本文主要是介绍苏神博客阅读记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20220504
GAU-α:尝鲜体验快好省的下一代Attention
FLASH:可能是近来最有意思的高效Transformer设计
对attention的一个革新。标准的transformer是attention层和FFN层交替,FLASH这篇提出来利用GAU代替attention+FFN,命名为FLASH-Quad,然后采用分块混合注意力,提出了线性复杂度的FLASH.
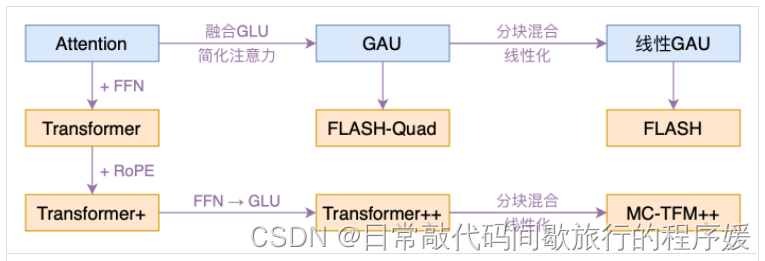
20220505
GPLinker:基于GlobalPointer的事件联合抽取
事件联合抽取模型,第一次接触事件抽取,有点类似于NER。未接触过实际任务,理解不深,其中完全子图搜索应用新颖。
明日阅读:
GPLinker:基于GlobalPointer的实体关系联合抽取
Efficient GlobalPointer:少点参数,多点效果
20220506
Efficient GlobalPointer:少点参数,多点效果
这篇厉害了(因为思路刚好可以用于最近的模型),GlobalPointner的改进,把原来NER的打分函数根据识别和分类两部分进行修改,极大减少了参数量,并且效果算有所提升(在简单任务略微降低,复杂任务极大提升)。最近试试在我们的数据上Efficient GlobalPointner是不是会更好。
GPLinker:基于GlobalPointer的实体关系联合抽取
这篇很多部分没看懂,一方面是概率图模型不理解,一方面对比的TPLinker不理解。明天继续扩展看相关的来理解GPLinker。
明日阅读:
基于DGCNN和概率图的轻量级信息抽取模型
20220507
今天工作太忙了,没来得及看,明天继续上边计划。
20220509
基于DGCNN和概率图的轻量级信息抽取模型
这是一篇考古论文,2019年bert刚提出来没多久,模型没有用bert,还在研究各种字词位置编码,看的原因是想深入了解概率图模型。没想到惊喜很多:第一个是作者放弃当时常规的命名实体识别和关系抽取模型,自己设计了概率图模型的抽签结构;第二个是很多比赛技巧,比如远程监督的先验特征(把训练集里的所有三元组取出来构建成三元组知识库直接匹配)比如知识蒸馏(用训练出来的模型对质量不好的训练集进行改进)。后边这俩技巧其实在日常开发中也用处广泛。
明日阅读:
TPLinker
20220516
在bert4keras中使用混合精度和XLA加速训练
几个参数就可以加速训练,很方便实用。
TPLinker读了但是忘记记录了,没有印象了。。。下次再读一次吧。
这篇关于苏神博客阅读记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








