本文主要是介绍亲,你看到这张封面图,竟是用PyEcharts画的!信不信?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“Python数据之道”,选择“星标公众号”
只收藏文章,不点在看的,都是耍流氓

没错,就是它!酷不酷
来源:王的机器
作者:王圣元
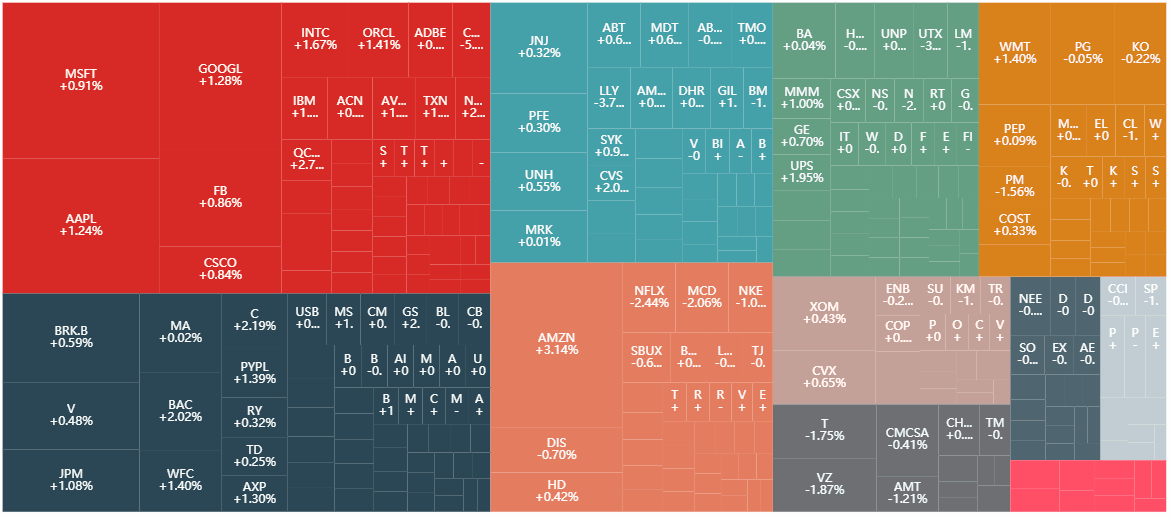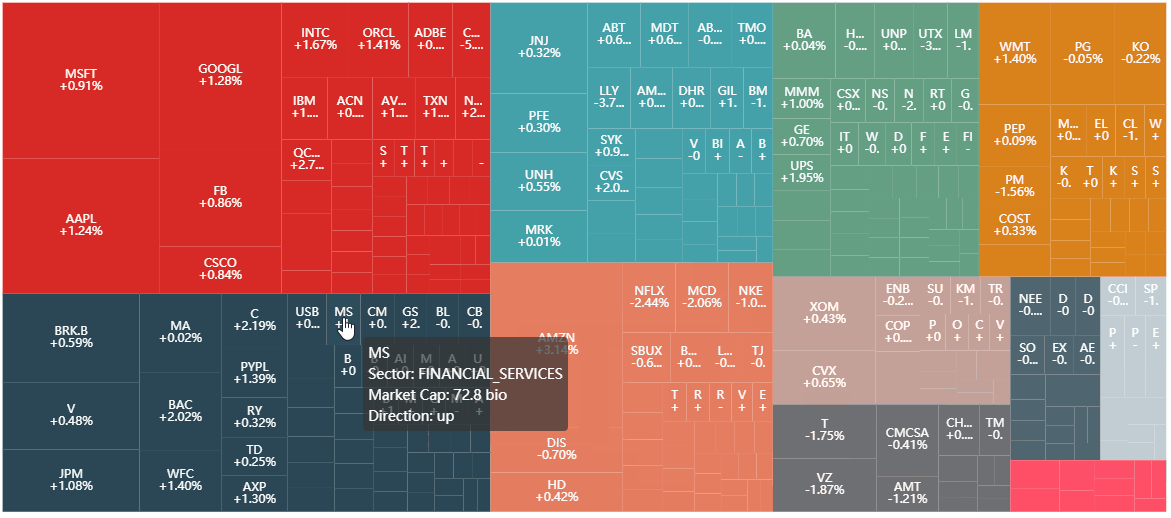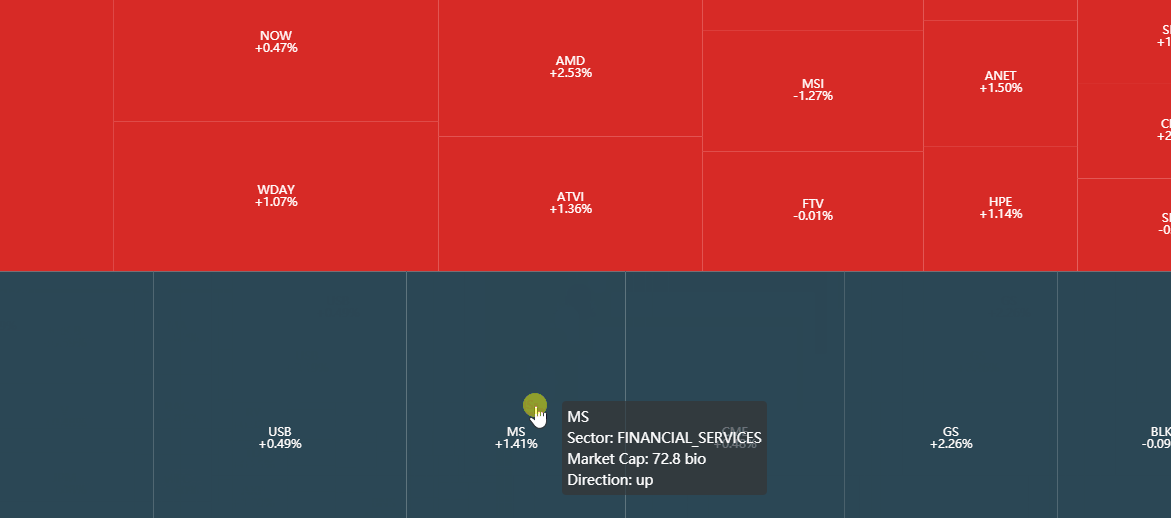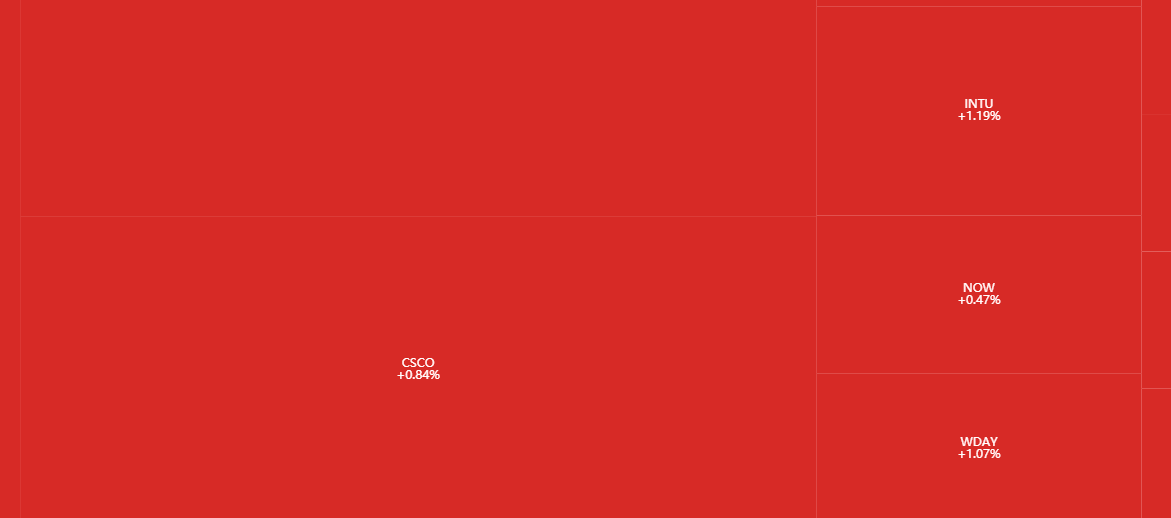
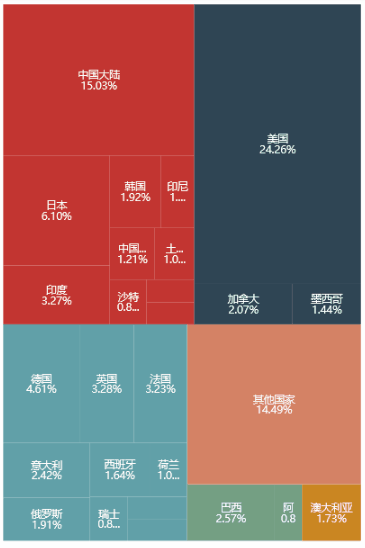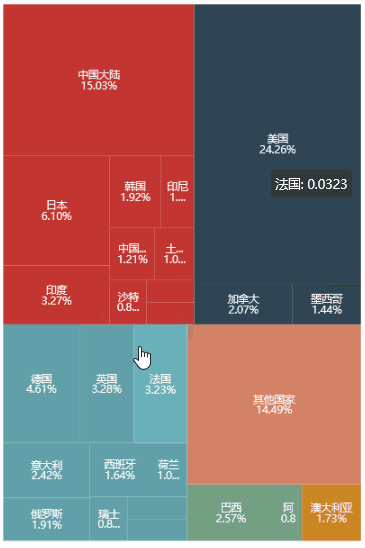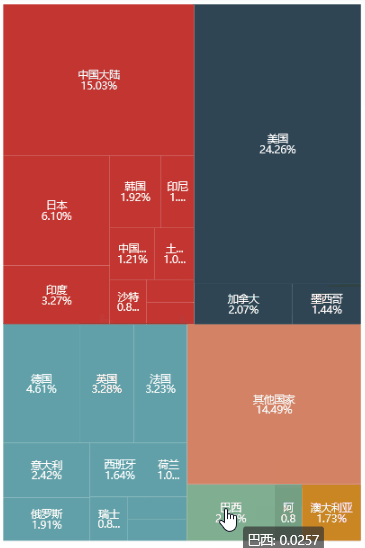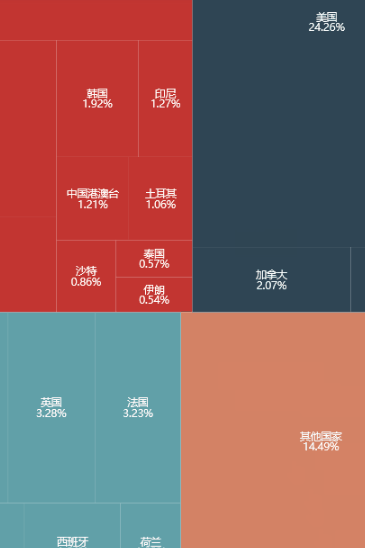
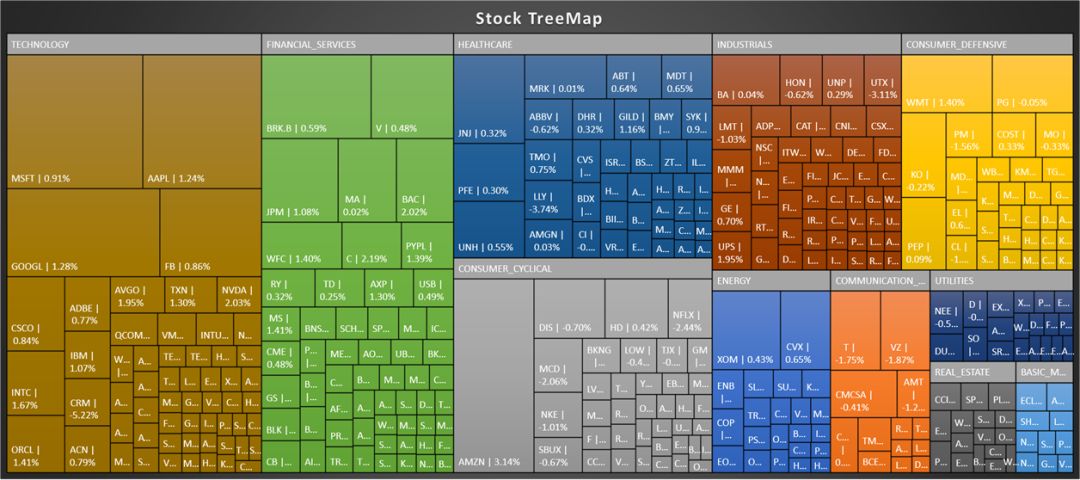
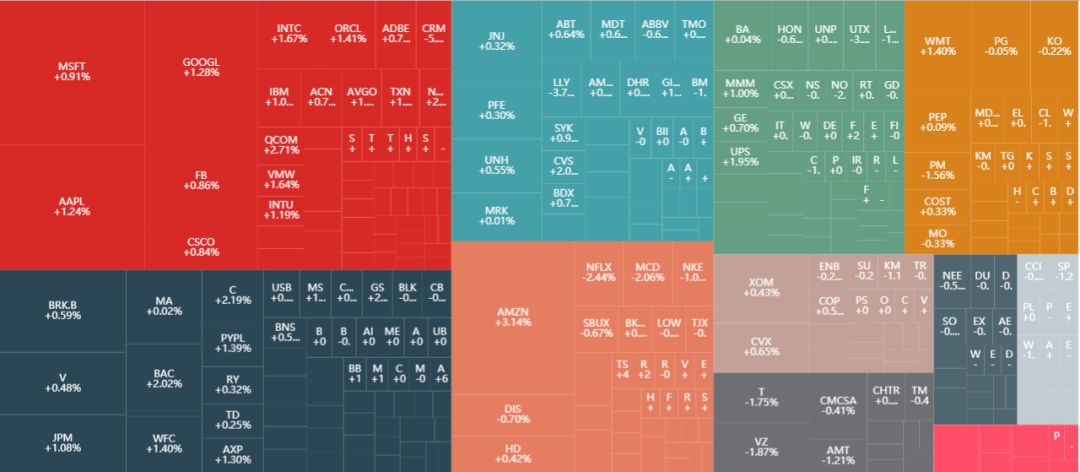
昨天晚上看到一个关于股票的矩形树状图 (tree map),真的太酷了,传达的信息太多了。

这鬼斧神工的细节大概率是用 d3.js 做的,鼠标移动到每个股票上居然还能看到它 (甚至和它同类股票) 前一天的走势图,我就想能不能用 PyEcharts 实现它或实现它一部分。
在做之前我什么都不会,但我知道我需要三个东西
数据 (从 Quantopian 取)
PyEcharts 例子 (从 Google 搜)
直觉 (这个靠平时积累和一些领域知识)
接着就是模仿着例子,套用着数据,一步一步完善。这是学习一个陌生的东西正确打开方式。

从之前的炫酷的 TreeMap 图中,我得到以下几个规律:
股票是按行业 (sector) 聚成一块的。
每个行业下的小块就显示着股票代号和日收益率。
每一小块的面积不一样大,看着微软 (MSFT)、苹果 (AAPL)、亚马逊 (AMZN) 和谷歌 (GOOGL) 最显眼就知道面积和市值成正比。
第一步我就明晰了需要的数据,就是每个股票的
代号、行业、价格 (日收益率)、市值
接着就在 Quantopian 中用 pipeline 一把梭 (这个靠练习,玩过几次就熟了)。首先引入所用需要的包。关于 Pipeline 的知识在〖张量 101〗讲过。

还记得〖机器学习之 Scikit-Learn〗讲过的用来数据预处理的元估计器 Pipeline 么?在 Quantopian 里你可以把你想在各种条件下获取的各种数据类型统统定义在make_pipeline() 里面。

前 3 行要获取收盘价、股票代号和市值。
后 4 行把范围限制在
可交易
市值前 500 的股票
收盘价有值
的股票上。
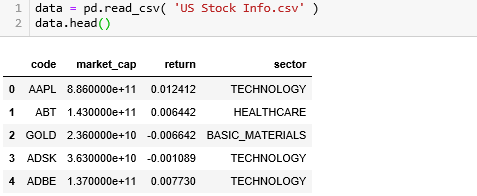
最后返回一个 DataFrame,columns 包括股票代号 (code)、行业 (sector)、日收益率 (return) 和市值 (market_cap)。
获取 2019 年 6 月 11 日的数据,并打印前五行。

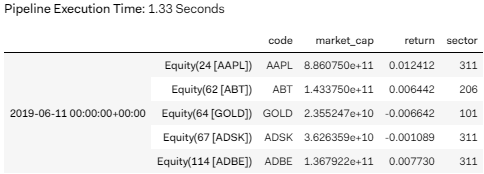
其他信息还好,但是 sector 怎么是数字啊?一查发现 Quantopian 里对行业有个映射表 (SECTOR_NAMES 是个字典)。

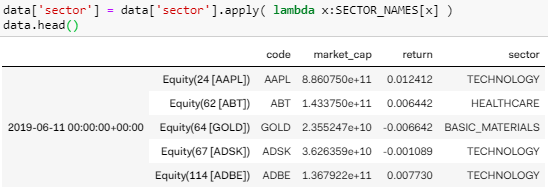
对 data['sector'] 用个 apply 函数,把用键把 SECTOR_NAMES 里的值获取出来 (字典是键值对还记得吗?)。
现在的 DataFrame 含「多索引」的行标签,这种类型的数据不方便存入 csv 中,因此我们用 reset_index() 将行标签全部转成列标签。
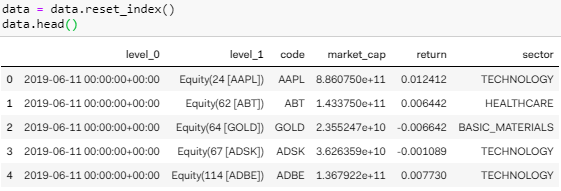
level_0 和 level_1 看着好碍眼,而且包含着多余信息,用 drop() 函数删掉。
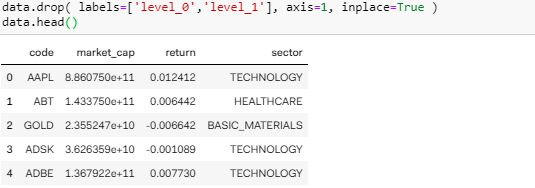
美滋滋的最后准备存成 csv 文件是要吐血,因为 Quantopian 里的数据很宝贵,它不允许外存因而把 to_csv 之类的函数当成黑名单了。

但这难得住我么?我把它每次分 50 行打印出来,手动复制粘贴到 csv 中。
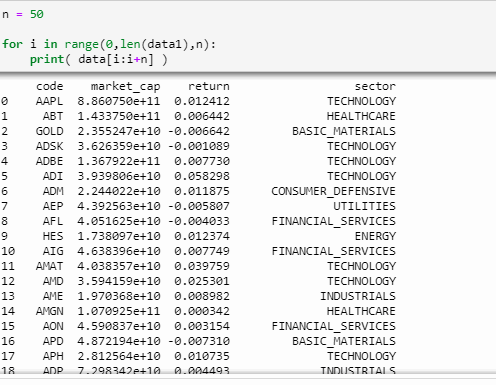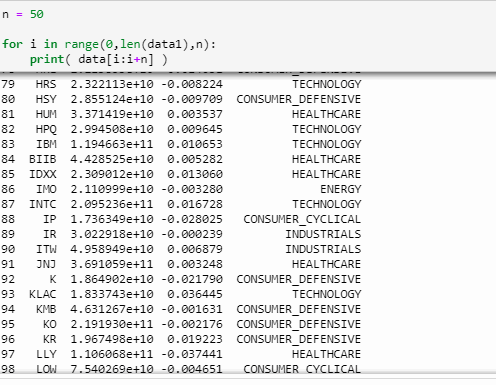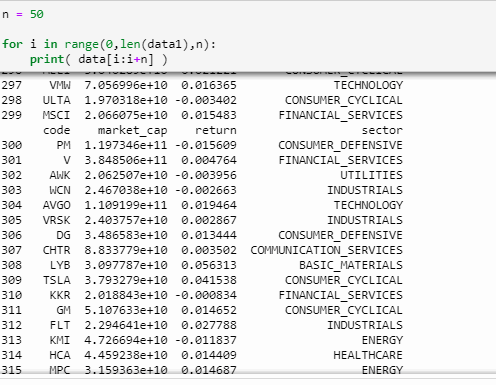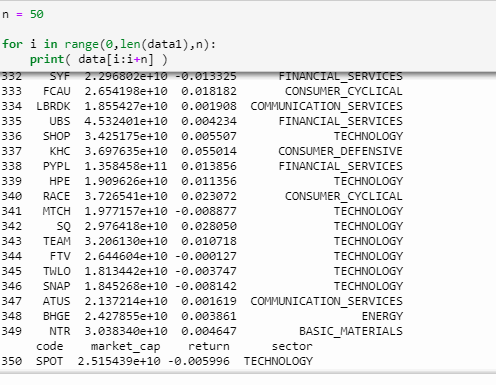
最终 csv 就长这个样子。
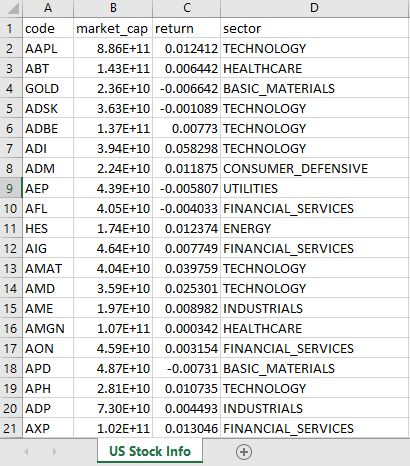
数据齐了,接下来看例子,希望抽出共性的东西用来模仿。
Google 一下 Pyecharts + Treemap,找到下面的例子。
https://www.evolutionarylearn.com/paper/treemap-pyecharts-python/
该例选择国际货币基金组织 (IMF) 公布的 2017 年全球各国 GDP 作为基础数据,计算各国 GDP 占全球 GDP 的比例,并利用 Treemap 进行可视化展示。用到的数据如下:
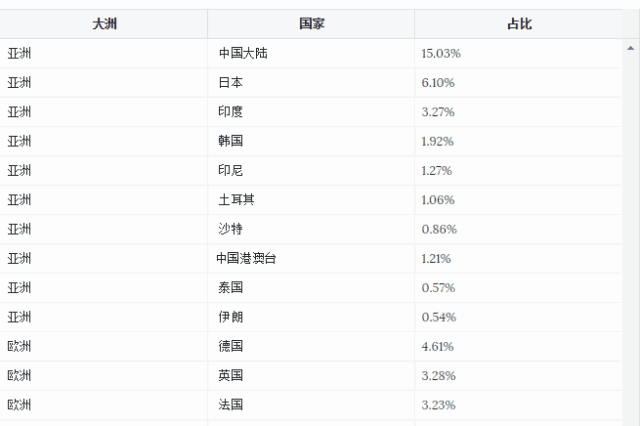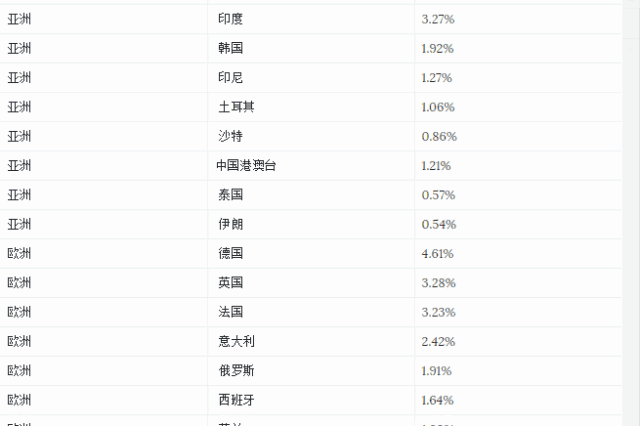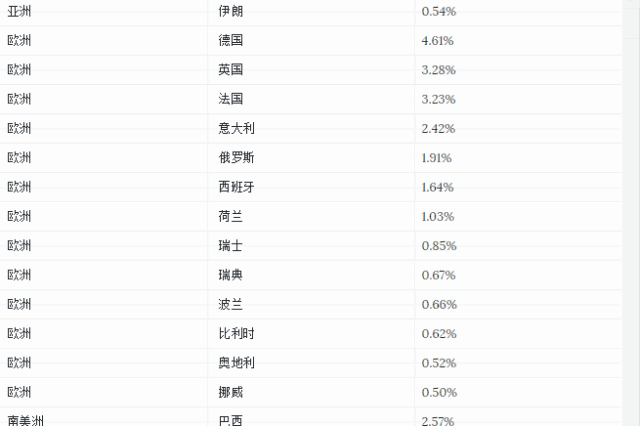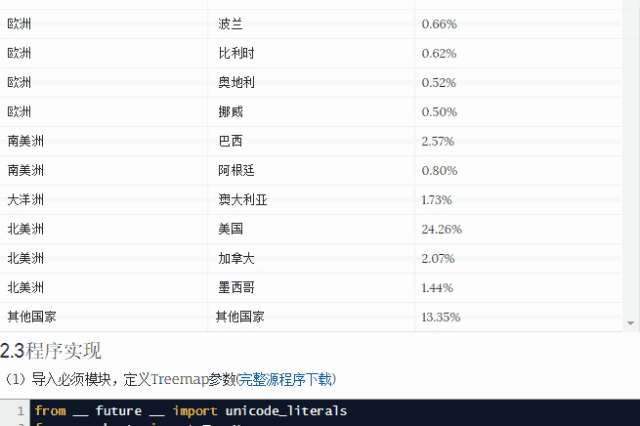
数据用以下代码表示:

PyEcharts 用到的数据不是 DataFrame 啊,而且字典里面套字典 (没关系,做个数据格式转换不就行了)。细看上面数据
第一层的 name 是五大洲,value 是该洲的总 GDP 比例,而 children 也有 name 和 value (第二层),分别是该洲包含的国家以及它们的 GDP 比例。
再看例子里的代码

很简单,除了 label_formatter 细节比较多 (为了打印不同格式的数据),其他就是 TreeMap 模块里的参数设置。只要 data 的格式正确,矩阵树形图就能画出来了。
类比这个例子和我们要解决的股票例子,得到以下联系:
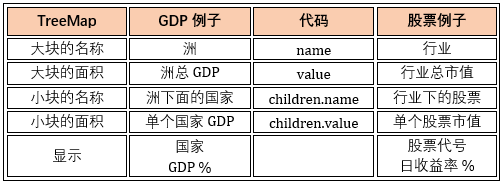
这样看,股票例子还麻烦一点,GDP 例子里面 GDP 即可以用来决定面积,又可以用来显示,而股票例子需要日收益率做显示。
这些都是小事,有了上面类比,模仿就容易多了,先写个雏形再慢慢提纯。
首先引入 PyEcharts 里的 TreeMap 模块,并引入 numpy 和 pandas 模块。
from pyecharts import TreeMap
import numpy as np
import pandas as pd从 csv 中读取信息并存成 DataFrame 取名为 data,打印前五行。
用 csv 中的数据,我手贱用 excel 里的 TreeMap 试了下,点击 Insert > Insert Hierarchy Chart > Treemap
结果图片很丑,而且灵活性差。
还是老老实实用 PyEcharts 吧。
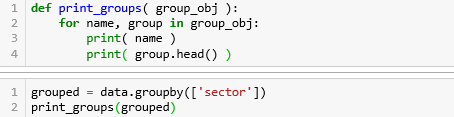
定义个 print_groups 函数便于打印组的名字和前五行信息,再按行业 ‘sector’ 来分组,这些操作在〖数据结构之 Pandas (下)〗都详细介绍过。
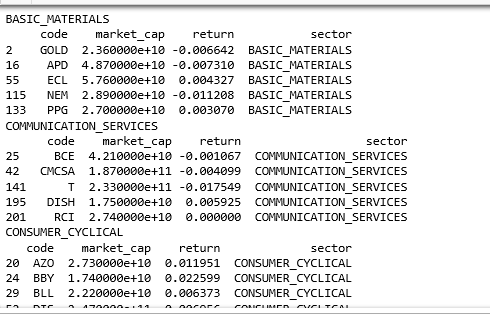
用 apply 方法在每个组中的 DataFrame 上 ‘market_cap’ 列上求和,这个「和」决定每个行业在 TreeMap 中分配到的面积。
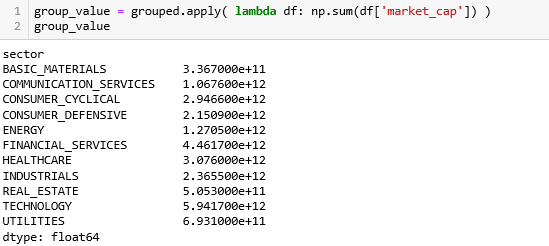
接下来就是核心操作,如何把「csv 读取出来的 DataFrame 格式」转换成「PyEcharts 中 TreeMap 函数要求的数据格式」。

第 1 行创建一个空的列表 data_for_treemap。
第 3-19 行用两层 for 循环来转成数据。
第一层 for 循环
第 6 行获取市值总和 (total_mktcap) 和行业 (sector)。
第 17-21 行生成外层字典 i_data,并逐一的添加在列表 data_for_treemap 上。
第二层 for 循环
第 5 行获取每个股票的代码 (code)、日收益率 (r) 和市值 (mktcap)。
第 8 行创建一个空的列表 children。
第 10-15 行生成内层字典 j_data,并逐一的添加在列表 children 上 (是外层字典 i_data 的值)。
转换后的数据如下:

数据弄好了,最后就只是调用 TreeMap 模块,不能更简单,比如第 1 行创建 treemap 并确定好其大小。体现细节的是第 6 -7 行两个黄色高亮函数,这里是 Python 高阶函数的用法,即把函数当成参数。

先看 label_formatter,该函数主要是在 treemap 的每个小块中显示股票代号和日收益率,样子如下

我们看看如何实现

这里 params 是第二层的字典,params.name 是一个列表,包含三个元素 [sector, code, return]。
第 2 行:如果 return 为正,添加一个加号 ‘+‘;如果为负,什么都不加因为本身自带减号 ‘-’。
第 3 -4 行:返回一个「二行的」字符 (注意 '\n' 有分行功能),第一行是股票代号,第二行是日收益率 (乘上 100,保留小数点 2 位,再加个百分号 %)。
最后做出来的效果如下 (和上面的比丑是丑点,但功能都在)

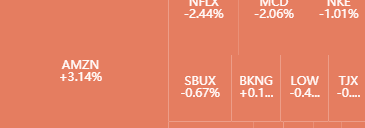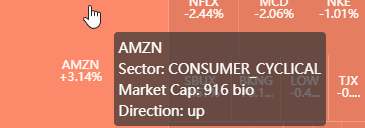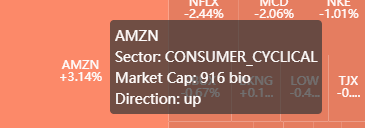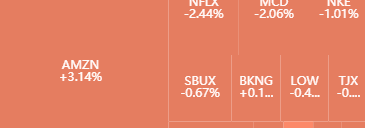
再看 tootip_formatter,该函数使得当鼠标放在 treemap 的每个小块上而显示提示框,样子如下

我们看看如何部分实现 (示例里的 tooltip 细节太强大了)

同样,这里 params 是第二层的字典,params.name 是一个列表,包含三个元素 [sector, code, return]。
第 2 行:根据 return 大于-小于-等于 0 来决定涨-跌-平。
第 3-6 行:返回一个「四行的」字符 (注意 '<br>' 有分行功能),分别显示股票代号、行业、市值 (以 billion 为单位)、和涨跌方向。
最后做出来的效果如下 (和上面的比丑得不忍直视,但是这就是 Pyecharts 和 d3.js 的差距)
最后来看个效果图,不是特别清楚,想拿到高清版按本文后续的提示来操作。
优点:
股票代号、日收益率信息都体现了,市值也在「块面积」上体现了,提示框还额外提供了股票涨跌的信息。
可以放大,可以缩小,也可以来回移动。
缺点:
每个行业的大块下没有母标签,如红色块应该出现个 TECHNOLOGY 这样的标签。
每个行业下的大块就一种颜色,像 d3.js 那个图,股票涨用绿色股票贴用红色更有感觉。
字体一样大,而不是根据面积的大小按比例决定,不能更快速地把注意力放在巨无霸身上。
提示框的信息没有 d3.js 图里提供的那么丰富。
不过就这样吧,至少比 Matplotlib 和 Excel 做出来的好看多了,在客户面前做展示也耍帅些,当然不能和 Javascript 比。
这次总结想说一些非技术上的东西:
兴趣导向或结果导向非常重要,比如我就觉得 TreeMap 酷而非常像实现它,即便一开始我什么都不会,这个兴趣会逼着我想办法解决问题。
在解决问题肯定会遇到很多挫折,比如我在 Quantopian 环境中处理半天数据发现不让外传到 csv 中,坚持去想办法解决,即便费点人力。其他技术上的问题,能明白说出你的问题很重要,这样的话用 google 查询基本95% 的技术问题都可以解决。
写程序平时要有一定的积累,但不用什么都要记住,人脑又不是电脑,有个大概的印象就可以了,剩下的就交给 google 或文档了。比如我们要计算据行业市值总和,那么在 DataFrame 数据上最简介的形式就是用 split-apply-combine。不用记住具体细节,要用时查找文档或例子一下子就会写了。
新知识太多,你根本学不完,有效的学习方法远比学到的东西重要。有了它,面对新知识,你知道只要你想学就一定学的会,这就够了。要用到它时再学吧,我现在也不太懂图神经网络、元学习呢,但我知道我可以征服它们。
代码
在公众号【王的机器】后台回复 “data” 获取代码和数据文件。
-------------------End-------------------
Python数据之道

据说学Python的只有10%的人关注了这个号,
还有很大潜力

今日主题:聊聊你对本文主题的一些感悟
留言格式:昵称 + day xx + 留言内容(字数不少于15字)
欢迎各位同学加入公众号读者分享交流群,在公众号后台回复 “微信群” 即可。

推荐 | 免费获取《Python知识手册》
Matplotlib最有价值的50个图表
可视化神器推荐(Plotly Express)
推荐一个牛逼的生物信息库-Dash Bio
用Python快速分析和预测股票价格
同学们,支持就请右下角点 !
!
这篇关于亲,你看到这张封面图,竟是用PyEcharts画的!信不信?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!