本文主要是介绍关于情感词典计算情感倾向强度值的两种方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
情感倾向强度值计算公式为:

其中,Pwords代表正面情感种子词语集合,Nwords代表负面种子词语集合。

word1和word2相似度就是各概念之间相似度的最大值。
计算两个义原相似度公式如下:

其中,p1,p2为两个需要计算比较的义原,Depth(p)是义原层次体系中的深度,Spd(p1,p2)表示p1,p2两者在层次体系的重合度。
以上计算方式可以在github下载到源代码,直接调用该函数就可以计算两个单词的相似度,但是计算结果返回的值为0,即无法计算这两个词的相似度,个人理解是返回0,应该是其语义库中无法查询到该词(下载的情感词典中存在类似短语的词,或者成语,可能导致无法识别)。

中Turney使用PMI(点态互信息量)来计算两个词的相关强度

该值越大表示两个词语的相关程度就越强。
可以通过搜索引擎来计算PMI的值。一个词word的概率为搜索引擎返回hit值与总的搜索引擎返回的索引页面数比值。Word1与word2共同出现的概率同样如此计算。
因此,word1与word2的PMI值计算为:
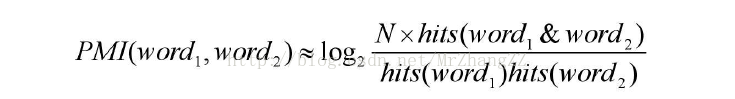
在实际应用中,也经常使用语料库来统计词语出现的概率。计算公式如下:
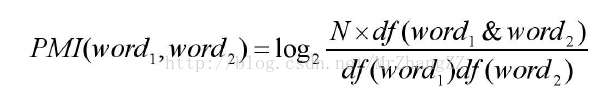
其中,df(word)表示在语料中含有词语word的文档数目,N代表为语料数据集中文档总的数目。
所以,一个为知情感倾向词语word的情感倾向强度值计算为:
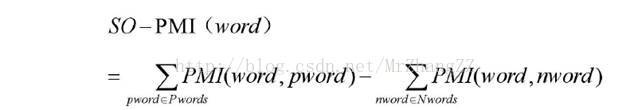
Pwords是褒义情感种子词语的集合,Nwords是贬义情感种子的词语集合。(Pwords,Nwords可以取为语料数据集中hits最高的前100个词)
但是,在语料库中,如果一个词语出现概率较小时,可能得不到该词语的正确情感倾向。

这篇关于关于情感词典计算情感倾向强度值的两种方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



