本文主要是介绍百万粉网红当大学老师惹争议!北大论文被扒,被指因外籍身份获利,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:硕博关注
来源:盖饭娱乐(作者:大杯冷萃)
7月9日,有网友在论坛上发帖称:曾经参加过《令人心动的offer》第一季的梅桢去华东政法大学任教了,引发了网友们的大量争议。

据悉,这位梅桢小姐姐是那季节目中学历最高的实习生——本科就读于澳大利亚邦德大学,研究生就读于北京大学经济法学,博士就读于北京大学经济法学。
不过最后她却输给了学历不如她的队友,并没有拿到offer。

不少人认为,是因为梅桢虽然学历高,但能力却不够强。

而从此次曝光的《华东政法大学的拟聘人员公示》来看,梅桢的名字位居第一。
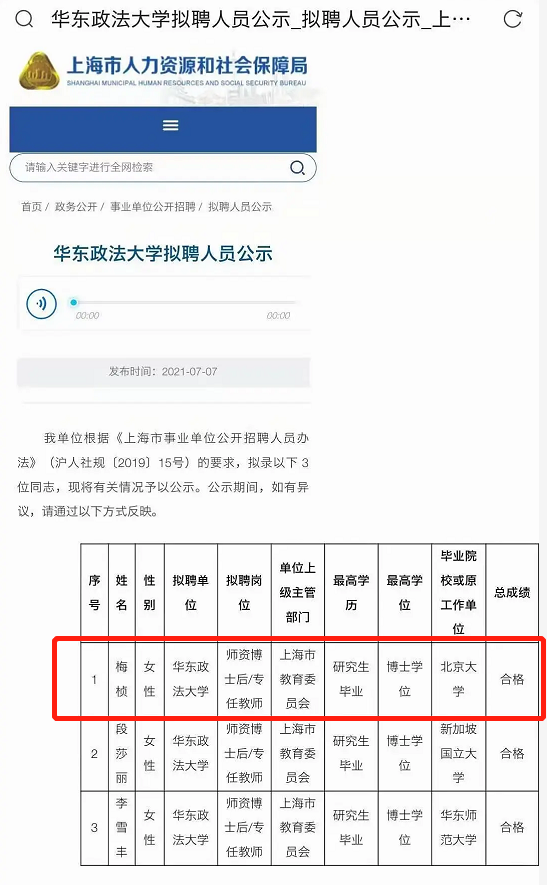
于是,有网友对梅桢做了一次详尽的“扒皮”。
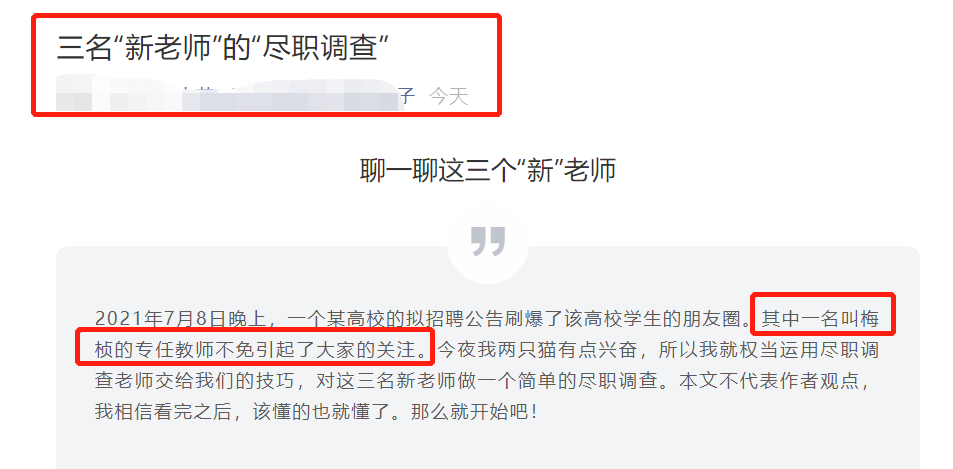
据网友调查,梅桢是澳大利亚人,进入北京大学是通过“留学生通道”。

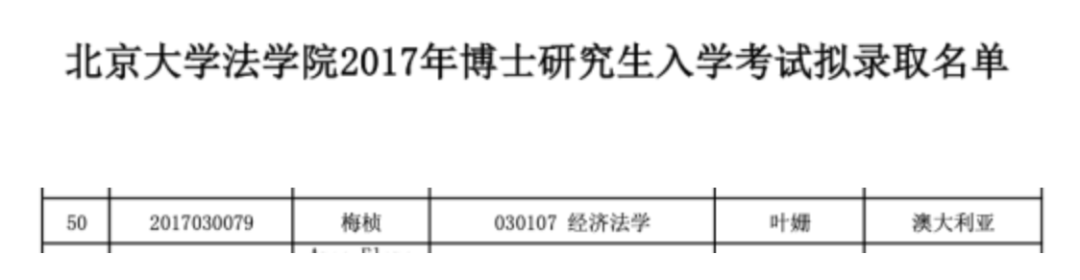
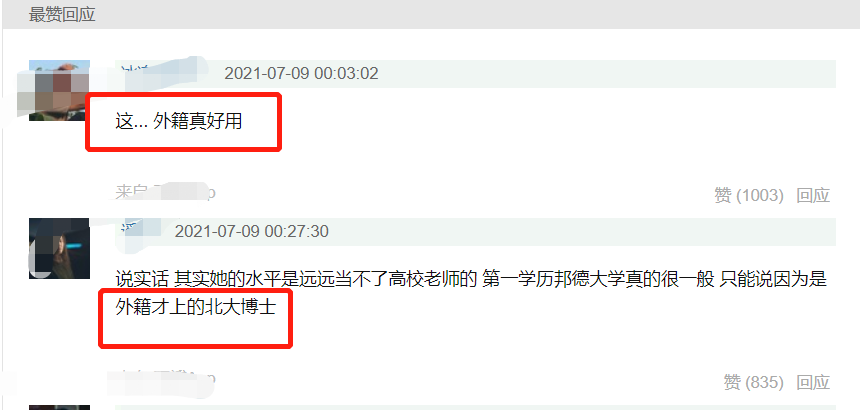
对这一行为,该网友也提出来质疑,直指她之所以能进入北大是的得益于外籍身份,是有“水分”的。

就这一点,其余网友们也纷纷附和。
随后,该网友在知网上检索了梅桢在北京大学期间的论文,发现她的总发文量只有两篇期刊文献。
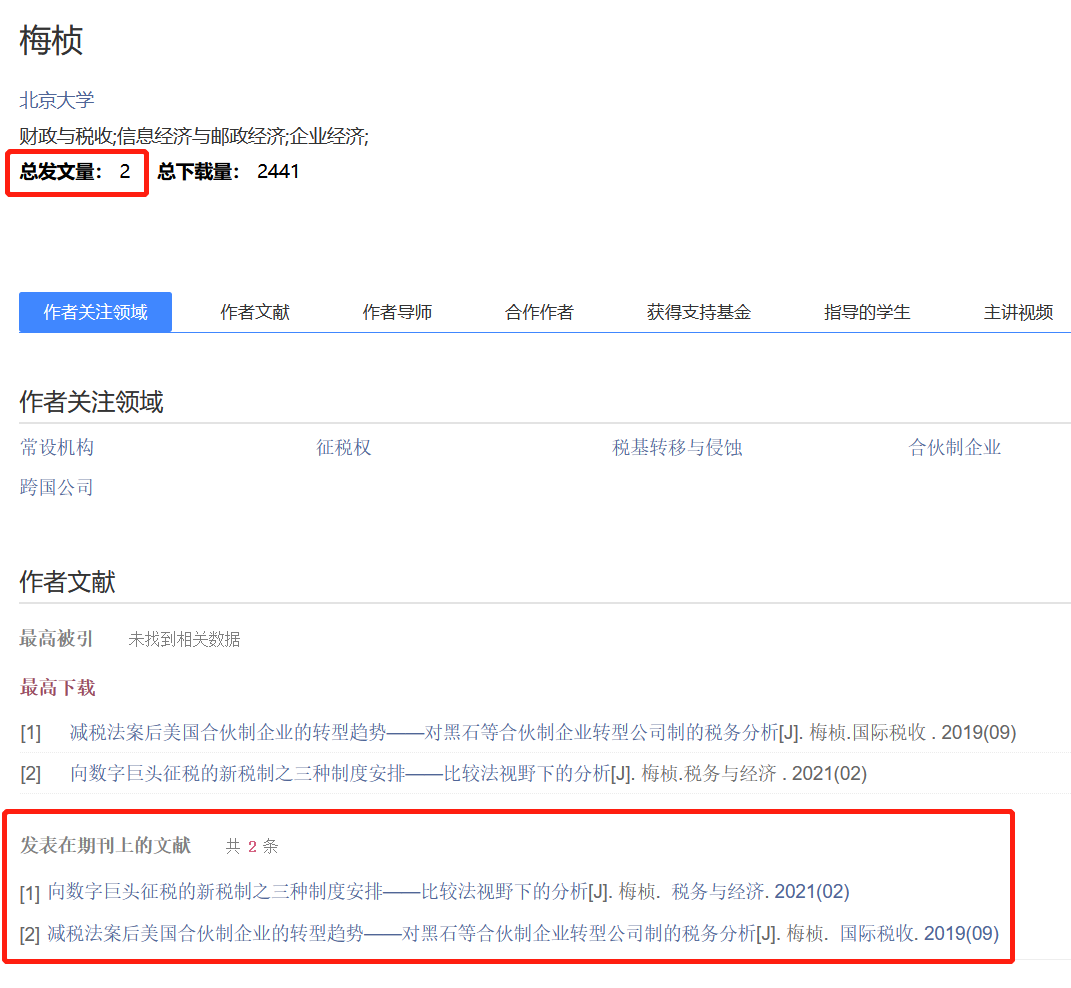
一篇发表于《国际税收》,另一篇发表于《税务与经济》,两本都是知网认可的核心期刊。这倒是符合华东政法的聘用要求。

只不过该网友发现,这两篇核心期刊论文竟然不是传统的法学核心期刊,而是发在了经济与管理科学这个分类下的期刊,其两本期刊的综合影响因子并不算高。
而拜读完这两篇期刊文章后,该网友更是直言:“对她的学术能力和科研能力持一定的怀疑态度。”

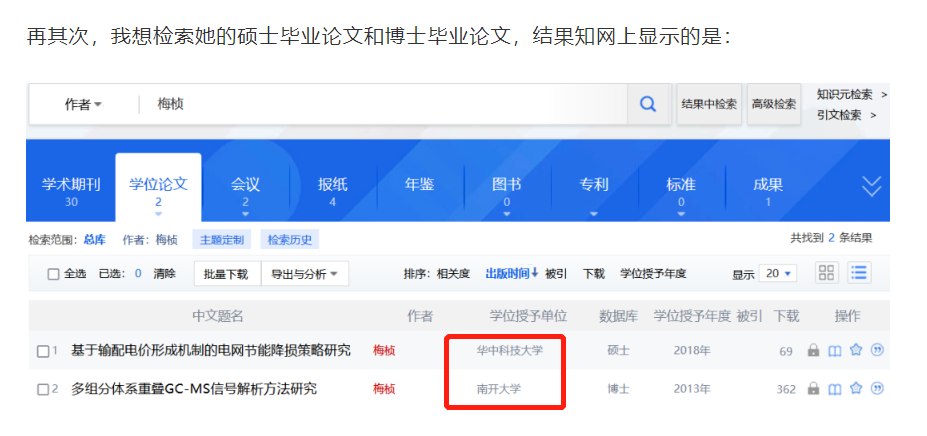
除这两篇期刊论文以后,再无其他,也就是说:知网上并没有她的硕士毕业论文和博士毕业论文!
更有意思的是,梅桢不止有两篇论文,还有两家与她相关的公司。
据公开信息显示,她于2015年创立了一个叫做时尚清单的品牌。
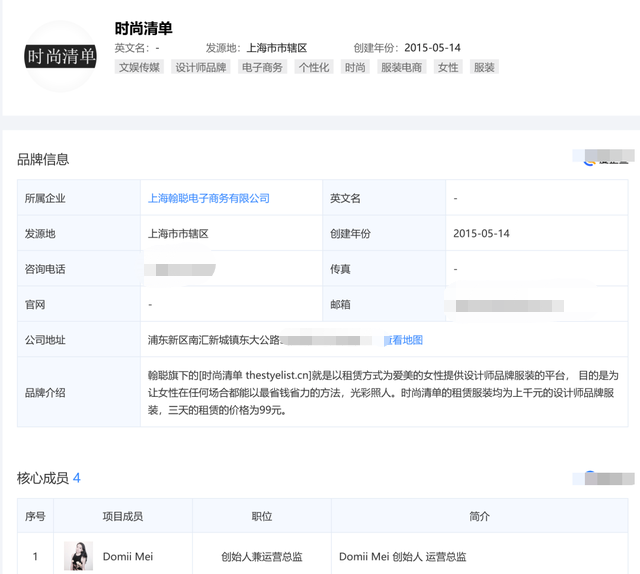
这位Dommi Mei就是梅桢,而点进品牌的所属企业——上海翰聪电子商务有限公司以后,又可以发现该公司有一名叫做“梅新华”的股东。
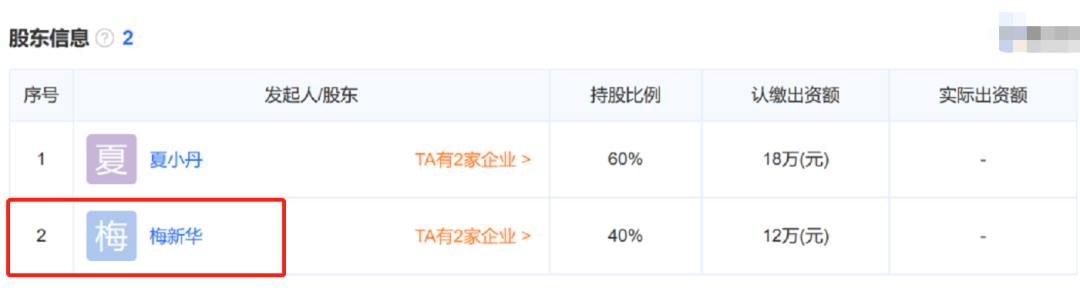
梅新华名下还有另一家企业叫做“桢好文化传媒有限公司”。

而这家从事文化传媒的公司的法定代表人又是梅桢。
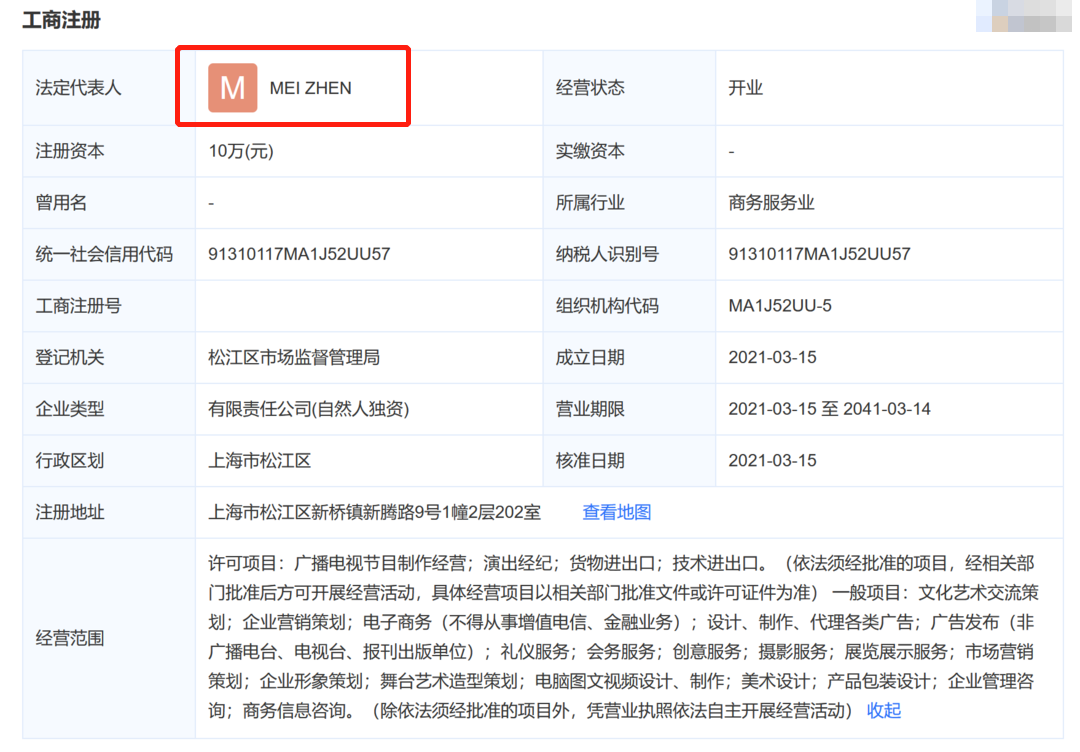
不过这些倒是和梅桢的另一个身份很吻合。
据悉,除了上过综艺,梅桢还是以为视频博主,也就是大家俗称的“网红”。
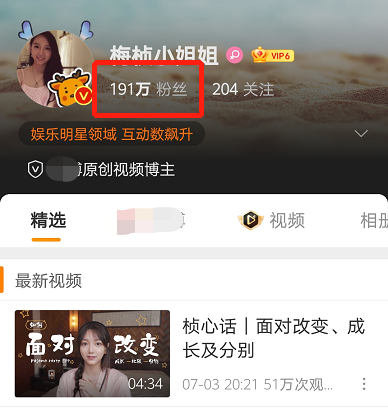
在几个大平台上,她的粉丝都已经过百万,名气颇高。

日常画风当然和学术无关,基本上就是她和老公的恩爱日常,以及她的护肤、美妆分享。


也正是因为“网红”这一身份,梅桢所遭到的质疑声愈演愈烈。
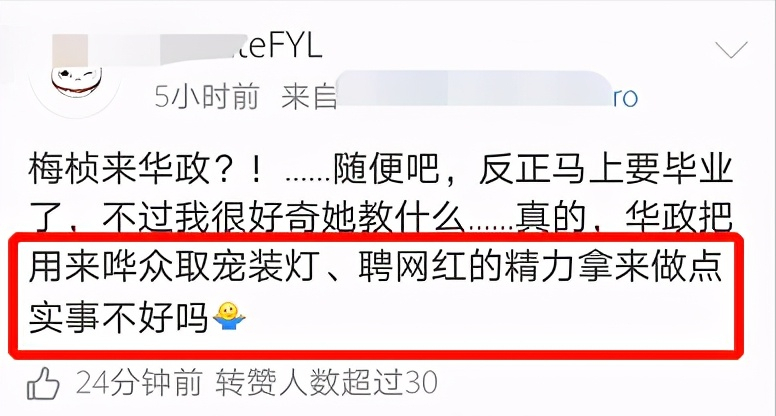
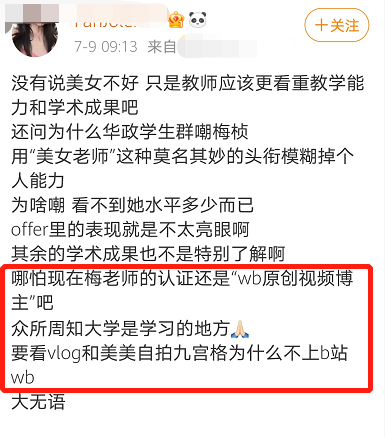
不少网友表示:梅桢大概只能开一些“网红孵化课”,教大家如何制作精美的vlog……

不过话说回来,“网红”并不能代表一切,没有谁规定网红一定是没文化、没水平的,也没有谁说老师就不能当网红。
只不过,梅桢身上的争议并非只有“网红”这一条,她到底能不能胜任一所国内一流大学的专任教师,这一点确实还有待商榷。
CVPR和Transformer资料下载后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
这篇关于百万粉网红当大学老师惹争议!北大论文被扒,被指因外籍身份获利的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

