本文主要是介绍CCL 2017最佳论文公布,看全国计算语言学前沿研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
10 月 14 日、15 日,由中国中文信息学会(CIPS)举办的第十六届全国计算语言学会议(CCL 2017)暨第五届自然标注大数据的自然语言处理国际学术研讨会(NLP -NABD 2017)于江苏南京召开。
本次会议共收到 264 篇投稿,录用 105 篇论文,录用率为 39.77%,共有超过 700 名计算语言学研究者和其他领域的专家学者参与本届会议,参会人数为历届最多。

大会主席,中国工程院院士倪光南在开幕式上致辞。

他表示,语言是信息最重要的载体,只有计算机有处理语言的能力时,计算机才能通过图灵测试,实现人工智能。因此语言智能是人工智能的核心。而信息时代以来,数字信息有效利用成为资源信息技术发展的一个全局性的瓶颈问题,语言信息处理已经成为信息科学技术长期发展新的战略制高点。而全国计算机语言学学术会议,为研讨和传播我们中文信息处理,尤其是计算语言学最新的技术和学术成果,提供了高水平的深入交流平台。2017 年,我国政府将人工智能升到国家战略高度,对 2030 年之前的中国人工智能产业进行了系统部署。在新的历史条件下,中文信息处理领域能否抓住这个重大机遇,对长期的研究和发展沉淀的基础上勇于创新产生重大突破,是我国中文信息处理里面必须回答的一个重大问题。希望此次大会能推动我国科技科学者在自然语言处理方面取得更多的成果,为我国中文信息处理事业开展新的发展阶段。
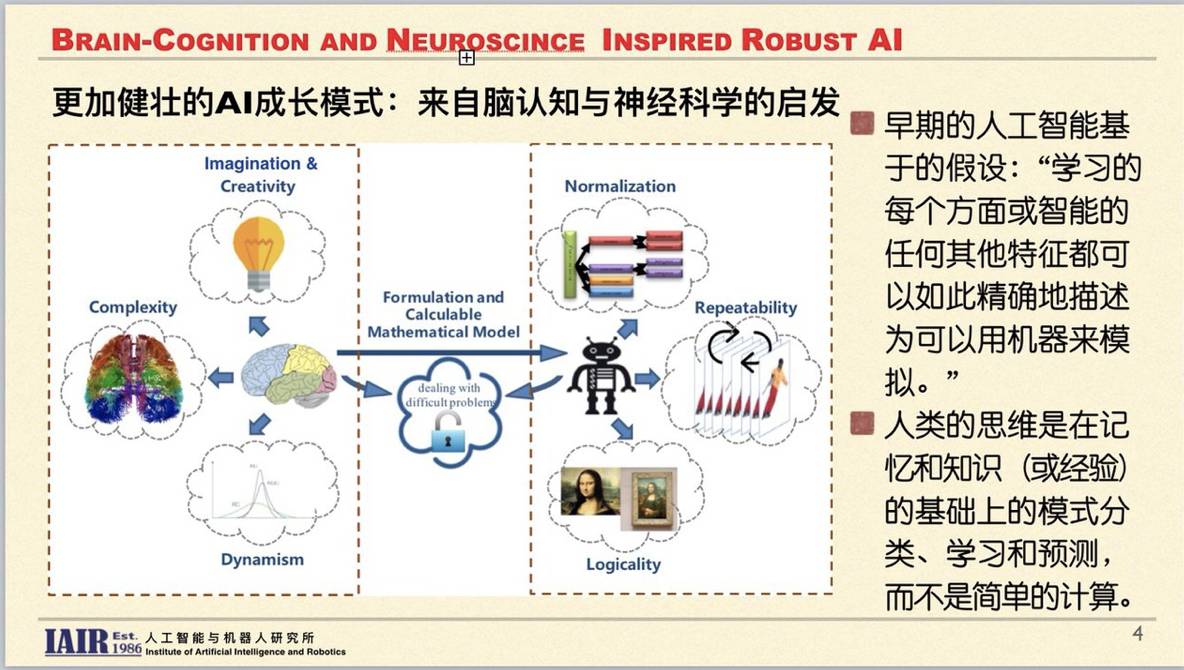
西安交通大学人工智能与机器人研究所教授、 IEEE Fellow、中国工程院院士郑南宁做了以《受脑认知和神经科学启发的人工智能》为主题的主旨报告。

郑教授认为,只有了解大脑,才能发展出更「健壮」的 AI。想要实现这类不仅在智力上超过一般人类,也在人类习以为常的复杂场景任务中取得卓越的表现的 AI,还应该从脑认知,神经科学,以及人与环境交互的过程中寻找新的方法。经典的人工智能基本理论,以演绎逻辑、语义描述以及形式化的方法来应对问题。换言之,只要能够形式化的任务,都可以用当今冯诺依曼架构的计算机以及当今的人工智能方法来解决。但是,由于条件问题(无法举出一个问题的所有条件)和分析问题(无法给出一个问题的所有分析),研究者无法对所有对象建立模型,也就无法用演绎逻辑和形式化的方法来解决复杂的、处于动态变化环境中的问题。人工智能的局限性,表现在以下五个方面:无法将问题抽象成有精确数学意义的模型,无法对已建立的数学模型设计出确定的算法或计算过于复杂,无法表现出真实世界的脆弱性和不确定性,只能进行可递归化的计算、处理可向量化的数据。

因此要向大脑中寻求人比机器强的地方,例如想象力、创造性、复杂性和动态性,找到将其融入人工智能系统的方法,建立中国新一代人工智能规划中提到的「混合增强智能」框架。
清华大学社会科学学院院长、清华大学心理学系系主任彭凯平教授则从心理学角度介绍了人的智能的优越性。

他坦陈如今传统心理学范畴内的人类智能,如学习、记忆、判断、分析、决策等认知能力都在逐渐被人工智能超越,然而除了「Brain」之外,人类还有「Mind」,即脑所产生的意识、心理、活动状况等。新兴的积极心理学,从达尔文以「自然选择,适者生存」与「性选择,美者生存」为核心观点的进化论出发,发现人类的进化历史几千万年的组织形态学变化,选择的都是人的一些独一无二的天性,这些天性现在看来可能是人比其他的生物要优越的地方,也可能是人迄今为止比机器优秀的地方。这些天性并不是我们传统上认为的认知加工能力的优势,而是进化选择出来的人类独一无二的积极心理能力。积极心理能力包括:从两岁半左右开始获得的与间接学习相关的同理心,从五岁左右开始获得的延迟满足的自控力,六个月就已经具有的天然道德意识,以及本能的对未来憧憬和计划的前瞻意识。积极心理学家认为这就是人类的智能优越之所在,以及这也许是人工智能的研究未来的探索方向。
香港科技大学计算机系新明工程学讲座教授,大数据研究所主任及计算机系主任杨强做了《从深度学习到迁移学习》报告,探讨了深度学习在小数据、可靠性等方面的弱点,介绍了近期迁移学习的进展,以及一些可能弥补深度学习不足的研究方向。

北京大学数学科学学院教授耿直以《从相关到因果:因果推断》为题,介绍了相关关系与因果关系的概念及形式化,如何由部分变量推断因果作用,如何确定替代目标的准则及问题,以及因果网络的分解学习方法、主动学习方法,并探讨了如何评价因果作用和挖掘因果网络的统计方法。

搜狗公司 CEO,前搜狐高级副总裁、首席技术官王小川介绍了搜狗公司基于「让表达与获取信息更简单」的使命,发展以输入法和搜索为核心的信息处理技术,并在「自然交互知识计算」的理念下,在对话、问答和机器翻译方面探讨产品需求和技术难题的实践。

除此之外,还有 20 位研究者就机器翻译中的分词、未登录词问题,知识图谱的关系抽取和推理问题等多个方向给出了四场口头报告。近 10 家公司在会场进行了系统展示。

15 日,大会公布了评选出的两篇 CCL 2017 最佳论文奖,一篇 NLP -NABD 2017 最佳论文奖,一篇最佳张贴报告展示奖和一篇系统展示奖,以下是获奖论文的介绍:
CCL 2017 最佳论文奖
-
论文:基于 E-CNN 的情绪原因识别方法
-
作者:慕永利,李旸,王素格
-
地址:http://www.cips-cl.org/static/anthology/CCL-2017/CCL-17-058.pdf

摘要:文本情绪原因识别作为一个新型的研究方向在文本情绪分析领域占据重要地位。本文结合卷积神经网络,提出了一种基于集成卷积神经网络的情绪原因识别方法。该方法通过词向量、卷积、池化等操作充分融合了句子的语义信息,利用多个 CNN 集成降低数据不平衡性对情绪原因识别的影响,克服了传统情绪原因识别方法的繁琐规则制定、特征抽取、特征空间降维等过程。实验结果表明,本文的方法在情绪原因识别方面取得了较好的效果,对于情绪归因的方法研究具有一定的指导作用。
-
论文:融合概念对齐信息的中文 AMR 语料库的构建
-
作者:李斌,闻媛,宋丽,卜丽君,曲维光,薛念文
-
地址:http://www.cips-cl.org/static/anthology/CCL-2017/CCL-17-034.pdf

摘要:作为一种新的句子语义表示方法,抽象语义表示(AMR)将一个句子抽象为单根有向无环图,已经建立 了较大规模的英文语料库。然而,句子中的词语和 AMR 图的概念对齐信息缺失,使得自动分析效果和语料标注 质量受到影响,同时中文尚无较大规模的 AMR 语料库。本文介绍了中文 AMR 语料库的构建工作,针对汉语特 点调整了 AMR 的标注体系,增加对复句关系的标注,提出了融合概念对齐的一体化标注方案,解决了中英文输 入法频繁切换的问题,增加了错别字纠正和未标注词高亮功能,提高了标注效率。然后,从 CTB 中选取了 6923 句进行人工标注,形成中文 AMR 语料库,统计得到图和环的比例分别为 48% 和 1%,以及利用对齐信息才能获 取的非投影句的比例 32%,为中文 AMR 的理论和自动分析研究奠定基础。
NLP -NABD 2017 最佳论文奖
-
论文:Using Cost-Sensitive Ranking Loss to Improve Distant Supervised Relation Extraction
-
作者:Daojian Zeng, Junxin Zeng, Yuan Dai

CCL 2017 最佳张贴报告展示奖
-
论文:儿童外语学习认知数据收集的在线游戏框架
-
作者:马为之,张敏,张琛昱,陈忆馨,谢倩,孙炜岳,刘奕群,马少平
-
地址:http://www.cips-cl.org/static/anthology/CCL-2017/CCL-17-056.pdf

摘要:近年来,人工智能技术飞速发展,不少工作试图从人类的认知发展过程中探索前进方向,语言学习 认知的过程成为了重点关注的研究领域。已有的语言认知研究工作主要集中在学龄前儿童母语的词汇学习认知方面,依赖于 WordBank1 等大规模语料库。然而就我们所知,目前在第二语言学习方面研究不多,尚未有大规模的第二语言词汇学习数据,且传统的数据收集方法难以收集到大规模数据,这也一定程度上限制了对于第二语言学习的研究工作及母语与第二语言学习的比较。针对这一问题,本文针对学龄前儿童群体设计了基于游戏性原则的数据收集方法和研究框架,用于收集第二语言的语言学习情况和用户数据,以支撑相应研究工作的开展。目前,我们已经实现了针对学龄前儿童的第二语言为英语的词汇认知数据收集系统,正在进行在线的数据收集。
CCL 2017 系统展示奖
-
系统:“九歌”古诗自动生成系统
-
作者:清华大学自然语言处理与社会人文计算实验室
九歌是清华大学自然语言处理与社会人文计算实验室研发的自动诗歌生成系统。九歌研究团队由孙茂松教授带领,下含两博士生、两名硕士生及多名本科生。九歌系统采用最新的深度学习技术,结合多个为诗歌生成专门设计的不同模型,基于超过 30 万首的诗歌进行训练学习。九歌系统能够产生集句诗、近体诗、藏头诗、现代诗等不同体裁的诗歌。该系统在生成诗歌的质量上有显著提升。作为一款融合现代技术和中国古典文化的有趣应用,九歌在推动自然语言处理技术发展,弘扬中华优秀传统文化等方面都有所帮助。
▽ 点击 | 阅读原文 | 获取会议论文录用列表
这篇关于CCL 2017最佳论文公布,看全国计算语言学前沿研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






