本文主要是介绍323篇论文惨遭撤稿,中国学者「全军覆没」?ACM:会议是假的,我上当了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【导读】一个学术会议的300多篇论文,被ACM一次性全部撤稿,大部分作者为中国学者,其中不乏大量知名高校。这是怎么回事?
一夜之间,一个学术会议上的全部300多篇会议论文,全部被ACM撤稿,这是个什么操作?
据著名学术诚信网站「撤稿观察」报道,ACM宣布,撤回此前由ACM数字化图书馆收录的2021信息管理与技术会议(ICIMTech)上发表的全部323篇会议论文。
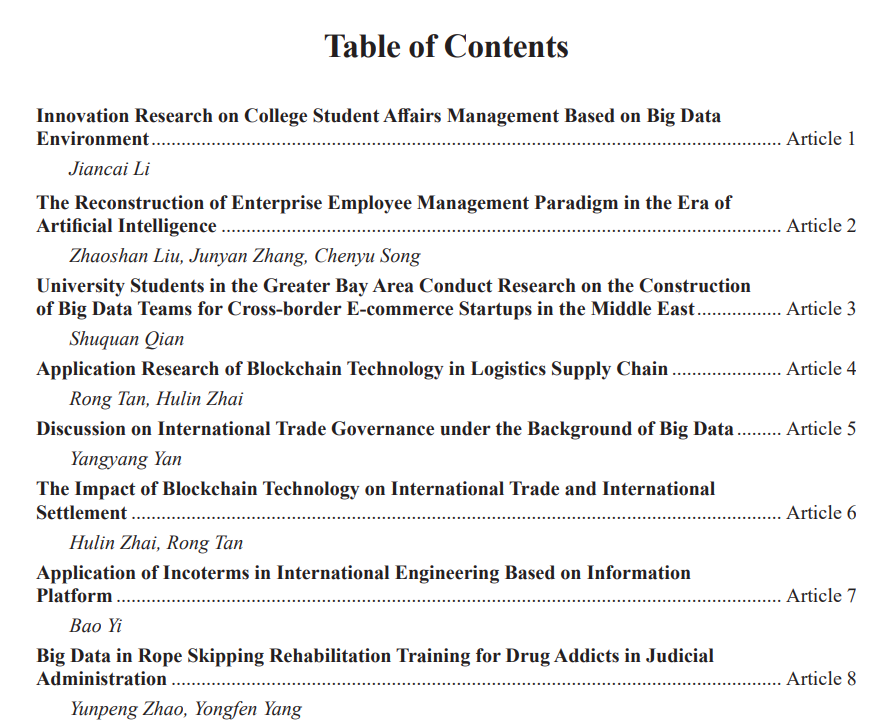
从论文列表中看,此论文集中几乎都是中国作者,且不乏来自知名高校和研究机构的名字。
难道是这些学者或所在机构集中爆发了学术不端问题?先别忙着下结论。
面对「套皮冒牌会议」,ACM上当了

据IEEE官网显示,该机构旗下的信息管理与技术会议(ICIMTech)在2021年8月19-20日在印度尼西亚雅加达举行。按照流程,会后形成会议论文集,由IEEE发布出版。
作为IEEE举办的学术会议,会议论文集被ACM收录也是很正常的事情。
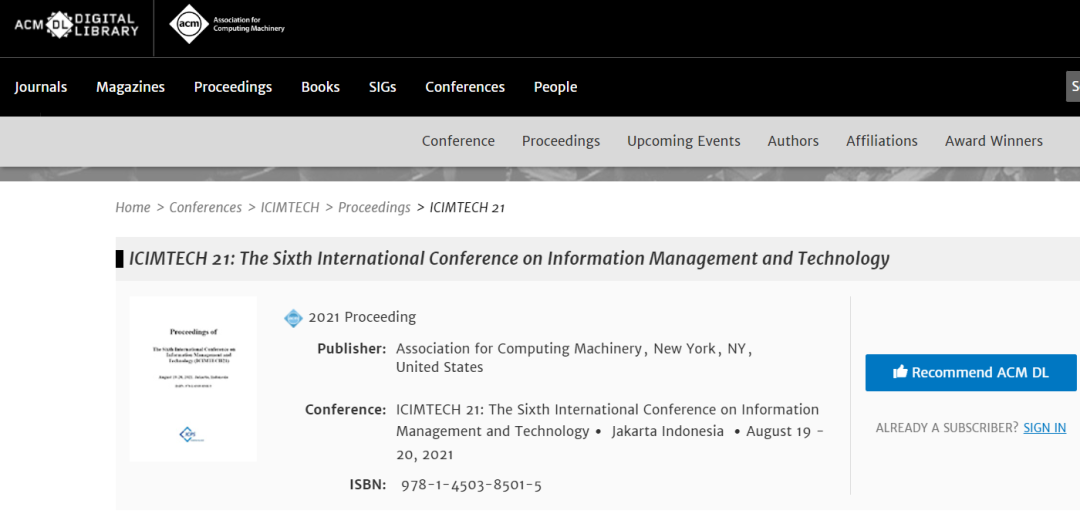
据报道,ACM数字化图书馆收录的论文集,显示的是相同的日期、相同的地点举办的同名会议,作者也大部分相同。
问题就出在被ACM收录的这个「会议」上,这是个套皮的冒牌货,可能根本就不存在。

如果再看看这个「会议」论文集中300多篇论文的题目,就会发现更是离了大谱,有农业、旅游、贸易、教育,可以说是五花八门。
比如《吉林大米出口对外贸的影响》、《职业技校焊接专业项目教学法的改革》《论网络安全背景下的专业英语长句教学》、《用虚拟技术教学生怎么当上CFO》等等。
冒牌会议论文列表在此:
https://dl.acm.org/action/showFmPdf?doi=10.1145%2F3465631
ACM宣称,对此事件调查后,认为「该会议论文的同行评议过程的诚信度,以及整个会议的诚信度都值得怀疑」,据此做出整体撤稿的决定。
同时指出,此论文集中的任何一篇论文都不应再被引用。

ACM:只负责收录,同行评议是外包的
不过,据「撤稿观察」报道,这种「李逵遇见李鬼」的事情,ACM也不是第一次碰到了。在之前的一次类似调查中,也出现了论文被集体大规模撤回的事件。
那次涉及到的会议是2018年的信息隐藏和信息处理(IHIP)会议,当时ACM收到匿名指控,说其中一篇论文是由计算机自动生成的。
ACM出版总监Scott Delman表示,ACM在调查过程中去找了会议的组织者,问同行评议为什么没查出这个问题来,但对方称,只负责确保会场和举办讲座,同行评议则外包给了北京的一家公司。
ACM又找到北京这家公司,一位工作人员称「论文已被同行评审过」。
在多次请求后,ACM收到一份所谓证明同行评审的PDF文件,根据对文件中的元数据的分析显示,文件似乎是被伪造的。
最终,经过「长达数月」的调查,在会议上发表的26篇论文的作者都没有作出回应,ACM得出的结论是,「无法确信这次活动的同行评审过程的完整性,不得不撤回会议上发表的全部论文」。
Delman表示,这两次乌龙事件涉及的会议并不是ACM举办的,ACM仅作为出版商,出版会议论文集。
「他们应该遵守我们的政策和标准,但我们不会为其进行同行评议。」

据ACM官网介绍,目前已通过国际会议论文集计划(ICPS),在ACM 数字图书馆(DL)中发表了来自1350多个会议中的45000篇研究论文。
ACM数字化图书馆平均每月有来自195个国家/地区的超过400万独立用户,平均每月产生175万次下载量。
在如此巨大的下载量和数量众多的会议面前,「似乎让有些人找到了可以利用的漏洞。」Delman说。
他表示,目前ACM已将此类调查作为优先事项,甚至请了一家第三方公司帮忙一起做。
此外,ACM还征求了一些学者的建议,在寻找论文中的「别扭用语」及「计算机生成论文」方面发挥关键作用。 一些学者也建议,加强对同行评议环节的审查。
网友:怕不是故意收钱出版的吧
不过,面对ACM有些「甩锅」的回应,一些网友并不买账。

有网友表示,「为什么ACM连是不是经过同行评议都没确认,就发表了论文集?还是说这个会议其实真的存在,只是要收钱才给发表的那种。」
还有网友对ACM接到「匿名举报」后展开调查这一说法表示怀疑,因为匿名举报本身不符合ACM关于举报学术不端行为的相关规范。

因为根据ACM自己的规定,「任何个人提交正式的举报声明都要确认自己的身份,ACM不接受匿名举报」。ACM说接到「匿名举报」再调查,是不是前后矛盾?
不知道对这次「乌龙事件」,各位怎么看?
这篇关于323篇论文惨遭撤稿,中国学者「全军覆没」?ACM:会议是假的,我上当了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









