本文主要是介绍买包的小行家,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.数学类
- 全排列
- 序列组合
- 组合数(用到阶乘)
- 简单数论
- 最小公倍数、最大公约数
- 质数+素数筛
- 矩阵快速幂
- 获取一个数的二进制
- 2.工具类
- 回文数
- 字典
- 字典的排序
- 字典的计数
- 日期
- 字符串
- 字符串拼接
- 字符串分割
- 3.容器类
- 图
- 队列
- 快捷键:
1.数学类
全排列
itertools 迭代工具 permutations 排列、序列
from itertools import permutations
print(list(permutations([1, 2, 3])))
#求几个的全排列
序列组合
#combinations 合并、结合
from itertools import combinations
print(list(combinations([1,2,3,5],3)))
#在序列【1,2,3,5】中任意三个数的组合
组合数(用到阶乘)
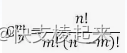
import math
def c(m, n):return math.factorial(n) // (math.factorial(m) * math.factorial(n - m))#print(math.factorial(5)) #5的阶乘:5*4*3*2*1
简单数论
最小公倍数、最大公约数
def gcd(a,b):if a%b==0:return belse:gcd(b,a%b)
"""
如果gcd(10,25):10%25=10 !=0 进入
gcd(25,10): 25%10=5 进入
gdc(10,5):%后为0,则 5是最大公约数"""
def lcm(n1,n2):return n1 * n2
质数+素数筛
1.试除法:普通做法
def isPrim(n):if n<2:return Falsefor i in range(2,int(n//2)+1): #这里写n也没事if n%i==0:return Falsereturn True
#求1到n多少质数 存再数组a中
a=[]
n=int(input())
for i in range(n+1):if isPrim(i):a.append(i)
print(a)
"""
为什么是(2,sqrt(n))
如果a是n的约数,那么n/a也是n的约数。易知(a,n/a)是成对的
我们检验的是其中较小的那个数,在[1,n^0.5]区间中"""
埃式筛法 :通过倍率去除的效率太快了
#筛选法 求1到n多少质数
def countPrim(n):count = 0signs = [True] * (n+1)for i in range(2, n+1):if signs[i]: count += 1for j in range(i + i, n+1, i):#i倍signs[j] = Falsereturn count
未补充:试求下题
唯一分解定理
自己的错误解法
import math
from math import sqrt
n=9 #假设求9的阶乘
a=[ 0 for i in range(n+1)] #先初始化一个数组
def add(x): #add函数 假设加了8:2*2*2 则在下标为2加3for i in range(2,int(sqrt(x))+1):while x%i==0: #若能除2,则a[2]+=1,再把x除2a[i]+=1x//=iif x>1:a[x]+=1
for i in range(2,n+1): #add(i)
矩阵快速幂
还有欧拉函数 不知道会不会考
获取一个数的二进制
def getbin(n):b=str(bin(n))if n<0:return b[3:]else:return b[2:]
a=int(input())
print(getbin(a))
"""
bin(n) 转换出的二进制是 0b+n 或者-0b+n
想要只保留二进制形式,则
正数 [2:] 负数[3:]
"""
2.工具类
回文数
def huiwenshu(n):return n>-1 and str(n)[::-1]==str(n)
n=int(input())
print(huiwenshu(n))
字典
字典的排序
import collections
d=dict(collections.Counter('Hello World'))
#Counter:跟踪值出现的次数。 元素作为key,其计数作为value
#也就是说,d只是一个统计次数的字典而已,并无规律可言#按照出现的次数进行排序
print(sorted(d.items(),key=lambda x:x[1])) #默认: 由小到大
print(sorted(d.items(),key=lambda x:x[1],reverse=True)) #反转为真:由大到小
“”“
key=lambda 变量:变量[维数]
key=lambda x: x[1]
x:x[ ]字母可以随意修改,[0]按照第一维排序,[1]按照第二维(即value)排序
”“”
字典的计数
import collections
#1:传入一个序列
print(collections.Counter(['a','a','b','c','a','d','a']))
#2:传入一个字典
print(collections.Counter({'a':2,'b':3,'c':1}))
#3:用’=‘传值
print(collections.Counter(a=2,b=3,c=1))
日期
输入字符串"2121:21:12"返回当前秒数:
? .isoweekday .day
import datetime
#datetime是时间模块
d=datetime.datetime(2001,5,15,13,59,59) #默认 年月日 时分秒
dt = datetime.timedelta(days=1, seconds=1,minutes=1, hours=1, weeks=1) #需要注明多少天多少小时
#timedelta是时间差,不过可以被实例化出来
print(d)
print(dt)
字符串
字符串拼接
s=input()
res=''
for i in s:if i in "abcdef":res+=i.upper()
print(res)
字符串分割
#m是一连串字符串
”“”
sadadas
asdasda
asdqwqw
“”“
matrix = m.split('\n')
可将其分割成数组里的部分
str(时间)---->秒数
def get_second(t):h,m,s = map(int,t.split(':')) # 分别得到hour,minute,secondreturn h*3600+m*60+s
3.容器类
图
队列
from collections import deque
d=deque()
d.append(1)
d.append(2)
d.append(3)d.appendleft(4) #在队首添加元素print(d.popleft()) #弹出队首元素
print(d.pop()) #弹出队尾元素
快捷键:
Fn键,再按F1到F12里的任意一个
part1:
缩进: Ctrl+ ]
取消缩进: Ctrl+[
注释: Alt+3
取消缩进: Alt+4
Ctrl+F6:可以清空前面的记录,重启shell
part2:
创建新文件:Ctrl+N
运行 :F5
单词补齐 :Alt+/
关键字后 按tab:出现可以调用的方法
这篇关于买包的小行家的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!