本文主要是介绍论文阅读笔记001:Some Practical Guidance for The Implementation of Propensity Score Matching,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、写在前面
- 二、论文总结、评价和应用。
- 三、论文讨论的主要问题
- 四、结论
- 五、文章脉络
- Abstract
- Section 1: Introduction
- Section 2: Evaluation Framework and Matching Basics
- Roy-Rubin Model
- Parameter of Interest and Selection Bias
- Unconfoundness and Common Support
- Section 3: Implementation of Propensity Score Matching
- 3.1 Estimating the Propensity Score
- 3.2 Choosing a Matching Algorithm
- Nearest Neighbor Matching(最近邻匹配)
- Caliper and Radius Matching (距离匹配/半径匹配)
- Stratification and Interval Matching(分层匹配/区间匹配)
- Kernel and Local Linear Matching(核匹配与局部线性匹配)
- Trade-offs in Terms of Bias and Efficiency
- 3.3 Overlap and Common Support(正值假设)
- 3.4 Assessing the Matching Quality (评估匹配质量)
- Choice-Based Sampling
- 3.6 When to Compare and Locking-in Effects?
- 3.7 Estimating the Variance of Treatment Effects?
- 3.8 Combined and Other Propensity Score Methods
- 3.9 Sensitivity Analysis
一、写在前面
本文来自对论文"Some Practical Guidance for The Implementation of Propensity Score Matching"的解读,需要读者了解因果推断的基本概念,如果需要快速了解相关概念,可以查阅我的因果推断专栏。
对于入门小白,重点推荐因果推断学习框架这篇文章,帮助你在开始学习前对这门学科有一个整体的把握。
论文的笔记方式采用了Ruth博士分享的方法,分为:
- 论文总结、评价和应用(需要自己思考和总结);
- 文章的主要问题(论文中可以找到,但要求自己归纳);
- 结论;
- 文章脉络(全文结构和关键点梳理)。
二、论文总结、评价和应用。
【总结】
PSM的5个步骤,以及每个步骤里涉及到的决策都有提及;总的来说非常全面。
【评价】
评估ATE估计的质量这一块儿涉及的内容不够深。
【应用】
工作:动调的处置效应挖掘。
三、论文讨论的主要问题
- 如何估计倾向性得分?
- 选择什么样的匹配算法?如何确定the region of common support(正值假设成立的区间)?
- 匹配的质量如何估计?处置效应和标准差怎么计算?
- 如果存在选择偏差怎么办?什么时候估计效应?
- 怎么做灵敏度分析?
四、结论


五、文章脉络
Abstract
提出了本文将要讨论的5个问题,上面👆第三部分已经提到了。
Section 1: Introduction
- 论述了目前匹配方法的广泛应用,综述了一些paper的研究方向。
- 介绍了选择偏差
因为我们想知道处置和不处置的差别,但是同一个个体不可能既被处置,又不被处置;
此时,如果我们以处置和不处置的群体的平均表现之差作为效应的估计,就可能出现选择偏差。
原因是两个群体可能不具备可比性。
【举个例子】:
高技能个体有更大的概率进入到一个培训项目,从而找到一份工作,获得更高的收入。(除了培训与否这个处置变量外,参加和不参加培训的人之间本身存在差异。)
提到选择偏差其实是想说,匹配方法有可能解决这一问题。
其核心思想是:在实验组和对照组中,找到各方面都比较相似的个体,从而使其具备可比性。隐含的假设是:条件独立假设,不了解的可以查看我的文章因果推断的三个基本假设快速学习,简单来说就是不存在未被观测到的混杂变量。文章后面的内容也都假定「条件独立假设」是成立的。
- 从“维度灾难”(curse of dimensionality)引入得分估计;
在出现高维特征的情况下,对所有的协变量进行匹配就会出现维度灾难。因此有人提出了「平衡得分」的方法,倾向性得分(给定一系列特征,被处置的概率)就是平衡得分的一种。
Propensity Score + Matching = PSM,PSM的流程是:

4. 给出了本文的结构:
- Section 2:基础背景知识介绍:
– 基本的评估框架;
– 一些我们感兴趣的处置效应
– PSM怎么解决评估问题,以及隐藏的重要假设。 - Section 3:PSM的具体实施步骤:
– 3.1 倾向性得分的估计(变量的选择、模型的选择);
– 3.2 比较不同匹配算法的优缺点;
– 3.3 如何检验实验组和对照组的overlap,以及如何实现 common support requirement?
– 3.4 怎么评估匹配的质量?
– 3.5 基于选择的抽样的问题。
– 3.6 when to measure programme effects。
– 3.7 评估处置效应的标准误差;
– 3.8 PSM怎么和其他的评估方法结合?
– 3.9 灵敏度分析。
– 3.10 programme heterogeneity, 动态选择问题, 合适的对照组的选择、实施匹配的可用软件回顾。 - Section 4:所有步骤的回顾和结论。
Section 2: Evaluation Framework and Matching Basics
Roy-Rubin Model
估计因果效应的标准框架是Roy-Rubin的潜在因果模型(我的文章因果推断学习框架有提到)。因为对于个体来说,只有一种结果可以被观测到(另一种未被观测到的结果称之为反事实结果),所以个体处置效应是不可能得到的,因此研究主要关注平均处置效应。
Parameter of Interest and Selection Bias
这部分内容给出了ATE和ATT的计算公式,想要快速区分因果推断中的各种效应(ITE、ATE、LATE、CATE…),可以查阅因果推断中的各种处置效应这篇文章。这里就不再赘述啦!
比较有意思的是这里给出了选择偏差的计算公式,我们快速推一下:
个体处置效应的计算公式:
τ i = Y i ( 1 ) − Y i ( 0 ) (0) \tau_i = Y_i(1) -Y_i(0) \tag{0} τi=Yi(1)−Yi(0)(0)
平均处置效应(针对总体而言)的计算公式是:
τ A T E = E ( τ ) = E [ Y ( 1 ) − Y ( 0 ) ] (1) \tau_{ATE} = E(\tau) = E[Y(1) -Y(0)] \tag{1} τATE=E(τ)=E[Y(1)−Y(0)](1)
但是我们经常很难观测到ATE,举个例子:某个项目是针对低收入群体的,这里我们并不关心该项目对百万富翁的影响,所以其实最重要的评价参数其实是干预组的处置效应,比如这个例子里的干预组就是低收入群体,它的数学表达是:
τ A T T = E ( τ ∣ D = 1 ) = E [ Y ( 1 ) ∣ D = 1 ] − E [ Y ( 0 ) ∣ D = 1 ] (2) \tau_{ATT} = E(\tau|D=1) = E[Y(1)|D=1] - E[Y(0)|D=1] \tag{2} τATT=E(τ∣D=1)=E[Y(1)∣D=1]−E[Y(0)∣D=1](2)
显然这里的 E [ Y ( 0 ) ∣ D = 1 ] E[Y(0)|D=1] E[Y(0)∣D=1]是一个反事实结果,所以需要选择一个合适的可以替代这一项的表达 E [ Y ( 0 ) ∣ D = 0 ] E[Y(0)|D=0] E[Y(0)∣D=0],因此上式转化成了:
E [ Y ( 1 ) ∣ D = 1 ] − E [ Y ( 0 ) ∣ D = 0 ] = E [ Y ( 0 ) ∣ D = 1 ] − E [ Y ( 0 ) ∣ D = 0 ] + τ A T T E[Y(1)|D=1] - E[Y(0)|D=0]= E[Y(0)|D=1] - E[Y(0)|D=0] + \tau_{ATT} E[Y(1)∣D=1]−E[Y(0)∣D=0]=E[Y(0)∣D=1]−E[Y(0)∣D=0]+τATT
选择偏差即为:
E [ Y ( 0 ) ∣ D = 1 ] − E [ Y ( 0 ) ∣ D = 0 ] E[Y(0)|D=1] - E[Y(0)|D=0] E[Y(0)∣D=1]−E[Y(0)∣D=0]
所以只有在 E [ Y ( 0 ) ∣ D = 1 ] − E [ Y ( 0 ) ∣ D = 0 ] = 0 E[Y(0)|D=1] - E[Y(0)|D=0] = 0 E[Y(0)∣D=1]−E[Y(0)∣D=0]=0时才能估计到真的 τ A T T \tau_{ATT} τATT。
Unconfoundness and Common Support
这部分内容介绍了无偏假设和正值假设,我的文章因果推断的3个基本假设里有详细的介绍。
Section 3: Implementation of Propensity Score Matching
进入重头戏,正式开始介绍PSM的实现。
3.1 Estimating the Propensity Score
两个核心问题:
- 选择什么模型估计得分;
- 选择什么变量进入模型。
对于第一个问题,文章分了两种场景介绍:
| 场景 | 推荐模型 | 其他可选模型 | 备注 |
| Binary Treatment | logit 或 probit 模型 | any discrete choice model | 此场景下模型的选择不是特别重要,logit和probit的结果一般相近 |
| Multiple Treatments | 多项式probit模型、多个二项式模型 | 多项式logit模型 | 此场景下模型的选择更加重要 |
备注:multiple treatments场景下,多项式 logit 基于比多项式 probit 模型更强的假设,所以后者是首选。但多项式 probit 模型计算更加复杂,所以通常采用一系列二项式模型。
这里的logit模型和probit模型,留着后面用一篇文章再介绍一下。(todo)
对于第二个问题,文章给到了一些关键的输入:
1. 为什么变量的选择是重要的?
因为匹配策略是基于条件独立假设的,这要求结果变量必须独立于处置变量(给定propensity score),因此,我们需要选择一组变量能够满足这个条件。
2. 什么样的变量需要被放入模型?
只有同时影响处置变量和结果变量的的变量,需要被放进来。
只有不被处置影响的变量(中介变量)可以被放进模型。
这里有些不理解。(todo)
3. 是否引入变量越多越好?
Bryson的观点:
should avoid over-parameterized models.
首先,加入额外的变量会导致正值假设无法满足;其次会加大倾向得分的方差。
Augurzky and Schmidt (2001) 做实验验证了这一观点:
Rubin and Thomas (1996) 有一些不同的观点,他认为只有当变量既与结果无关,也不是一个合适的协变量(掐人中,约等于没说?)时才不用放进模型。
4. 三个用于选择变量的统计学策略:
| 策略 | 核心思想 | 解释 | 备注 |
| Hit or Miss Model | 预测率指标:变量的选择用于最大化样本间的预测正确率。 | 如果一个样本的倾向得分大与接受处置的人群比例,则被分类为1,否则被分类为0。一个变量是否被引入,就看这个分类正确率是否增大或减少。 | 但是要注意,倾向得分估计不是尽可能预测处置的概率,而是平衡所有的协变量, |
| Statistical Significance | 统计显著性 | 先只在模型里放入一些基本的变量,如年龄、地域信息等,然后逐个加入变量,如果一个变量在常规水平上具有统计显著性,则保留该变量。 | 也可以和hit or miss方法结合,即只有一个变量既有统计显著性,又能增加预测准确率才保留。 |
| Leave-One-Out Cross-Validation | 基于拟合优度 | 先只放入两个变量到模型,然后添加其他的变量块,比较结果均方误差 | CIA的可信度和估计的方差之间存在一个有趣的权衡。当选择很多变量时,正值假设可能难以满足,但是CIA很容易满足;反之,正值假设容易满足,但是CIA难以满足。 |
- 一个小的技巧:Overweighting some Variables
两种方式去加强某些特征的重要性:
(1)精确匹配部分重要特征,余下的再做matching;
(2)外层根据重要特征分组,再在各个组内实施matching。
- 倾向得分的替代选择
the underlying index of the score estimation.
这里也没有看懂具体是指什么方法,作者引用了论文,可能要翻阅后才能理解。(todo)
3.2 Choosing a Matching Algorithm
不同匹配算法的差异主要体现在以下两点:
- 对照组的选择;
- 处理正值假设的方式。
各种匹配算法的汇总:
当样本量大到一定程度时,理论上所有的匹配算法都会给出相同的结果(因为会无限趋近于精确匹配)。然而当样本小的时候,这里会存在偏差和误差的trade-off。怎么理解估计的偏差和方差。(todo)
到底怎么选呢?视情况而定,比如:
- 当某个组别样本很少时:选择有放回采样;
- 当有大量的对照组时:选择KNN;
- 尝试多种算法:如果结果相似,那么选择哪种算法可能并不重要,如果不相似,就要做更多思考。

Nearest Neighbor Matching(最近邻匹配)
- 核心思想:选择PS最接近的样本匹配;
- 一些NNM的变种:有无放回取样、KNN。
有无放回取样本质是偏差和方差的权衡:
(1)有放回取样:平均匹配质量上升,偏差小,方差大;
解释:当处置组和对照组的PS分布非常不同时(比如处置组是高分的样本多,低分的样本少,对照组相反),如果不允许放回,那么有些高分的只能与低分的匹配,如果允许放回,那么匹配的会更好,估计的偏差会减少。但同时会增大估计器的方差。(怎么理解?(todo))
(2)无放回取样(匹配的顺序也会影响结果,需要保证随机):偏差大,方差小;
解释:
Caliper and Radius Matching (距离匹配/半径匹配)
当最近的邻居得分仍然相差很大时,NN会给出一个差的匹配结果,Caliper and Radius Matching可以避免这个问题。
- 核心思想:
Caliper Matching: PS得分最近,且PS得分相差 < C a l i p e r Caliper Caliper的才可以被匹配;
Radius Matching: 比 Caliper Matching更严格,(没理解(todo))
- 名词解释
Caliper(propensity range):匹配时,PS得分最大不能相差多少;本质上在保证正值假设。
- 难点:怎么定 C a l i p e r Caliper Caliper?
Stratification and Interval Matching(分层匹配/区间匹配)
- 核心思想
在外层将PS分层,然后每个组内去算平均处置效应。
- 难点:划分几个区间?
Cochran (1968) shows that five subclasses are often enough to remove 95% of the bias associated with one single covariate.
检测区间划分是否合理的方法:去看各个区间的PS是否均衡。
Kernel and Local Linear Matching(核匹配与局部线性匹配)
是一种非参数估计的方法。(想了解参数估计和非参数估计,可以查看我的博客参数估计)
- 核心思想:
KM可以看作是反事实结果在一个截距上的加权回归,其权重由核权给定。
KM和LLM之间的区别在于,LLM除了包含截距外,还包括治疗个体倾向得分中的线性项。
- 优缺点:
优点:因为运用了更多的信息,所以方差更小;
缺点:可能会用一些差的匹配结果。
Trade-offs in Terms of Bias and Efficiency
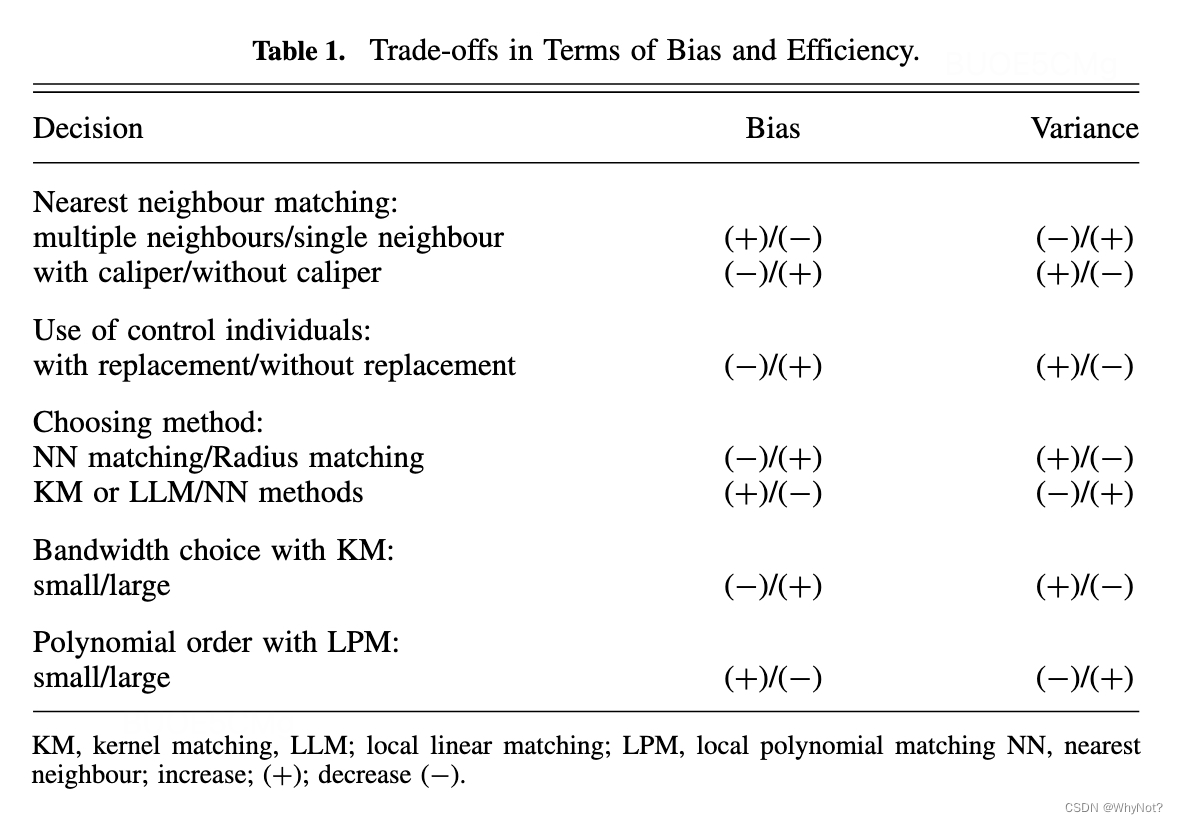
3.3 Overlap and Common Support(正值假设)
估计处置效应的主要误差来源——违反了正值假设。因此需要检验实验组和对照组的共同支持域,方法:
- 可视化:看PS在两组的分布。
如何确定共同支持域?
| 方法 | 核心思想 | 备注 |
| Minima and Maxima Comparison | 处置组和对照组的PS的[min, max]区间的交集 | 延伸的方法包括:tenth smallest and tenth largest observation。 |
| Trimming | 在共同支持区间内,处置组和被处置组的密度都大于q | S_Pq = {Pq : ˆf (P|D = 1) > q and ˆf (P|D = 0) > q} |
3.4 Assessing the Matching Quality (评估匹配质量)
所有评估方法核心思想:比较匹配前后的实验组和对照组的分布,看是否仍然有较大差异。如果有,可能需要采取一些补救措施(引入交互项或者高阶项)。
一共讲了4种评估方式:
| 方法 | 思想 | 备注 |
| standardized bias(标准偏差) | 评估x变量边际分布距离 | 一般认为低于3%或5%可用。 |
| t-test | 使用双样本t检验来检查两组的协变量均值是否存在显著差异 | 预期匹配前有较大差异,匹配后无显著差异。 |
| Joint Significance and Pseudo-R2 | 重新在匹配的样本上估计PS,比较匹配前后psedo-R2 | 伪r2表示回归量X解释参与概率的程度 |
| Stractification Test(分层测试) | 先根据PS得分对数据分层,再在每个分层中做t检验 |
备注:SB计算公式:
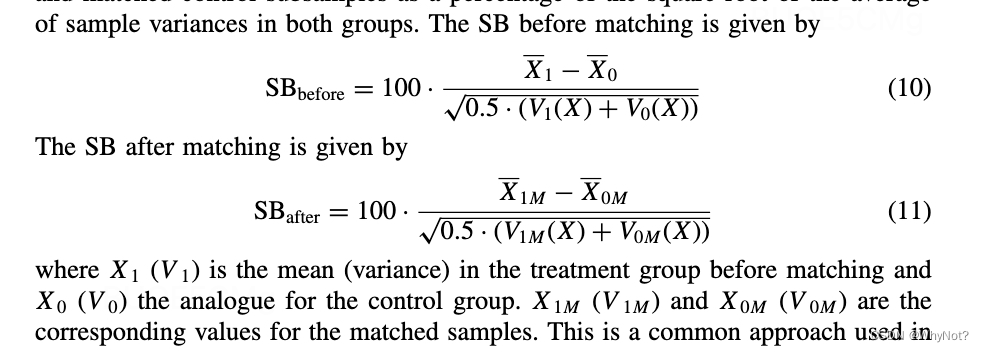
怎么理解SB这个值?t检验的过程?(todo)
Choice-Based Sampling
- 什么叫作基于选择的抽样?
得到的样本都是与选择的流程相关的。可能不是随机的,因此有较高风险产生偏差。
偏差和误差的区别?(todo)
- 解决方法:
single NN matching: PS(with wrong weights) or odds ratio均可
KM等其他考虑绝对距离的matching方式:需要用odds ratio.
3.6 When to Compare and Locking-in Effects?
- When to Compare
(1)在政策开始实施的时候;
(2)结束的时候。(更常用)
举个例子:
假设一个劳动市场的项目1月开始6月结束,
在项目结束的时候评估意味着,在7月份进入劳动市场的人和7月没有进入的人进行比较。(两个缺点:7月的环境相比1~6月可能已经发生了较大变化;内生性问题。内生性问题和外生性问题?(todo))
- 锁定效应
锁定效应是指两个相同意义上的科学技术产品,一个是较先进入市场,积累了大量用户,用户对其已产生依赖;
另一个较晚才进入市场,同种意义上的科学产品,用户对第一个已经熟悉了解,而另一个还需要用户重新学习了解,产生了很大麻烦。
因此较晚进入市场的那个很难再积累到用户,从而慢慢退出市场。先进入市场的那个相当于已经锁定了同种类型的科学产品,从而发展越来越快。
“锁定效应”本质上是产业集群在其生命周期演进过程中产生的一种“路径依赖”现象。
3.7 Estimating the Variance of Treatment Effects?
方差估计的三种方式:
| 方法 | 核心思想 | 备注 |
| 自举法(boostrapping) | 重复采样R次,获得R种样本,然后估计R个ATE,依据这R个ATE的分布,去估计整体的均值和标准差。 | 缺点是比较耗时。 |
| 方差近似(Lechner) | 计算公式如下图 | 公式兼顾了重复匹配(可放回抽样)的方式。假设处置组和对照组中结果变量方差的同方差性,并且结果方差不依赖于估计的倾向得分。 |
| 方差估计器(Abadie and Imbens) | 公式见下图 |
方差近似:
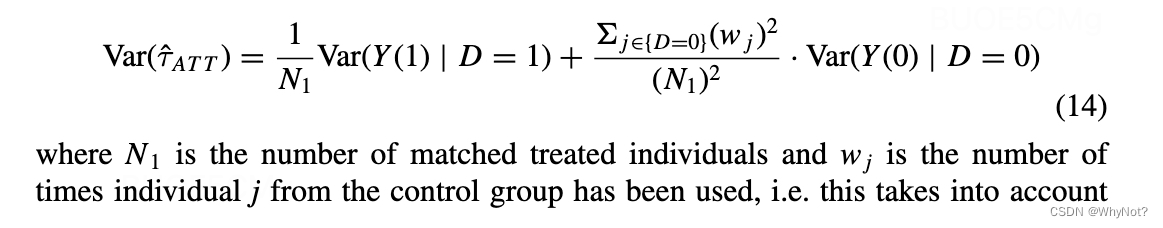
方差估计器:

3.8 Combined and Other Propensity Score Methods
一共介绍了三种组合的方法:
- Matching with DID:消除了由于时不变不可观测而导致的可能偏差;
- regression- adjusted matching estimators(回归调整的匹配估计器)
This can be useful because matching does not address the relation between covariates and outcome. Additionally, if covariates appear seriously imbalanced after propensity score matching (inexact or imperfect matching) a bias correction procedure after matching may help to improve estimates.
- weighting on PS:帮助得到处置组和对照组平衡的样本。
3.9 Sensitivity Analysis
介绍了两种灵敏度分析的方式:
(1)是否违反隐含的假设?
方法一:Rosenbaum(2002)
本质的问题:是否存在未被观测到的变量会影响处置效应?
核心思想:假设被处置的概率 π i \pi_i πi不只受观测到的变量 x i x_i xi的影响,还受到未被观测到的 u i u_i ui影响,即:
π i = P r ( D i = 1 ∣ x i ) = F ( β x i + γ u i ) \pi_i = Pr(D_i=1|x_i)=F(\beta x_i+\gamma u_i) πi=Pr(Di=1∣xi)=F(βxi+γui)
显然,如果不存在未被观测到的混杂变量, γ = 0 \gamma=0 γ=0;然而如果存在混杂变量,则 γ ≠ 0 \gamma\neq0 γ=0,即相同的 x i x_i xi下也会有不同的被处置概率。基于这种思想,可以计算显著性水平和置信区间。
方法二:Andrea Ichino
核心思想:改变 U U U的分布,观察ATT的变化。
方法三:估计一个已知为0的处置效应。
没有理解?(todo)
(2)计算参数的有效边界。
这篇关于论文阅读笔记001:Some Practical Guidance for The Implementation of Propensity Score Matching的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







