本文主要是介绍hive实现oracle merge into matched and not matched,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
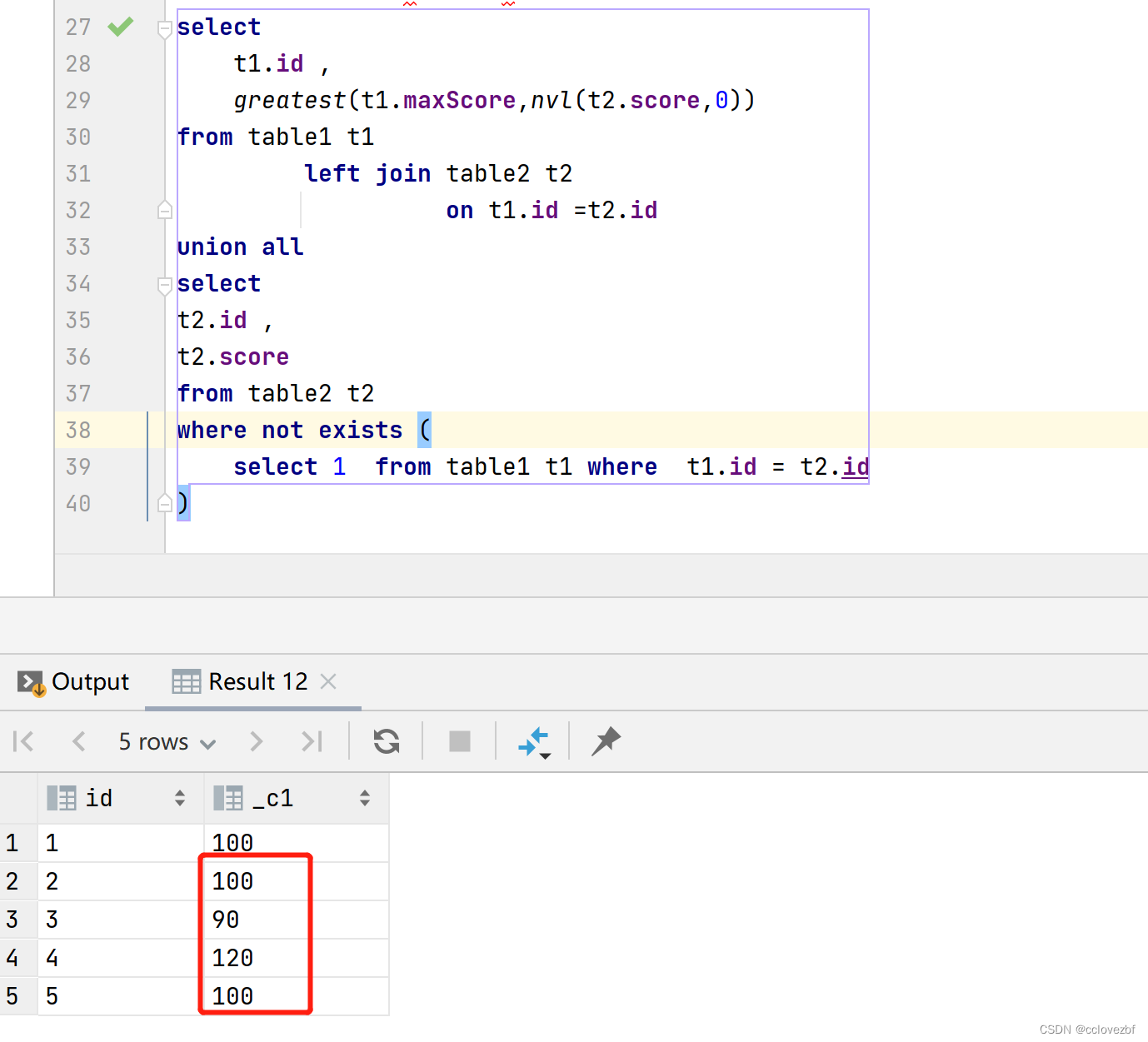
create database cc_test; use cc_test; table1 可以理解为记录学生最好成绩的表。 table2可以理解为每次学生的考试成绩。 我们要始终更新table1的数据 create table table1 (id string ,maxScore string );create table table2 (id string ,score string );insert into table1 values (1,100), (2,100), (3,100), (4,100);insert into table2 values (2,100), (3,90), (4,120), (5,100);-----注意这里2重复 3score减少 4score增加 . 5属于新增数据insert overwrite table1 selectt1.id ,greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1left join table2 t2on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where not exists (select 1 from table1 t1 where t1.id = t2.id )----------------------------------或者下面这种写法
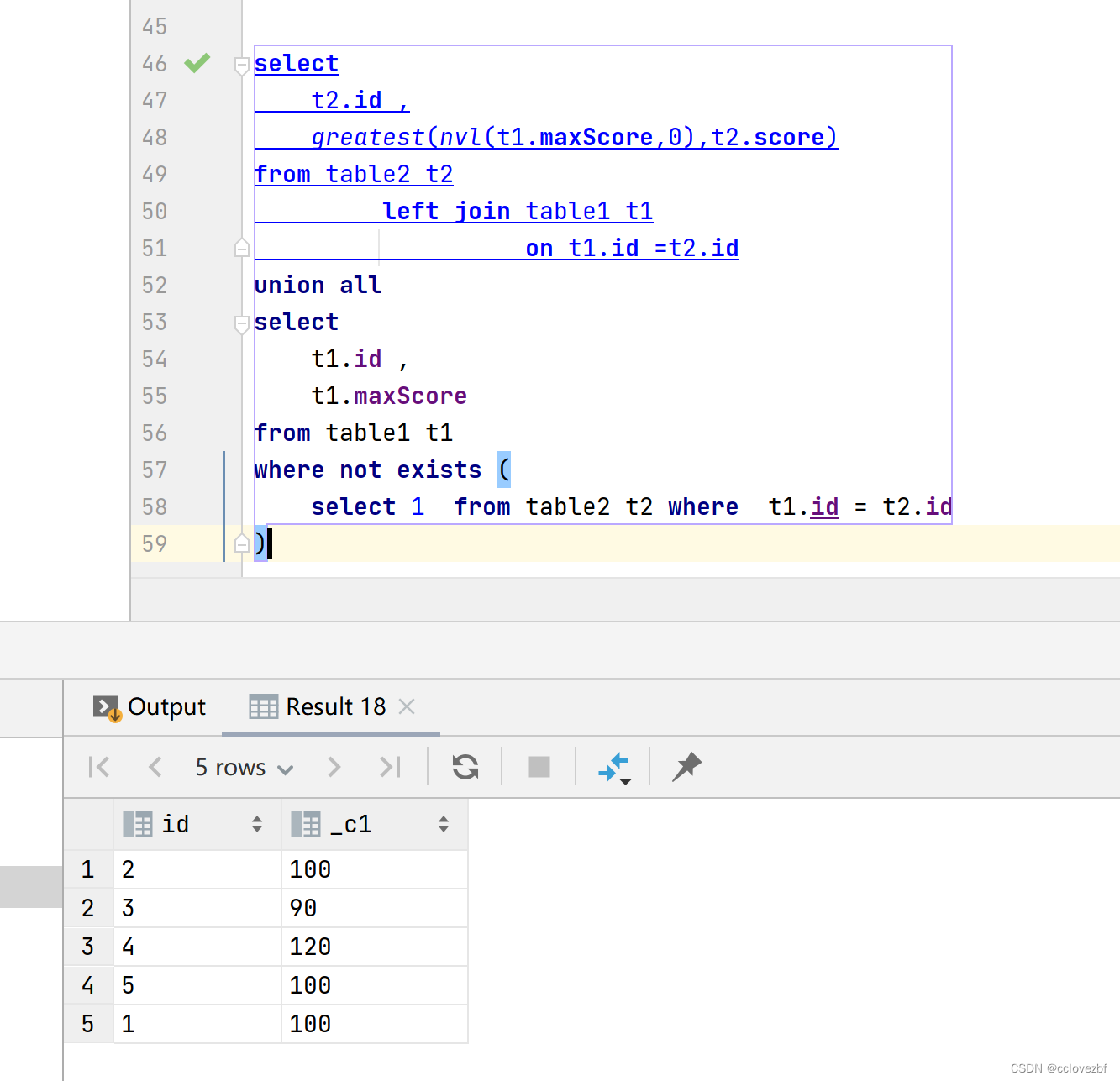
selectt2.id ,greatest(nvl(t1.maxScore,0),t2.score) from table2 t2left join table1 t1on t1.id =t2.id union all selectt1.id ,t1.maxScore from table1 t1 where not exists (select 1 from table2 t2 where t1.id = t2.id )
两个的最后查询结果是ok的。
-------------------------------------------------------
最后说下思路。 table1 和table2 两个表
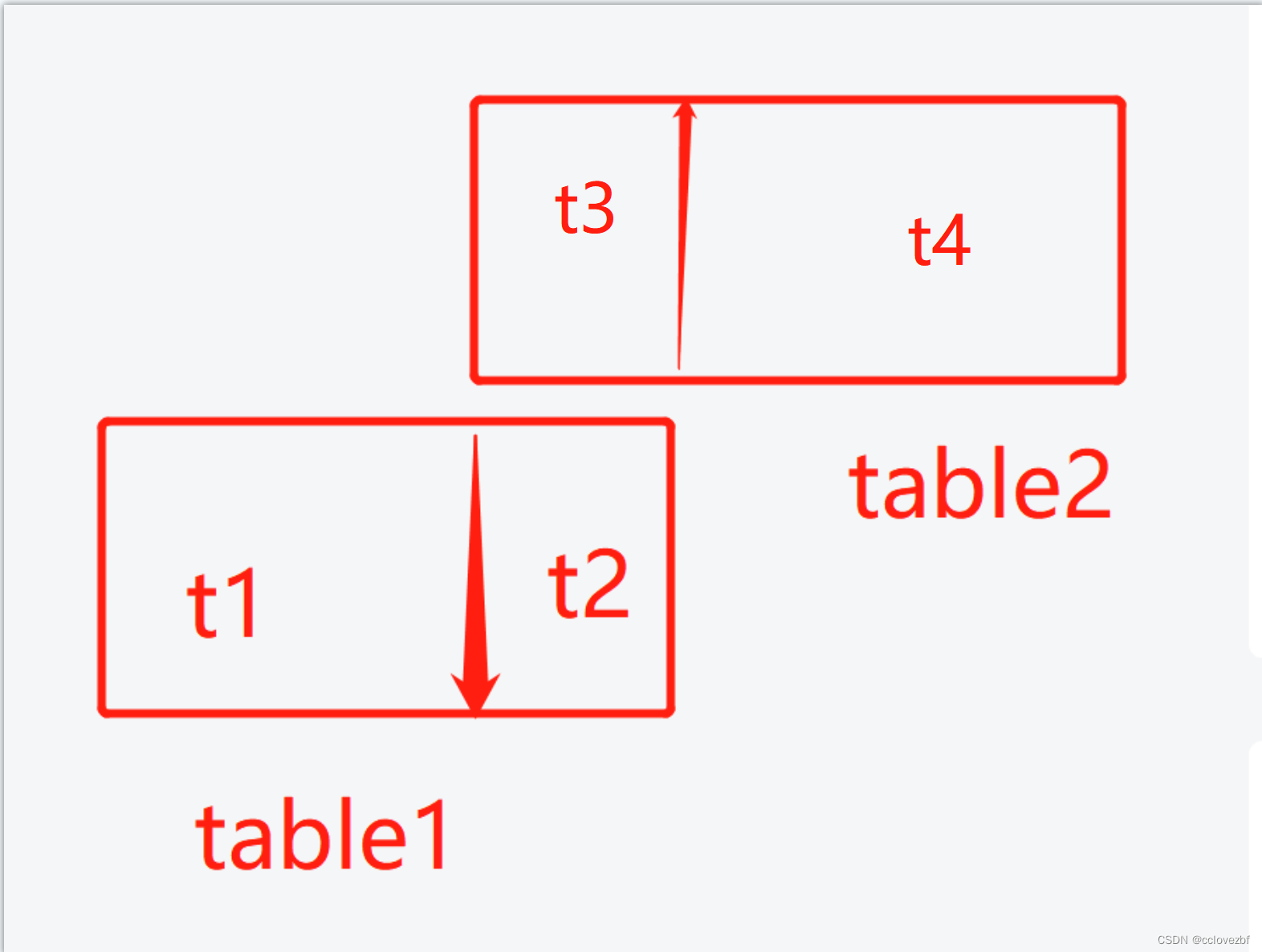
t2 和t3 相当于id重叠的部分。
因为hive没有update ,所以一般update = delete+insert 。但是hive也没有delete。。。
所以oracle的matched not match 的删掉t2 插入t3 然后插入t4。
我们可以看做 插入t1 和插入 t3+t4
也可以看做 插入 t4 和插入 t1+t2
这两种就对应我们上面的两种sql
你以为这就完了吗?怎么可能 就这么lowb的结束了。 我们要追寻更深层次的知识海洋。
两个有什么区别? 我们该选用那种好呢?
一般来说 table1 是远大于table2的。 例如学校每年的学生数量都差不多=table2.但是学校历史学生数据量是很大的=table1.
也不排除 该学校刚刚创立 第一年学生100 人 第二年学生1000人。。
但是一般来说倾向于 table1>>>>table2. 那么那种效率更高呢?
一般来说 外表大 内表小用in 。 外表小内表大用exists。
exists
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where not exists ( select 1 from table1 t1 where t1.id = t2.id )
in
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where t2.id not in ( select id from table1 )
join
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 left join table1 t1 on t1.id =t2.id where t1.maxScore is null
个人来说是推荐用exists 和join这两种的
--------------------2023-04更新-----------------------------
不好意思我把merge想的太简单了。。。上述说的只能满足最简单的merge into。有些玩意是真服了。 增强版如下。
create database cc_test; use cc_test; table1 可以理解为记录学生最好成绩的表。 table2可以理解为每次学生的考试成绩。 我们要始终更新table1的数据create table table1 (id string ,maxScore int,creat_time string );create table table2 (id string ,score int,creat_time string );insert into table1 values (1,100,'2023-04-20'), (2,100,'2023-04-20'), (3,100,'2023-04-20'), (4,100,'2023-04-20');insert into table2 values (2,100,'2023-04-21'), (3,90, '2023-04-21'), (4,120,'2023-04-21'), (5,100,'2023-04-21');with t1 as (select * ,1 as flag from table1),t2 as (select * ,1 as flag from table2) -- 这两个flag很有用的。如果你确定除了关联的条件字段外,有的字段不为null 那么可以不写。 select t1.* from table1 t1 left join t2 on t1.id=t2.id where t2.flag is null -- 这里是因为我不知道那个字段存在null,可能所有的字段都有null,我自己造个永远都没有null的字段。 -- 这个是往期的最高分数 union all select t2.id , greatest(t2.score,nvl(t1.maxScore,0)), if(t1.flag is null , --t1.flag 是否为null来判断 matched还是notmatched t2.creat_time, -- =null, 代表数据是没有关联到的 需要insert t2 if(t2.score>t1.maxScore,t2.creat_time,t1.creat_time)) -- t1 !=null代表数据是inner join 的数据需要update。 from table2 t2 left join t1 on t1.id =t2.id
此版本和上版本有哪些区别呢?
部分字段更新!!! 并不是所有字段更新。
比如我table1保留的是学生考试的最大分数,并且保留这个时间!! 唉真是绕。。真是难搞。
hive如何实现update呢?
UPDATE DWINTDATA.DW_DIM_CE_ACCOUNT T SET T.ETL_ENABLED_FLAG = 'N', T.ETL_DELETE_FLAG = 'Y'WHERE NOT EXISTS (SELECT 1FROM DWINTDATA.DW_DIM_CE_ACCOUNT_DS T1WHERE NVL(T.BANK_ACCOUNT_ID, -999999) =NVL(T1.BANK_ACCOUNT_ID, -999999)AND T.BANK_ACCOUNT_NUM = T1.BANK_ACCOUNT_NUMAND T.CURRENCY_CODE = T1.CURRENCY_CODE);
hive改写
insert overwrite table DWINTDATA.DW_DIM_CE_ACCOUNT selectbank_account_key,bank_account_id,bank_account_cn_name,bank_account_num,currency_code,bank_account_property_code,bank_account_property_cn_name,bank_account_type_code,bank_account_type_cn_name,account_segment,account_remark,status_code,bank_branch_cn_name,bank_id,bank_cn_name,bank_location_id,bank_location_remark,country_region,country,creator_id,last_update_date,last_updater_id,etl_create_batch_id,etl_last_update_batch_id,etl_create_job_id,etl_last_update_job_id,etl_create_date,etl_last_update_by,etl_last_update_date,etl_source_system_id, 'Y' etl_delete_flag,'N' etl_enabled_flag from DWINTDATA.DW_DIM_CE_ACCOUNT T WHERE NOT EXISTS (SELECT 1FROM DWINTDATA.DW_DIM_CE_ACCOUNT_DS T1WHERE NVL(T.BANK_ACCOUNT_ID, -999999) =NVL(T1.BANK_ACCOUNT_ID, -999999)AND T.BANK_ACCOUNT_NUM = T1.BANK_ACCOUNT_NUMAND T.CURRENCY_CODE = T1.CURRENCY_CODE)union all select * from DWINTDATA.DW_DIM_CE_ACCOUNT T WHERE EXISTS (SELECT 1FROM DWINTDATA.DW_DIM_CE_ACCOUNT_DS T1WHERE NVL(T.BANK_ACCOUNT_ID, -999999) =NVL(T1.BANK_ACCOUNT_ID, -999999)AND T.BANK_ACCOUNT_NUM = T1.BANK_ACCOUNT_NUMAND T.CURRENCY_CODE = T1.CURRENCY_CODE)select count(1) from table WHERE not EXISTS -- 1696
select count(1) from table WHERE EXISTS --857
select count(1) from table --2553
这篇关于hive实现oracle merge into matched and not matched的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


