本文主要是介绍(5)EII Kapacitor模块详解(附机器学习案例实操),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 前言
基于EII系列的前4篇文章,我们基本了解了EII的安装,EII消息总线,以及时序数据的采集(Telegraf模块),存储(InfluxDB模块)和可视化(Grafana)过程。
本文我们将进入EII时序栈中最为复杂的一个模块:数据处理模块Kapacitor。
EII3.0中用到的Kapacitor版本是1.5.4,官方教程链接:https://docs.influxdata.com/kapacitor/v1.5/
Kapacitor是一个开源的数据处理框架,同样由InfluxData公司发布,是TICK栈的其中一个组件。使用Kapacitor可以很方便的创建报警,ETL,异常检测等任务。Kapacitor主要特点如下:
- 支持流处理和批处理两种模式。
- 支持定时任务。
- 全面兼容InfluxQL语法。
- 支持将处理结果存回InfluxDB数据库。
- 支持集成用户自定义的处理算法。
- 支持集成多种报警软件: HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack等。
2. 案例实操
2.1 温度监控案例
Kapacitor有着自己的一套编写规则的脚本语言TICKScript,我们仍然以温度监控的案例,来实操一下,实现一个简单的温度值过滤的案例。
2.1.1 配置阶段
首先,我们去到EII Kapacitor模块的目录下“IEdgeInsights/Kapacitor”。Kapacitor模块下所有的规则脚本都保存在目录"tick_scripts"下。我们在其中创建一个新的脚本文件"temp_filter.tick",并在其中输入如下内容:
dbrp "datain"."autogen"var data0 = stream|from().database('datain').retentionPolicy('autogen').measurement('point_data').where(lambda: "temperature" < 20 OR "temperature" > 25)|influxDBOut().buffer(0).database('datain').measurement('point_filter').retentionPolicy('autogen')
上述TICKScript实现了一个简单的数据过滤的功能,首先它通过"from()"接口从数据库"datain"的数据表"point_data"中读取数据,然后它通过"where()"语句进行了数据的筛选,将小于20和大于25的数据筛选出来,那么处于20到25之间的数据就过滤掉了。然后,再通过"influxDBOut()"接口将数据输出到数据库"datain"的另外一张表"point_filter"里。
完成了处理规则TICKScript的编写,接着我们要在EII的配置文件中引用它。打开"Kapacitor/config.json"文件,在其中的"task"字段增加一个新的任务,将刚刚定义的"temp_filter.tick"脚本引用进来。"Kapacitor/config.json"文件内容,参考如下:
{"config": {"cert_type": ["zmq", "pem"],"influxdb": {},"task": [{"task_name": "go_point_classifier","tick_script": "go_point_classifier.tick","udfs": [{"type": "go","name": "go_classifier"}]},{"task_name": "temp_filter","tick_script": "temp_filter.tick"}]},"interfaces": {}
}
完成上述配置之后,我们需要将目录"tick_scripts"挂载到容器中,这样可以避免稍后重新编译Kapacitor的docker容器镜像。在文件"Kapacitor/docker-compose.yml"中"volumes"字段下,增加"tick_scripts"目录的挂载,参考如下(最后一行):
volumes:- "vol_temp_kapacitor:/tmp/"- "vol_eii_socket:${SOCKET_DIR}"- "vol_dev_shm:/dev/shm"- ./Certificates/Kapacitor:/run/secrets/Kapacitor:ro- ./Certificates/rootca/cacert.pem:/run/secrets/rootca/cacert.pem:ro- ../Kapacitor/tick_scripts:/EII/tick_scripts
2.1.2 运行阶段
接下来,我们就可以参考先前文章中温度监控案例的步骤,将EII软件栈运行起来。
首先,在目录"IEdgeInsights/build/usecases"下,创建一个模块清单文件"test-mqtt.yml",并添加如下模块信息:
AppContexts:
- ConfigMgrAgent
- tools/mqtt/broker
- tools/mqtt/publisher
- Telegraf
- InfluxDBConnector
- Grafana
- Kapacitor
可以看到,这里引用了EII时序栈相关的4个模块(Telegraf, InfluxDB, Grafana, Kapacitor),并使用了EII自带的MQTT发布模块"tools/mqtt/publisher"来发布测试数据。
接下来,先确认MQTT发布模块(目录"tools/mqtt/publisher")发布的数据类型。打开文件"tools/mqtt/publisher/docker-compose.yml",确认文件末尾的"command"是如下内容:
command: ["--temperature", "10:30"]
基于上述配置,MQTT发布模块将会发送10到30之间随机的温度值,默认的发送频率是1秒,默认topic的名字是"temperature/simulated/0"。
接着,确认"Telegraf"模块的配置。先看到"Telegraf/config.json"文件,在先前文章的实操中,大家可能配置了EII Message Bus相关的"Subscribers"接口,如果配置了这里可能先去掉 (避免遇到Bug),将"Telegraf/config.json"文件还原到初始设置,内容参考如下:
{"config": {"cert_type": ["zmq", "pem"],"influxdb": {"dbname": "datain"},"publisher": {"measurements": ["*"],"profiling": "false"}},"interfaces": {"Publishers": [{"Name": "publisher","Type": "zmq_tcp","EndPoint": "0.0.0.0:65077","Topics": ["*"],"AllowedClients": ["*"]}]}
}
然后,我们检查"Telegraf/config/Telegraf/Telegraf_devmode.conf"配置文件,在其中搜索(VSCode快捷键Ctrl + F)关键字"temperature/simulated/0",找到telegraf mqtt input插件的定义(EII已默认配置好mqtt input插件,这里不用修改什么,只是检查一下)。可以看到Telegraf接收topic名为"temperature/simulated/0"的消息,并将其重命名为"point_data",这里的’point_data"对应的就是数据存到数据库之后,数据表的名字。
[[inputs.mqtt_consumer]]
# ## MQTT broker URLs to be used. The format should be scheme://host:port,
# ## schema can be tcp, ssl, or ws.servers = ["tcp://$MQTT_BROKER_HOST:1883"]
#
# ## MQTT QoS, must be 0, 1, or 2
# qos = 0
# ## Connection timeout for initial connection in seconds
# connection_timeout = "30s"
#
# ## Topics to subscribe totopics = ["temperature/simulated/0", ]name_override = "point_data"data_format = "json"
#
# # if true, messages that can't be delivered while the subscriber is offline
# # will be delivered when it comes back (such as on service restart).
# # NOTE: if true, client_id MUST be setpersistent_session = false
# # If empty, a random client ID will be generated.client_id = ""
#
# ## username and password to connect MQTT server.username = ""password = ""
最后,确认"Telegraf/docker-compose.yml"文件中,是否将配置文件挂载到了容器内,参考如下(最后一行):
volumes:- "vol_temp_telegraf:/tmp/"- "vol_eii_socket:${SOCKET_DIR}"- ./Certificates/Telegraf:/run/secrets/Telegraf:ro- ./Certificates/rootca/cacert.pem:/run/secrets/rootca/cacert.pem:ro- "../Telegraf/config/Telegraf/Telegraf_devmode.conf:/etc/Telegraf/Telegraf/Telegraf_devmode.conf"
完成以上确认,现在我们终于可以启动EII软件栈了(经过前面几篇文章的实操,读者应该比较熟悉EII软件栈启动流程了)。
- 首先编译配置文件。
$ cd IEdgeInsights/build
$ sudo -E python3 builder.py -f usecases/test-mqtt.yml
- 由于我们修改的文件都是通过挂载的方式挂载到容器中,所以无需重新编译docker镜像,直接启动EII软件栈即可。
$ ./eii_start.sh
-
按照先前文章介绍的方法,进入Grafana界面,创建一个Dashboard。然后创建一个图表显示“point_data”表中的数据,再创建另外一个图标显示"point_filter"表中的数据。

通过对比两个表格中的数据可以验证,Kapacitor模块中"temp_filter.tick"脚本的数据过滤生效了。 -
关闭EII软件栈的命令。
$ docker-compose down
2.2 钢板缺陷检测案例
上一节,我们尝试通过Kapacitor的TICKScript来编写了一个简单的数据过滤算法。
这一节,我们来实操一个更加复杂的案例:钢板缺陷检测案例。该案例中会用到随机森林(Random Forest)机器学习算法。
在前言中介绍Kapacitor特点时,其中有一条提到"支持集成用户自定义的处理算法",那么机器学习算法就是通过Kapacitor的用户自定义功能块进行集成的,英文叫做UDF(User Defined Function)。
2.2.1 数据集准备
笔者在Kaggle平台上找到了一份公开的"钢板缺陷"的数据集"Faulty Steel Plates"。
该数据集一共有1941笔数据。提供了27个维度的信息,最终可以分析出6种钢板缺陷的分类。
原始数据可从如下链接下载:
https://www.kaggle.com/datasets/uciml/faulty-steel-plates
拿到数据后,我们需要做一些预处理。
- 需要将原始数据的标签从多列的方式转化成单列。

- 需要将原始数据拆分成"训练集"和"测试集"。"训练集"用于训练,"测试集"用于测试。笔者已经将拆分好的数据集上传,大家可通过下面链接直接下载。1552笔数据用于训练,389笔数据用于测试。
- 训练集(1552笔数据):https://pan.quark.cn/s/0d64b27d1ce3
- 测试集(389笔数据):https://pan.quark.cn/s/99d438361e42
接下来,我们按照数据流的顺便依次配置EII的各个模块,数据流顺序如下:MQTT发布模块 → Telegraf模块 → InfluxDB模块 → Kapacitor模块 → Grafana模块。
InfluxDB模块和Grafana模块,我们可以采用EII默认的配置,无需修改。那么接下来我们依次介绍MQTT发布模块,Telegraf模块,Kapacitor模块的配置步骤。
2.2.2 配置MQTT发布模块
MQTT发布模块(位于EII源码目录"tools/mqtt/publisher"下)是数据产生的源头,我们需要让它将steel plate"测试集"中的数据通过MQTT协议发布出来。
接下来,开始配置。
-
将测试集"steel_plate_test_data.csv"拷贝到目录"tools/mqtt/publisher/csv_files"目录下(若目录不存在,则创建)。
-
然后在"tools/mqtt/publisher/Dockerfile"文件中,将"csv_files"目录拷贝到容器中,在"Dockerfile"的第34行添加如下内容:
COPY csv_files /csv_files
- MQTT发布模块的"publisher.py"脚本自带的发送csv文件数据的函数"stream_csv()"不满足我们的需求(它会将csv表格中的每行数据,合成一个字符串来发送,这种方式不方面后续Grafana进行数据的可视化),所以我们重新实现了一个发送csv文件数据的函数"my_stream_csv()"函数。将如下代码,拷贝到文件"tools/mqtt/publisher/publisher.py"中 (例如拷贝到stream_csv()函数的上方,大概在110行的位置)。该函数会将csv文件中的每行数据,封装成json格式进行发送。
def my_stream_csv(mqttc, topic, interval, filename, len):"""Stream the csv file"""target_start_time = time.time()row_count = 0row_served = 0jencoder = json.JSONEncoder()print("\nMQTT Topic: {}\nInterval: {}\nFilename: {}\nLen: {}\n".format(topic, interval, filename, len))wait_time = 5print(f"Waiting {wait_time}s to send data...")time.sleep(wait_time)with open(filename, 'r') as fileobject:# Get headerheader = next(fileobject)header = [x for x in header.split(',') if x not in (' \n', ' \r\n')][:len]for row in fileobject:row = [x for x in row.split(',') if x not in (' \n', ' \r\n')][:len]if re.match(r'^-?\d+', row[0]) is None:continuerow_count += 1row_served += 1values = [float(x) for x in row]msg = {}for i in range(len):msg[header[i]] = values[i]mqttc.publish(topic, json.dumps(msg))time.sleep(interval)print('{} rows served in {}'.format(row_served, time.time() - target_start_time))print('{} Done! {} rows served in {}'.format(filename, row_served, time.time() - target_start_time))
- 然后修改文件"tools/mqtt/publisher/publisher.py"中,main()函数下
if args.csv is not None:后面的语句,引用新实现的my_stream_csv()函数,参考如下:
# 将
stream_csv(client,args.topic,args.subsample,args.sampling_rate,args.csv)
# 修改为
my_stream_csv(client,args.topic,args.interval,args.csv,27)
- 最后,修改"tools/mqtt/publisher/docker-compose.yml"文件末尾的"command"字段,使其发布steel plate测试集中的数据,参考如下:
command: ["--topic", "test/steel_plate_data", "--csv", "./csv_files/steel_plate_test_data.csv", "--interval", "1"]
上述"command"含义如下:MQTT发布模块将会以topic名"test/steel_plate_data"发布数据,发送的是文件"csv_files/steel_plate_test_data.csv"中的数据,发送频率是1秒。
以上我们就完成了MQTT发布模块的配置。在配置过程中,我们对MQTT发布模块的Dockerfile进行的修改,后续需要重新编译该模块的docker镜像文件。
2.2.3 配置Telegraf模块
上一节我们配置了MQTT发布模块,它会以特定的topic发布steel plate测试集中的数据。接下来,我们需要配置Telegraf模块,让它能够接收到该topic的数据。
- 打开文件"Telegraf/config/Telegraf/Telegraf_devmode.conf"文件,添加如下内容:(大概添加在3968行左右的位置,和其他inputs插件写在一起)
[[inputs.mqtt_consumer]]servers = ["tcp://$MQTT_BROKER_HOST:1883"]topics = ["test/steel_plate_data",]name_override = "steel_plate_data"data_format = "json"persistent_session = falseclient_id = ""username = ""password = ""
该配置文件的含义如下:Telegraf模块将会订阅topic名为"test/steel_plate_data"的数据,并重命名为"steel_plate_data",该名字即对应InfluxDB数据库中数据表的名字。
以上我们就完成了Telegraf模块的配置。
InfluxDB模块我们可以使用EII默认配置,不需要做修改,那么接下来进入最重要的Kapacitor模块。
2.2.4 配置Kapacitor模块
当MQTT发布模块发布的数据,经由Telegraf模块接收,并存入InfluxDB数据库后,Kapacitor模块就可以开始从InfluxDB数据库拉取数据,并处理了。接下来,我们进入Kapacitor模块的配置,其中我们会开发一个机器学习的UDF。
-
首先我们将训练集"steel_plate_train_data.csv"拷贝到目录"Kapacitor/training_data_sets"中,该目录是Kapacitor模块用来存放训练数据的地方。
-
接着我们来编写一个UDF(用户自定义功能块),在其中进行模型训练,并用训练好的模型进行推理。Kapacitor模块中的UDF都保存在目录"udfs"中,所以在目录"Kapacitor/udfs"目录下,创建一个新的python脚本"steel_plate_fault_classifier.py",并添加如下内容:
from kapacitor.udf.agent import Agent, Handler
from kapacitor.udf import udf_pb2
from sklearn.ensemble import RandomForestClassifier
import time
import logging
import os
import pandas as pd
from sklearnex import patch_sklearn
patch_sklearn()logging.basicConfig(level=logging.INFO,filemode='w',filename='/EII/sockets/kapacitor.log',format='%(asctime)s %(levelname)s:%(name)s: %(message)s')
logger = logging.getLogger()class RfcHandler(Handler):"""Random Forest Classifier Handler"""def __init__(self, agent):self._agent = agentlogging.info("Training started...")train_data = pd.read_csv('/EII/training_data_sets/steel_plate_train_data.csv')X_train = train_data.iloc[:, :-1]y_train = train_data.iloc[:, -1]self.rfc = RandomForestClassifier(n_estimators=150, max_depth = 10, verbose=False)self.rfc.fit(X_train, y_train)logging.info("training complete...")def info(self):response = udf_pb2.Response()response.info.wants = udf_pb2.STREAMresponse.info.provides = udf_pb2.STREAMreturn responsedef init(self, init_req):response = udf_pb2.Response()response.init.success = Truereturn responsedef begin_batch(self, begin_req):raise Exception("not supported")def point(self, point):"""Store and processing of the point:param point: the body of the point received:type point: udf_pb2.Point"""start_time = time.time()self.response = udf_pb2.Response()logging.info(f"processing, start time: {start_time}")field_name = ['X_Minimum', 'X_Maximum', 'Y_Minimum', 'Y_Maximum', 'Pixels_Areas','X_Perimeter', 'Y_Perimeter', 'Sum_of_Luminosity', 'Minimum_of_Luminosity', 'Maximum_of_Luminosity', 'Length_of_Conveyer', 'TypeOfSteel_A300', 'TypeOfSteel_A400', 'Steel_Plate_Thickness', 'Edges_Index', 'Empty_Index', 'Square_Index', 'Outside_X_Index', 'Edges_X_Index', 'Edges_Y_Index', 'Outside_Global_Index', 'LogOfAreas', 'Log_X_Index', 'Log_Y_Index', 'Orientation_Index', 'Luminosity_Index', 'SigmoidOfAreas']df = pd.DataFrame(columns = field_name)point_msg = []for i in range(len(field_name)):point_msg.append(point.fieldsDouble[field_name[i]])a_msg = pd.Series(point_msg, index = df.columns)df = df.append(a_msg, ignore_index=True)prediction = self.rfc.predict(df)[0]# Simulate result: 0 - good, 1 - badsimulate_result = 0if prediction in ['Z_Scratch', 'K_Scatch']:simulate_result = 1stop_time = time.time()infer_time_ms = stop_time - start_timelogging.info(f"predition: {prediction}, infer time: {infer_time_ms} ms")self.response.point.CopyFrom(point)self.response.point.fieldsString['category'] = predictionself.response.point.fieldsInt['result'] = simulate_resultself.response.point.fieldsDouble['infer_time_ms'] = infer_time_msself._agent.write_response(self.response, True)def end_batch(self, batch_meta):raise Exception("not supported")def snapshot(self):response = udf_pb2.Response()response.snapshot.snapshot = bytes('', 'utf-8')return responsedef restore(self, restore_req):response = udf_pb2.Response()response.restore.success = Falseresponse.restore.error = bytes('not implemented', 'utf-8')return responseif __name__ == '__main__':# Create an agentagent = Agent()# Create a handler and pass it an agent so it can write pointsh = RfcHandler(agent)# Set the handler on the agentagent.handler = h# Anything printed to STDERR from a UDF process gets captured# into the Kapacitor logs.agent.start()agent.wait()
以上python脚本即是实现随机森林算法的UDF,UDF的实现有其固定的模板,官方参考如下:https://docs.influxdata.com/kapacitor/v1.5/guides/anomaly_detection/
算法详情大家可以浏览上面的代码,简要说明如下:
- 在方法
__init__()中,实现了机器学习的训练过程。 - 在方法
info()中,标明了采用流处理的方式。 - 既然是采用流处理的方式,那么用于批处理的两个方式
begin_batch()和end_batch()就可以实现了。 point(self, point)方式是进行数据处理的地方,其中的"point"参数代表的就是数据表中的一笔数据。
值得注意的是,由于UDF中的log不会输出到命令行窗口,所以这里我们进行了配置(python脚本中的11-15行),将log输出到了文件中,方便后续调试程序。
logging.basicConfig(level=logging.INFO,filemode='w',filename='/EII/sockets/kapacitor.log',format='%(asctime)s %(levelname)s:%(name)s: %(message)s')
logger = logging.getLogger()
- 接下来,需要将UDF添加到Kapacitor的配置文件"Kapacitor/kapacitor_devmode.conf"中,打开该文件,在[udf.functions]字段下 (大概在532行附近),将"steel_plate_fault_classifier.py"添加进去,参考如下写法:
# Configuration for UDFs (User Defined Functions)[udf.functions][udf.functions.go_point_classifier]socket = "/tmp/point_classifier"timeout = "20s"[udf.functions.rfc]prog = "python3"args = ["-u", "/EII/udfs/rfc_classifier.py"]timeout = "60s"[udf.functions.rfc.env]PYTHONPATH = "/go/src/github.com/influxdata/kapacitor/udf/agent/py/:/EII/.local/lib/python3.9/site-packages/:/opt/conda/envs/env/lib/python3.9/site-packages/"[udf.functions.steel_plate_fault_classifier]prog = "python3"args = ["-u", "/EII/udfs/steel_plate_fault_classifier.py"]timeout = "60s"[udf.functions.steel_plate_fault_classifier.env]PYTHONPATH = "/go/src/github.com/influxdata/kapacitor/udf/agent/py/:/EII/.local/lib/python3.9/site-packages/:/opt/conda/envs/env/lib/python3.9/site-packages/"
- 然后我们需要编写一个TICKScript来调用该UDF。在"Kapacitor/tick_scripts"目录下,创建一个新的脚本"steel_plate.tick",并添加如下内容:
dbrp "datain"."autogen"var data0 = stream|from().database('datain').retentionPolicy('autogen').measurement('steel_plate_data')@steel_plate_fault_classifier()|influxDBOut().buffer(0).database('datain').measurement('steel_plate_result').retentionPolicy('autogen')
有了编写温度监控案例TICKScript的经验,那么这里就比较好理解了。"steel_plate.tick"脚本实现了从数据库"datain"的数据表"steel_plate_data"中读取数据,然后经过UDF函数"steel_plate_fault_classifier"的处理,最后将处理结果写回数据库"datain"的数据表"steel_plate_result"中。注意这里调用UDF的写法,即是这样:@steel_plate_fault_classifier()
TICKScript中调用的UDF函数名"steel_plate_fault_classifier",即是文件"Kapacitor/kapacitor_devmode.conf"中定义的[udf.functions.steel_plate_fault_classifier]
- 接着,需要在"Kapacitor/config.json"目录中添加"steel_plate.tick"脚本,使得Kapacitor模块在启动时,能将"steel_plate.tick" enable起来。打开"Kapacitor/config.json"文件,在其中添加一个新的task引用"steel_plate.tick"脚本,参考如下:
{"config": {"cert_type": ["zmq", "pem"],"influxdb": {},"task": [{"task_name": "go_point_classifier","tick_script": "go_point_classifier.tick","udfs": [{"type": "go","name": "go_classifier"}]},{"task_name": "temp_filter","tick_script": "temp_filter.tick"},{"task_name": "steel_plate_classifier","tick_script": "steel_plate.tick"}]},"interfaces": {}
}
- 最后,我们将修改过的文件所在的目录都挂载到容器内,这样可以避免后续编译Kapacitor模块docker容器的过程。打开文件"Kapacitor/docker-compose.yml",在其中的volumes字段添加挂载信息,参考如下:
volumes:- "vol_temp_kapacitor:/tmp/"- "vol_eii_socket:${SOCKET_DIR}"- "vol_dev_shm:/dev/shm"- ./Certificates/Kapacitor:/run/secrets/Kapacitor:ro- ./Certificates/rootca/cacert.pem:/run/secrets/rootca/cacert.pem:ro- ../Kapacitor/tick_scripts:/EII/tick_scripts- ../Kapacitor/udfs:/EII/udfs- ../Kapacitor/training_data_sets:/EII/training_data_sets- ../Kapacitor/config:/EII/config
以上我们就完成了Kapacitor模块的配置。
2.2.5 启动案例
所有模块配置完成后,我们来启动EII软件栈。
- 首先,在目录"IEdgeInsights/build/usecases"下,检查模块清单文件"test-mqtt.yml",包含如下模块信息:
AppContexts:
- ConfigMgrAgent
- tools/mqtt/broker
- tools/mqtt/publisher
- Telegraf
- InfluxDBConnector
- Grafana
- Kapacitor
- 然后,编译配置文件。
$ cd IEdgeInsights/build
$ sudo -E python3 builder.py -f usecases/test-mqtt.yml
- MQTT发布模块需要重新编译docker镜像,我们执行如下命令:
$ docker-compose -f docker-compose-build.yml build ia_mqtt_publisher
- 启动EII软件栈。
$ ./eii_start.sh
2.2.6 检查运行结果
- 首先,检查各个模块运行状态,查看容器状态是否健康。
$ docker ps
- 查看MQTT发布模块,数据是否发送成功。执行如下命令,查看MQTT模块的log:
$ docker logs -f ia_mqtt_publisher
若看到如下log信息在滚动,则说明数据发送成功。
MQTT Topic: test/steel_plate_data
Interval: 1.0
Filename: ./csv_files/steel_plate_test_data.csv
Len: 27Waiting 5s to send data...
1 rows served in 6.005375146865845
2 rows served in 7.00670051574707
3 rows served in 8.00806999206543
4 rows served in 9.009141206741333
5 rows served in 10.010363101959229
6 rows served in 11.011662006378174
7 rows served in 12.012709617614746
8 rows served in 13.0132315158844
9 rows served in 14.014494895935059
- 查看Kapacitor模块,是否成功从InfluxDB读取数据,并处理成功。查看Kapacitor模块中UDF输出了log。
$ docker exec -it ia_kapacitor tail -f /EII/sockets/kapacitor.log
若看到如下log信息在滚动,则说明UDF处理成功。
2022-09-24 01:50:58,202 INFO:root: processing, start time: 1663984258.2023537
2022-09-24 01:50:58,214 INFO:root: predition: Other_Faults, infer time: 0.012151002883911133 ms
2022-09-24 01:50:59,203 INFO:root: processing, start time: 1663984259.2034917
2022-09-24 01:50:59,215 INFO:root: predition: Bumps, infer time: 0.011562347412109375 ms
2022-09-24 01:51:00,223 INFO:root: processing, start time: 1663984260.2233331
2022-09-24 01:51:00,241 INFO:root: predition: Other_Faults, infer time: 0.018273353576660156 ms
2022-09-24 01:51:01,206 INFO:root: processing, start time: 1663984261.206068
2022-09-24 01:51:01,218 INFO:root: predition: Other_Faults, infer time: 0.012890100479125977 ms
2022-09-24 01:51:02,207 INFO:root: processing, start time: 1663984262.2077074
2022-09-24 01:51:02,218 INFO:root: predition: K_Scatch, infer time: 0.01125192642211914 ms
2.2.7 可视化展示
最后,我们通过Grafana界面,来进行数据可视化。
-
打开浏览器,输入网址
localhost:3000进入Grafana界面。 -
笔者制作了一个仪表盘(Dashboard),保存成json文件,大家可以下载下来,直接导入到Grafana中。
Steel Plate Grafana Dashboard下载链接:https://pan.quark.cn/s/2520bed09d1f
-
Grafana界面的操作就又是一个大话题了,笔者这里就不详细介绍导入方法了,大家可以先自行探索一下。笔者会另写文章介绍Grafana的使用。
-
Dashboard导入成功后,大家将会看到如下界面,且数据会不断刷新。
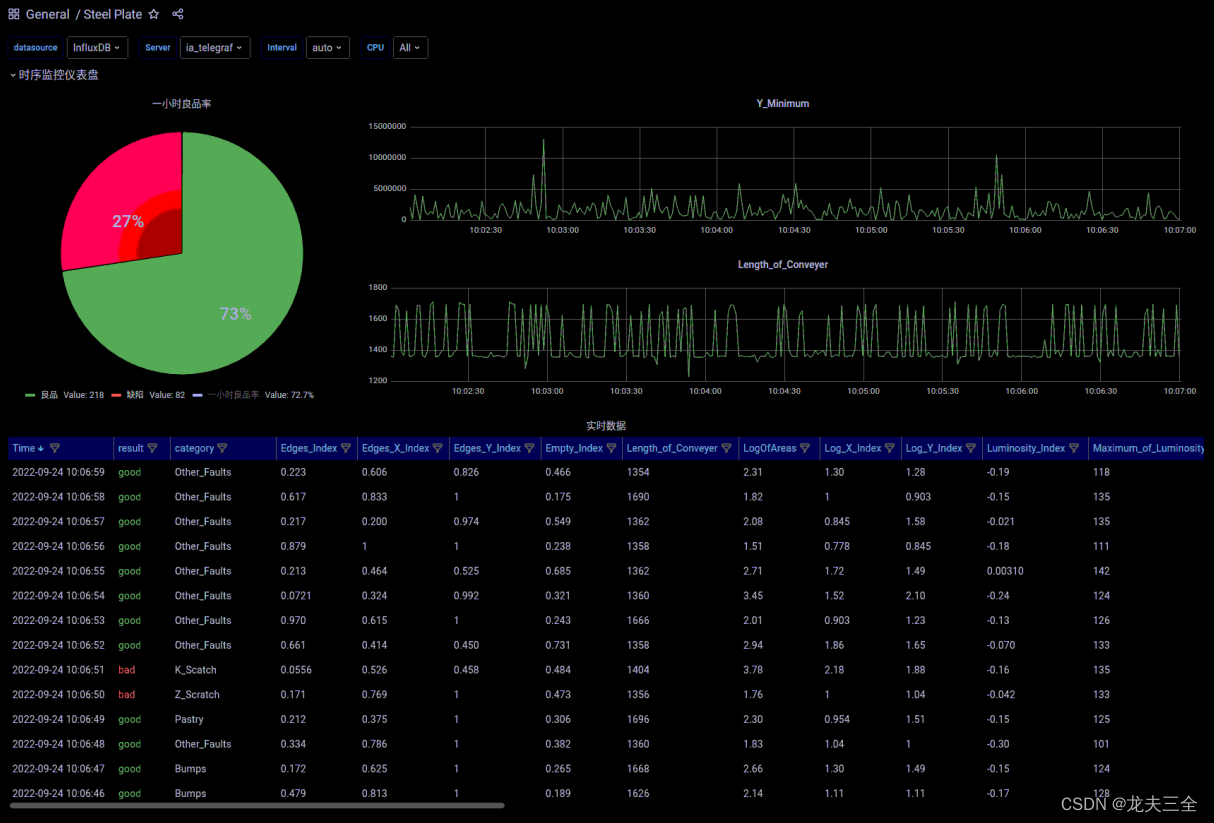
-
关闭EII软件栈的命令。
$ docker-compose down
后记
经过EII系列(1)-(5)篇的内容,基本上把EII时序栈相关的介绍完了,大家实操过程中如果遇到问题,欢迎留言交流。
这篇关于(5)EII Kapacitor模块详解(附机器学习案例实操)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




