本文主要是介绍HDP3.1 安装过程与踩坑(Ubuntu18,CentOS7.6),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2019年8月准备完善一下HDP的安装, 这次加入了服务器里面常用的centos7.6的系统,下的安装,完善一下细节上的内容,本人也在学习中,如果有叙述不清的地方,留言回复,本人尽可能完善哈
目录
- 相关网址
- 一、集群搭建前的准备(已有准备可跳过)
- 二、集群准备工作(若有成品,可以跳过)
- 三、本地源的配置
- 四、开始安装
- 五、集群生成
- 小提示:
相关网址
官方文档地址
https://docs.hortonworks.com/HDPDocuments/Ambari-2.7.3.0/bk_ambari-installation/bk_ambari-installation.pdf
ambari下载地址
https://docs.hortonworks.com/HDPDocuments/Ambari-2.7.3.0/bk_ambari-installation/content/ambari_repositories.html
找里面对应系统版本, 后面tar.gz包的那个
hdp下载地址
https://docs.hortonworks.com/HDPDocuments/Ambari-2.7.3.0/bk_ambari-installation/content/hdp_31_repositories.html
百度网盘地址
链接:https://pan.baidu.com/s/18c4IJu7-e2SWlMZNn1c3ZQ
提取码:z622
初次书写,逻辑还不是很全面严谨,敬请谅解
若有命令错误,联系本人,确认修改, 感谢理解
——————————————————————————————————
一、集群搭建前的准备(已有准备可跳过)
1、各主机系统功能和角色定义,心里先有个底,比如哪台是masts主机(本次图例用单台为例)
,几个节点,数据库在哪台,IP地址以及主机名称,若无基础,可列表,作为实际的参考表下方使用。
2、准备文件 包含:HDP包,HDP-UTILS包,JAVA环境和jdbc的jar包
3、每台电脑要安装vim,ssh ;准备一台httpd服务器(可以安装在本地),作为本地源使用。
4、建议passwd root 修改密码, 用su 提权操作, 若用默认用户操作,几乎下方每一条命令都需要sudo 提权,centos7可以直接用root用户操作
——————————————————————————————————
二、集群准备工作(若有成品,可以跳过)
1、IP地址配置
linux的 IP地址配置
安装操作系统时候可以在配置服务器时候直接设置ip地址
2、ntp服务器
apt install ntp
update-rc.d ntp defaults
3、防火墙
端口较多,建议关闭防火墙,后续的端口占用可以在ambari里面修改
ubuntu18
ufw disable
centos7.6
systemctl disable firewalld
systemctl stop firewalld
4、JAVA环境配置
5、ssh 与hosts文件免密登陆
——————————————————————————————————
三、本地源的配置
这里的配置比较简单,查询你本机的httpd的服务器的html主目录在哪里, 入默认在/var/http/www/html/下
1、准备包
#将准备好的包传到安装由httpd的电脑并解压
tar -zxvf ./[包名] /var/http/www/html/#命令在包当前位置操作,命令两个系统通用
2、添加密钥并更新(需要互联网,并且在每一台电脑执行)
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com B9733A7A07513CAD
#centos不需要此步
3、在 /etc/apt/sources.list.d/ 中创建ambari.list文件,并将本地源位置写入其中
#Ubuntu18
deb http://[计算机局域网地址]/ambari/ubuntu18/2.7.3.0-139 Ambari mainCentOS7
[Updates-Ambari-2.7.3.0]
name=Ambari-2.7.3.0-Updates
baseurl=http://10.18.95.2/bigdata/centos7/ambari/2.7.3.0-139/
gpgcheck=1
gpgkey=http://10.18.95.2/bigdata/centos7/ambari/2.7.3.0-139/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1注: 每个人的路径不一样, 要根据自己的情况填写PATH和IP地址
4、完成后更新列表
Ubuntu18
apt update
CentOS7
yum clean all
#yum需要清理一下缓存
5、更新一下全局包(这一步操作主要是因为本人在用centos安装的时候,yum 会出现被占用的情况,可能是因为自动安装某个包的时候会涉及到其他的包,占用安装时间)
Ubuntu18
apt upgrade
CentOS7
yum update
——————————————————————————————————
四、开始安装
1、主节点
Ubuntu18
apt install ambari-server
ambari-server setup
CentOS7
yum install ambari-server
ambari-server setup
注:安装过程中,遇到是否配置JAVA环境要选Y ,并把JAVA 环境配置进去,否则你将会进入漫长的下载。

如果要修改数据库,要确保数据库可以被连接 ,有连接的驱动程序。默认安装pg数据库并且自动配置

当看到 successfully 为安装完成

2、安装数据库连接,此处和你后期hive元数据的数据库相对应,练习安装mysql即可
#要提前准备好jar传入服务器,自己能找得到的文件夹ambari-server setup --jdbc-db=[数据库名字] --jdbc-driver=/[jdbcjar包路径]/[jar包名]
#例:ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/java/mysql_connect.jar
3、开启服务
ambari-server start
**有时候会报错, 可能是存在部分端口被占用类似的情况, 可以通过查看日志,找相对于错误然后解决
**
——————————————————————————————————————————
五、集群生成
1、访问地址,主机的IP地址,端口号8080。用户名:admin 密码:admin
然后开始网页向导安装
需要注意的是:
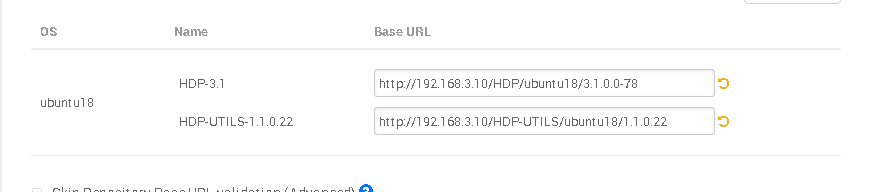
1、Select Version:
 选择本地库
选择本地库
并将其他系统包删除,保留你本机系统对应的包地址,填入本地HDP,HDP-UTILS的包地址
 填入全部的电脑地址,然后将master的主机私有密钥拷贝在框中
填入全部的电脑地址,然后将master的主机私有密钥拷贝在框中
 等完成后按照只是下一步并进行选择服务
等完成后按照只是下一步并进行选择服务
 一定要按需添加,集群对内存要求较高,内存不足会是集群奔溃
一定要按需添加,集群对内存要求较高,内存不足会是集群奔溃
 选择要连接的数据库,按照指示填入相应的参数,这里集群内置了mysql 可以默认创建,用来测试环境
选择要连接的数据库,按照指示填入相应的参数,这里集群内置了mysql 可以默认创建,用来测试环境
注:连接数据库一定要注意添加 jdbc文件,参考上面步骤
然后就是最后的安装 , 因时间原因,文章可能存在不全面的地方,回复补充
小提示:
1、 集群的主节点的内存一定要大, 最好有固态支撑
2、连接数据库都要添加jdbc文件,具体参照第四块3部分
3、ssh免密要验证,hosts文件里面必须存在localhost 127.0.0.1的映射 ,绝对不能存在[主机名] 120.0.0.1的映射
4、hive 可能存在 端口占用,在关闭hive的情况下找到ambari的设置里面,找所冲突端口修改一下保存重启即可
另外,云服务器选型有疑问的可以联系本人
阿里云入口
这篇关于HDP3.1 安装过程与踩坑(Ubuntu18,CentOS7.6)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








