态图机制以及框架结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:Pytorch是目前学术界使用较为广泛的一种深度学习框架,要想能够熟练使用这个工具,就需要对它有一个全面系统的了解,本专栏就是为了带领大家系统地梳理Pytorch工具中的一些重要知识点,欢迎各位读者批评指正。
目录
1、Pytorch的动态图机制
2、Pytorch结构分析
2.1 torch
2.2 torchvision
1、Pytorch的动态图机制
Pytorch是一个基于Torch框架的,开源的Python深度学习库。Torch框架一开始是不支持Python的,后来成功把Torch移植到python上,所以叫它Pytorch。
深度学习模型在学习过程中其实就是对tensor类型的数据进行各种计算操作,随着数据计算量的不断增大,如果没有选择一种合适的计算机制,会严重影响算法的执行效率,甚至很容易出现各种bug,不利于深度学习项目的代码实现。
计算图对提高模型计算效率有很大的帮助,简单来说计算图就是用来描述运算有向无环图,主要由节点和边组成,节点表示各种类型的数据,比如向量、数组、张量等,边则表示运算法则,比如加减乘除、卷积等。比如用图1所示的计算图来表示这个运算,向量
,表示输入,
表示输出。有了计算图,因为输入
是已知的,我们只要给参数
附上初值,按计算图的流向进行前向传播很容易计算出
的值。有了计算图,使得计算过程看起来非常简洁和清晰,同时在反向传播时对各参数
求梯度也变得更加方便。
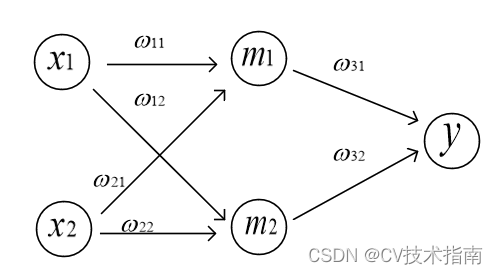
图1
计算图根据搭建方式,可以分为动态图和静态图,Pytorch采用的就是动态图机制,Tensorflow1.0版本采用的是静态图机制,但Tensorflow2.0也改用了动态图机制。
动态图:边搭建图边计算,具有灵活且易调节的优点;
静态图:先搭建图,后运算,高效但不灵活。
Pytorch动态图的代码展示:
#赋初值
x1 = torch.tensor([1.])
x2 = torch.tensor([1.])w11 = torch.tensor([1.])
w12 = torch.tensor([1.])
w21 = torch.tensor([1.])
w22 = torch.tensor([1.])
w31 = torch.tensor([1.])
w32 = torch.tensor([1.])#建立动态图
m1=torch.add(torch.mul(x1,w11),torch.mul(x2,w12))
m2=torch.add(torch.mul(x1,w21),torch.mul(x2,w22))
y=torch.add(torch.mul(m1,w31),torch.mul(m2,w32))#这时候已经计算完成
print(m1) #2.
print(m2) #2.
print(y) #4.Tensorflow1.0静态图的代码展示,
#赋初值
x1 = torch.tensor([1.])
x2 = torch.tensor([1.])w11 = tf.constant([1.])
w12 = tf.constant([1.])
w21 = tf.constant([1.])
w22 = tf.constant([1.])
w31 = tf.constant([1.])
w32 = tf.constant([1.])#建立静态图
m1=tf.add(tf.multiply(x1,w11),tf.multiply(x2,w12))
m2=tf.add(tf.multiply(x1,w21),tf.multiply(x2,w22))
y=tf.add(tf.multiply(m1,w31),tf.multiply(m2,w32))#这时候只是建好了图,还没开始计算
print(m1) #Tensor("Mul_4:0", shape=(), dtype=float32), 只是计算图的一个节点
print(m2) #Tensor("Mul_4:0", shape=(), dtype=float32), 只是计算图的一个节点
print(y) #Tensor("Mul_4:0", shape=(), dtype=float32), 只是计算图的一个节点#这里才开始进行计算
with tf.Session() as sess: print(sess.run(m1)) #2.0print(sess.run(m2)) #2.0print(sess.run(y)) #4.02、Pytorch结构分析
由于小编主要从事计算机视觉方向的研究,所以从计算机视觉的角度去梳理Pytorch的结构。Pytorch的官网网址是https://pytorch.org/,从官网公布的API文档可以知道Pytorch主要分成了Torch和torchvision两大块,其大致的结构如图2所示,这里展示的结构强调的是模块与模块之间的包含关系,熟悉Pytorch的结构以及各模块的作用对理解代码有很大的帮助,同时也能提高写相关代码的效率。

图2
torch是Pytorch深度学习框架的核心,用来定义多维张量(Tensor)结构及基于张量的多种数学操作,是一个科学计算框架,广泛支持将GPU放在首位的机器学习算法。torchvision则是基于torch开发的,专门用来处理计算机视觉或者图像方面的库。
2.1 torch
torch中主要由数据载体模块、数据存储模块、神经网络模块、求导模块、优化器模块、加速模块以及效率工具模块组成。
1)数据载体模块(torch.tensor):Pytorch深度学习框架是针对tensor类型的数据进行计算的,tensor类型的数据是Pytorch最基础的概念,其参与了整个计算过程,所有tensor类型的数据都具有以下8种基本属性:
①data:被包装的Tensor数据
②dtype: 张量的数据类型
③shape: 张量的形状
④device: 张量所在的设备, GPU/CPU, 张量放在GPU上才能使用加速
⑤grad: data的梯度
⑥grad_fn: fn表示function的意思,记录创建张量时用到的方法,比如说加法,这个方法在求导过程需要用到, 是自动求导的关键
⑦requires_grad: 表示是否需要计算梯度
⑧is_leaf: 表示是否是叶子节点(张量)。为了节省内存,在反向传播完了之后,非叶子节点的梯度是默认被释放掉的,如果想保留中间节点a的梯度,可以使用retain_grad()方法,即a.retain_grad()就行
2)数据存储模块(torch.Storage):管理Tensor是以byte类型还是char类型,CPU类型还是GPU类型进行存储。
3)神经网络模块(torch.nn):它是torch的核心,torch.nn模块下包括了参数管理、参数初始化、网络层功能函数、模型创建以及封装好的网络函数这5大工具,具体如图3所示。

①参数管理工具(nn.Parameter):torch.nn.Parameter继承torch.Tensor,其作用将不可训练的Tensor类型数据转化为可训练的parameter参数。在Pytorch中,模型的参数是需要被优化器训练的,因此,通常要设置参数为 requires_grad = True 的张量,而张量的 requires_grad属性默认是false。同时,在一个模型中,往往有许多的参数,要手动管理这些参数并不是一件容易的事情。Pytorch中的参数用nn.Parameter来管理,因为nn.Parameter管理的参数都 具有 requires_grad = True 属性,不需要再去手动地一个个去管理参数。
②初始化工具(nn.init):只要采用恰当的权值初始化方法,就可以实现多层神经网络的输出值的尺度维持在一定范围内, 这样在反向传播的时候,就有利于缓解梯度消失或者爆炸现象的发生。Pytorch中提供的权重初始化方法主要分为四大类:
针对饱和激活函数(sigmoid, tanh):Xavier均匀分布, Xavier正态分布
针对非饱和激活函数(relu及变种):Kaiming均匀分布, Kaiming正态分布
三个常用的分布初始化方法:均匀分布,正态分布,常数分布
三个特殊的矩阵初始化方法:正交矩阵初始化,单位矩阵初始化,稀疏矩阵初始化
③网络层功能函数工具(nn.functional):都是实现好的函数,调用时需要手动创建好weight、bias变量,该模块中的函数主要用来定义nn中没有而自己又需要的功能。
④模型创建工具(nn.Module):nn.Module既是存放各种网络层结构的容器(一个module可以包含多个子module),也可以看作是一种结构类型(如卷积层、池化层、全连接层、BN层、非线性层、损失函数、优化器等都是module类型的)。nn.Module是一种结构类型可以和torch.Tensor是一种数据类型对比着理解。nn.Module是所有网络层的基类,管理所有网络层的属性。属于Module类型的结构都有下面8种属性:

_parameters: 存储管理属于nn.Parameter类的属性,例如权值,偏置这些参数
_modules: 存储管理Module类型的结构, 比如卷积层,池化层,就会存储在_modules中
_buffers: 存储管理缓冲属性, 如BN层中的running_mean, std等都会存在这里面
***_hooks: 存储管理钩子函数
一个module相当于一个运算, 必须实现forward()函数(从计算图的角度去理解)。在nn.Module的__init__()方法中构建子模块,在nn.Module的forward()方法中拼接子模块,这就是创建模型的两个要素。
还有一种常用的更小型的容器是nn.Sequential,用于按顺序 包装一组网络层,并且继承于nn.Module,也是Module类型的结构。
⑤nn网络工具(封装):torch.nn模块中都是封装好的类,不需要手动创建weight, bias变量,直接调用即可,可以说torch.nn是对torch.nn.functional模块的更高层封装,能用torch.nn中的函数功能就直接用torch.nn中的函数,如果torch.nn中没有自己想要的功能,则用torch.nn.functional中的函数自己定义能实现该功能的类。为了便于对参数进行管理,将nn.functional中的函数 通过继承nn.Module转换为类的实现形式,也就是说 常用的这些函数如nn.ReLu、nn.Conv2d、nn.BCELoss、nn.drop等, 背后都在functional里面具体实现。
4)求导模块(torch.autograd):由于Pytorch采用了动态图机制,在每一次(损失函数)反向传播结束之后,计算图(此时的计算图既有前向传播的数据也有反向传播的梯度数据)都会被释放掉(因为动态图运算和搭建是同时进行的,每计算(前向传播)一次,就会搭建一次计算图,及时释放可以节省内存),只有叶子节点(参数w,b,输入x,以及真实y都是叶子节点,但是x和y这两个张量是不需要求导的,即requires_grad=false,只有参数需要求导,所以最后保留的梯度只有w,b)的梯度会被保留下来(叶子节点的梯度在权重更新时会用到),别的节点n如果想要保留下来,需调用n.retain_grad()函数。由于叶子节点的梯度不会自动清零,每次反向传播叶子节点的梯度都会和上次反向传播的梯度叠加,因此权重更新后需通过optimizer.zero_grad()函数手动将叶子节点的梯度清零。
Pytorch自动求导机制使用的是torch.autograd.backward()方法, 功能就是自动求取梯度。

tensors:表示用于求导的张量,如loss。
retain_graph:表示保存计算图, 由于Pytorch采用了动态图机制,在每一次反向传播结束之后,计算图都会被释放掉。如果我们不想被释放,就要设置这个参数为True。
create_graph:表示创建导数计算图,用于高阶求导。
grad_tensors:表示多梯度权重。如果有多个loss需要计算梯度的时候,就要设置这些loss的权重比例。
代码中一般使用loss .backward()就可以实现自动求导,那是因为backward()函数还是通过调用了torch.autograd.backward()函数从而实现自动求取梯度的.
5)优化器模块(torch.optim):通过前向传播的过程,得到了模型输出与真实标签的差异,我们称之为损失, 有了损失,损失就会进行反向传播得到参数的梯度,优化器要根据我们的这个梯度去更新参数,使得损失不断的降低。torch.optim模块下有十款常用的优化器,分别是:
①optim.SGD: 随机梯度下降法
②optim.Adagrad: 自适应学习率梯度下降法
③optim.RMSprop: Adagrad的改进
④optim.Adadelta: Adagrad的改进
⑤optim.Adam: RMSprop结合Momentum
⑥optim.Adamax: Adam增加学习率上限
⑦optim.SparseAdam: 稀疏版的Adam
⑧optim.ASGD: 随机平均梯度下降
⑨optim.Rprop: 弹性反向传播
⑩optim.LBFGS: BFGS的改进
其中最常用的就是optim.SGD和optim.Adam。
6)加速模块(torch.cuda):用于GPU加速的模块,定义了与CUDA运算相关的一系列函数
7)效率工具模块(torch.utils):里面包含了Pytorch的数据读取机制torch.utils.data.DataLoader等一些相关的函数(数据读取机制下一篇文章会具体讲解,这里不提了)以及一些可视化工具tensorboard、CAM等涉及的函数
2.2 torchvision
torchvision则是基于torch开发的,专门用来处理计算机视觉或者图像方面的库。主要有torchvision.datasets、torchvision.models、torchvision.transforms以及torchvision.utils四大块,最重要用的最多的就是图像预处理模块torchvision.transforms,这部分内容下一篇文章中会详细讲解,这里就不重复了。
这篇关于Pytorch(一):动态图机制以及框架结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





