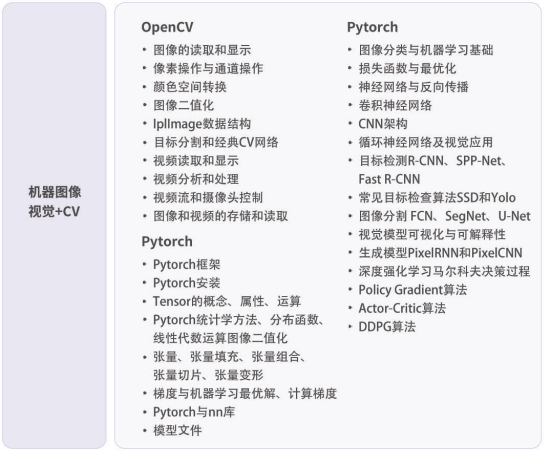
一、数制及进制转换
数制:
数制也称计数制,是用一组固定的符号和统一的规则来表示数值的方法。任何一个数制都包含两个基本要素:基数和位权。
进位计数制三要素:数位、基数、权位
数位:数码在数中所处的位置
基数:每个数位上所能使用的数码的个数
权位:每个数位上的数码所代表的数值的大小等于这个数位山的数码乘以上一个固定的值,这个值就是该进位数制中的位权。

各个进制数表示方式:
十进制: (2018)10 或 2018D
二进制 (1011)2 或 1011B
八进制 (723)8 或 723O
十六进制 (1CF)16 或 1CFH
进制相互转化要求掌握:
1、十进制转化为二、八、十六进制(整数部分:辗转求余法 小数部分:乘基取整)
2、二、八、十六进制转化为十进制(权位相加法)
3、二、八、十六进制相互转换
4、十六进制加减法
二、数据的储存单位
1、位(bit)
数据存储单位Bit(比特)是binary digit的英文缩写,量度信息的单位,也是表示信息量的最小单位,只有0、1两种二进制状态。
2、字节(byte)
位的储存能力太小,无法用来表示数据的含义,8个bit组成一个Byte(字节),简称B。一般用字节来作为计算机储存容量的基本单位。
计算机常用的存储单位
8 bit = 1 Byte 一字节
1024 B = 1 KB (KiloByte) 千字节 210B
1024 KB = 1 MB (MegaByte) 兆字节 220B
1024 MB = 1 GB (GigaByte) 吉字节 230B
1024 GB = 1 TB (TeraByte) 太字节 240B
3、计算机采用二进制的原因
(1)物理单元限制:数字信号中高低电平 0 1表示(主要原因)
(2)运算简单:0+0=0 0+1=1 1+0=1 1+1=10
(3)容易实现逻辑运算 : 非 NOT 与 AND 或 OR
三、信息编码
3.1数值
正负数在计算机中表示(1)原码(2)反码(3)补码

数值数据的表示
我们把一个数在计算机内被表示的二进制形式称为机器数,该数称为这个机器数的真值。
机器数有固定的位数,具体是多少位与机器有关,通常是8位或16位。
机器数把真值的符号数字化,通常用最高位表示符号,0表示正,1表示负。
例如,假设机器数为8位,最高位是符号位,那么在定点整数的情况下,00101110和10010011的真值分别为十进制数+46和-19。
(1)原码:
一个整数的原码是指:符号位用0或1表示,0表示正,1表示负,数值部分就是该整数的绝对值的二进制表示。
例如:假设机器数的位数是8,那么:[+17]原=00010001 [-39]原=10100111
值得注意的是,由于 所以数0的原码不唯一,有“正零”和“负零”之分。
(2)反码
在反码的表示中,正数的表示方法与原码相同;负数的反码是把其原码除符号位以外的各位取反(即0变1,1变0)。通常,用[X]反表示X的反码。例如:
[+45]反 = [+45]原 = 00101101
[-32]原 = 10100000
[-32]反 = 11011111
(3)补码
在补码的表示中,正数的表示方法与原码相同;负数的补码在其反码的最低有效位上加1。通常用[X]补表示X的补码。例如:
[+14]补 = 10100100
[-36]反 = 11011011
[-36]补 = 11011100
注意:数0的补码的表示是唯一的,即[0]补=[+0]补=[-0]补=00000000
现在我们来看看引进原码、反码与补码这几个概念到底有什么意义。先看下面的例子。例如:X = 52,Y = 38,求X – Y的值。
[X]补 = 00110100
[-Y]原 = 10100110
[-Y]反 = 11011001
[-Y]补 = 11011010
现在我们看看[X]补 + [-Y]补 等于多少?
[52]补: 0 0 1 1 0 1 0 0
[-38]补:+) 1 1 0 1 1 0 1 0
1 0 0 0 0 1 1 1 0
自然丢失
我们可以看到,最高位丢失后,结果(14)正是52-38的值。从这里我们不难体会到通过补码可以把减法运算变成加法运算来做。这样做有什么意义呢?实事求是地说,引入补码意义非同寻常,可以说是先辈们智慧的结晶。因为,通过补码运算,可以把减法运算变成加法运算;而乘法可以用加法来做,除法可以转变成减法。这样一来,加、减、乘、除四种运算“九九归一”了。这对简化CPU的设计非常有意义,CPU里面只要有一个加法器就可以做算术运算了。
四、字符编码
4.1西文字符
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。
标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
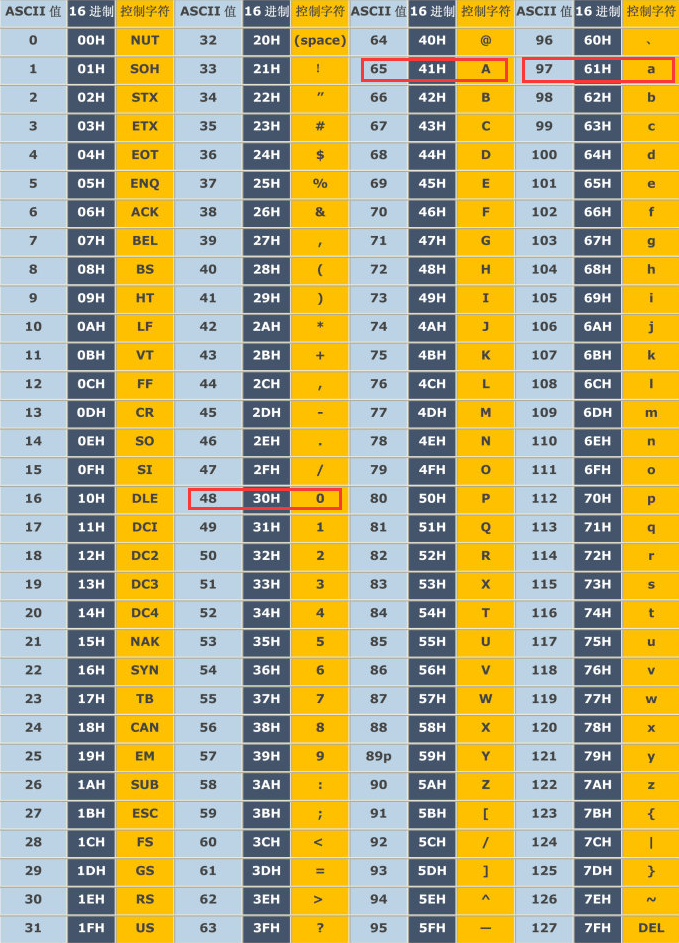
扩展ASCII码
ASCII码7位版本一般叫做基本ASCII码能表示127个字符
ASCII码8位版本一般叫做扩展ASCII码能表示256个字符
4.2 汉字字符
(1)汉字输入码(外码)
汉字输入码又称为外部码或者外码:在计算机中输入汉字时的代码,它是代表某一汉字的一组键盘符号,拼音编码,五笔编码。目前有一下几种:
(a)汉字拼音编码 以汉语拼音为基础的汉字输入编码,在汉语拼音键盘或经过处理的西文键盘上,根据汉字读音直接键入拼音。
(b)汉字字形编码所有的汉字都由横、竖、撇、点、折、弯有限的几种笔划构成,并且又可分为‘左右’、‘上下’、‘包围’、‘单体’有限的几种构架,每种笔划都赋予一个编码并规定选取字形构架的顺序,不同的汉字因为组成的笔划和字形构架不同, 就能获得一组不同的编码来表达一个特定的汉字,广泛使用的‘五笔字形’就属于这一种。
(c)汉字直接数字编码 利用一串数字表示一个汉字,电报码就属于这种。
(d)整字编码 设置汉字整字大键盘,每个汉字占一个键,类似中文打印机,操作人员选取汉字,机器根据所选汉字在盘面上的位置将其对应编码送入计算机。
(e)如今,通过语音和图像识别技术,计算机能直接将汉语和汉字文本转换为机器码,已经有多种语音识别系统和多种手写体、印刷体的汉字识别系统面世,相信还有更完美的产品推出。
(2)汉字字形码
汉字字型码又称汉字字模,用于汉字在显示屏或打印机输出。汉字字型码通常有两种表示方式:点阵和矢量表示方法。
汉字字型码又称汉字字模,用于汉字在显示屏或打印机输出。汉字字型码通常有两种表示方式:点阵和矢量表示方法。
用点阵表示字型时,汉字字型码指的是这个汉字字型点阵的代码。
根据输出汉字的要求不同,点阵的多少也不同。简易型汉字为16*16点阵,提高型汉字为24*24点阵,32*32点阵,48*48点阵等等。
点阵规模愈大,字型愈清晰美观,所占存储空间也愈大。
矢量表示方式存储的是描述汉字字型的轮廓特征,当要输出汉字时,通过计算机的计算,由汉字字型描述生成所需大小和形状的汉字点阵。
矢量化字型描述与最终文字显示的大小,分辨率无关,因此可以产生高质量的汉字输出。
(3)汉字机内码
又称为内码或者内部码:是汉字在计算机中储存时的二进制编码。
(4)区位码和国标码
《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB 2312—1980。
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
基本集共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。
把换算成十六进制的区位码加上2020H,就得到国标码。国标码加上8080H,就得到常用的计算机机内码。1995年又颁布了《汉字编码扩展规范》(GBK)。
GBK与GB 2312—1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。
区位码+2020H 得到国标码 + 8080H 得到机内码
(5)Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
UTF-8: UTF-8以字节为单位对Unicode进行编码