本文主要是介绍软件测试十年老鸟——分享学习实战经验,看完直呼窝靠,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
作为软件开发过程中一个非常重要的环节,软件测试越来越成为软件开发商和用户关注的焦点。完善的测试是软件质量的保证,因此软件测试就成了一项重要而艰巨的工作。要做好这项工作当然也绝非易事。
下面我着重谈谈自己在做软件测试工作中总结出来的一些经验和技巧,以供大家参考。

一、工作需求背景
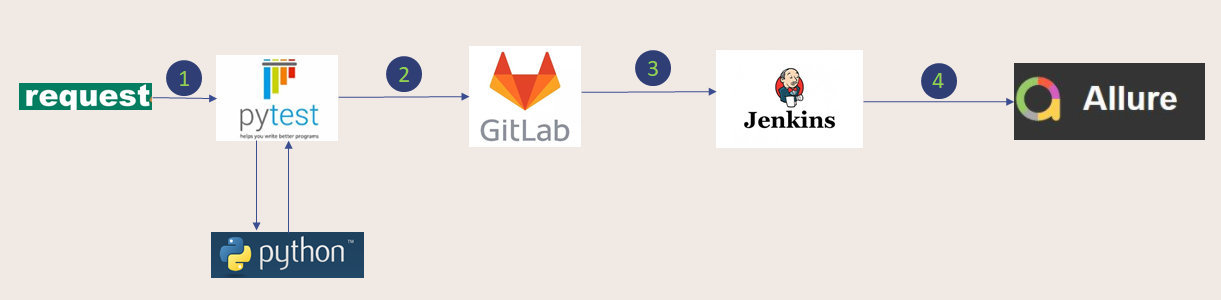
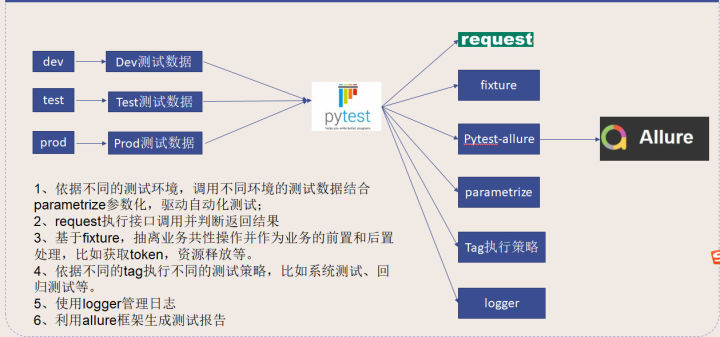
- 利用Pytest+Request+Allure+Jenkins实现接口自动化;
- 实现一套脚本多套环境执行;
- 利用参数化数据驱动模式,实现接口与测试数据分离
- 使用logger定制实现自动化测试日志记录
二、接口自动化项目代码编写(先在window实现)
1 、项目准备
先在window安装响应的环境依赖
- 安装python3.7(要保证pip能用,一般安装python3.7会自动安装pip)
- 安装pytest框架---- pip install pytest
- 安装request库---- pip install request
- 安装openpyxl库(测试数据保存在excel中,需要依赖读取excel的库)---- pip install openpyxl
- 安装pycharm(编写python脚本工具)
注意:可能还需要一些依赖的东西,项目步骤里会依据需要进行安装
2、 设计基于pytest的测试框架结构
在pycharm中开发构建项目结构
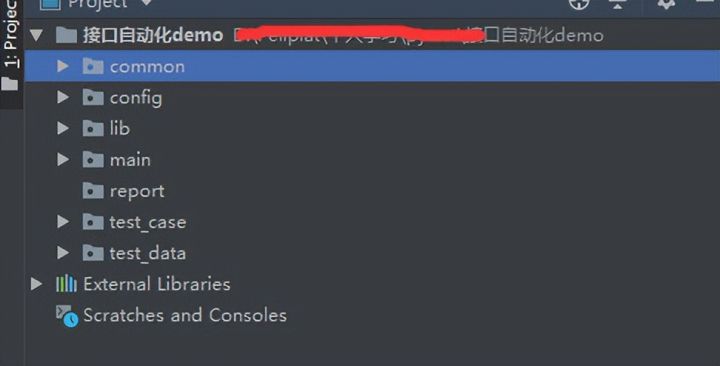
- common:存放公共方法
- config:存放环境配置信息
- lib:存放第三方库
- main:框架主入口
- report:存放allure测试报告
- test_case:存放测试用例
- test_data:存放测试数据

3、实现接口公共请求发送能力
从这一步开始正式编写代码

封装http请求的公共能力(封装request库,变成自己的公共处理能力),放到common目录下。
import requests
import urllib3
# from urllib3.exceptions import InsecureRequestWarningurllib3.disable_warnings()
# 加这句不会报错(requests证书警告)
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)class HTTPRequests(object):def __init__(self, url):self.url = urlself.req = requests.session()# 依据自己公司的请求头默认值配置self.head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko','Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, ''application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, ''application/msword, */*','Accept-Language': 'zh-CN'}# 封装自己的get请求,获取资源def get(self, uri='', params='', data='', headers=None, cookies=None, verify=False):if headers is None:headers = self.head# print("请求头是:{}".format(headers))url = self.url + uriresponse = self.req.get(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)return response# 封装自己的post请求,获取资源def post(self, uri='', params='', data='', headers=None, cookies=None, verify=False):if headers is None:headers = self.headurl = self.url + uriresponse = self.req.post(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)return response# 封装自己的put请求,获取资源def put(self, uri='', params='', data='', headers=None, cookies=None, verify=False):if headers is None:headers = self.headurl = self.url + uriresponse = self.req.put(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)return response# 封装自己的delete请求,获取资源def delete(self, uri='', params='', data='', headers=None, cookies=None, verify=False):if headers is None:headers = self.headurl = self.url + uriresponse = self.req.delete(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)return response4、 抽离测试环境配置信息
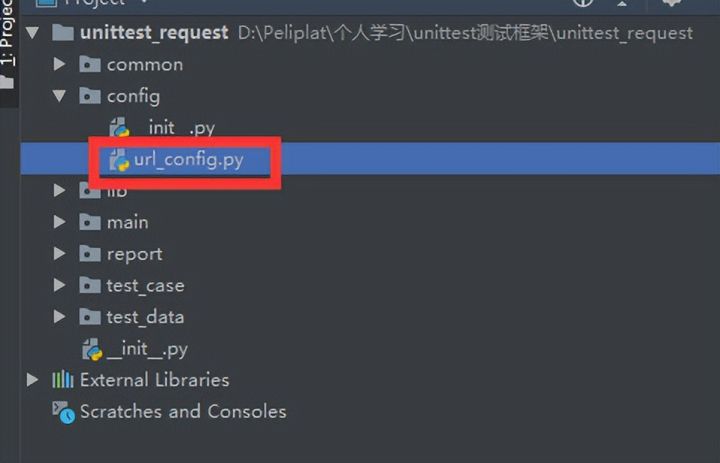
这个步骤的目的有三个
- 为了配置三个不同环境(测试、开发、生产)的URL,每个环境接口测试的URL是不一样的,设置这样一个枚举类,方便后面的程序根据不同的环境,获取不同环境的URL,里面的URL依据自己公司的地址修改,放到config目录
- 获取token需要登录,这里可以设置一个全局的账号密码,这个账号密码获取的token可以给整个接口自动化使用
- 配置获取token的uri,这个uri三个环境的是一致的,登录的接口依据环境只是URL不同,URI还是一致的。
import enumclass URLConf(enum.Enum):"""环境配置信息"""url_mapping = {'dev': 'https://www.dev.com','test': 'https://www.test.com','prod': 'https://www.prod.com'}# token固定的用户名密码,固定用"/"分割用户名和密码email_user = {'dev': 'dev@qq.com','test': 'zidonghua@qq.com/96e79218965eb72c92a549dd5a330112','prod': 'prod@qq.com'}login_uri = r'/api/auth/login/account/v1'
5 、创建conftest.py放置一些公共的fixture
1、pytest_addoption,设置了只允许输入dev/test/prod三个参数,以区分测试、开发、生产三个环境
2、get_env的fixture,它的作用是你在命令行执行接口自动化时,可以输入--env test将对应的环境信息传入进去
3、http的fixture,这里依据--env test传入的环境信息,去枚举类里获取对应环境的URL,然后返回一个http的session,供测试案例使用
4、get_token_head,依据--env test传入的环境信息,调用获取token方法,并将token放置到请求头head里返回(token一般放在请求头里,这里依据自己公司的请求,返回对应的token信息就可以了)
import logging
import osimport pytestfrom common.http_request import HTTPRequests
from config.url_config import URLConfdatadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
logger = logging.getLogger('conftest日志')def pytest_addoption(parser):# choices 只允许输入的值的范围parser.addoption("--env", action="store", default='test', choices=['dev', 'test', 'prod'], help="set env")# 获取命令行参数的fixture
@pytest.fixture(scope='session')
def get_env(request):# print("fixutre..................")return request.config.getoption('--env')# 声明一个返回http请求对象的fixture,所有用例在一个session中
# @pytest.fixture(scope='module', autouse=True)
@pytest.fixture(autouse=True)
def http(request):env = request.getfixturevalue("get_env")url_mapping = URLConf.url_mapping.valueurl = url_mapping.get(f'{env}')http = HTTPRequests(url)return http@pytest.fixture(scope='session')
def get_token_head(request):env = request.getfixturevalue("get_env")url_mapping = URLConf.url_mapping.valueurl = url_mapping.get(f'{env}')http = HTTPRequests(url)user = URLConf.email_user.valueuser_list = user.get(f'{env}').split("/")username = user_list[0]password = user_list[1]param = {'clientType': 2,'language': 'en','loginId': username,'loginPassword': password}logger.info("请求的url=={}".format(url))response = http.post(uri=r'/api/auth/login/account/v1', data=param)logger.info("获取的返回值是:".format(response.text))token = Noneif response.status_code == 200:token = response.json().get('result')['token']else:token = 'get token fail'head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko','Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, ''application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, ''application/msword, */*','Accept-Language': 'zh-CN','Authorization': token}yield head6、 将测试数据放到excel中
我们的测试数据是放在excel中,注意,这里有prod\test\dev三个目录,对应三个环境的测试数据,我这里只创建了test测试环境的测试数据。这里的测试数据需要包含两部分:
- 你调用接口传入的所有参数;
- 你要断言的所有信息,因为你传的参数不同,返回的内容就不同,你断言的内容也就不相同了。

那么这时候,就需要一个读取excel的公共方法了,放到common里
# 创建解析excel的方法
import loggingfrom openpyxl import load_workbooklogger = logging.getLogger("读取excel")class ParseExcel(object):def __init__(self, excelPath, sheetName):self.wb = load_workbook(excelPath)self.sheet = self.wb[sheetName]self.maxRowNum = self.sheet.max_row# 依据传入的数字,决定获取几列excel数据def getDataFromSheet(self, num):dataList = []for line in self.sheet.rows:tmplist = []for i in range(num):tmplist.append(line[i].value)dataList.append(tmplist)print("dadddddd:{}".format(dataList))return dataList[2:]这里,还需要在test_data中,创建一个文件,为了获取前面test_data依据环境创建的dev/test或prod文件目录
注意:这里只有一个test或prod或dev的文字,是为了拼接....test_data/test目录获取对应环境的excel测试数据而使用的,每次环境切换前,需要更改这个文件,可能这并不是一个好方法,如果大家有找到更好的方法,也可以分享一下
7、开始编写自动化测试案例了
测试案例中有几个点,需要解释一下:
1、authBaseDir,这个就是根据test_data/test拼接出来的获取测试数据的目录
2、allure.feature,在测试报告中,会展现这个接口名称,这个名称最好与你公司的开发写的接口模块保持一致,方便后续查找问题
3、allure.story 这里也要与开发写的具体某个接口的名称保持一致。
4、pytest.mark.parametrize,这里就是运用的DDT数据驱动的模式,从excel中一条一条的获取数据,然后执行同一条接口测试用例,excel中比如有3条数据,那么就表示这个案例依据每一条数据的参数,总共执行了三次
# encoding: utf-8"""
create by ArthurAccount Api模块
"""
import logging
import osimport allure
import pytestfrom common.get_data_url import get_data_url
from common.parse_excel import ParseExceldatadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
data_url = get_data_url()
# 获取到test_data\test的目录,如果是prod环境,那么就是获取test_data\prod目录
authBaseDir = os.path.join(datadir, data_url)logger = logging.getLogger("Account Api模块日志")@allure.feature("AccountApi模块")
@pytest.mark.webtest
class TestAccountApi(object):"""Query Related Achievements: /api/auth/account/achievement/related/query/v1"""Query_Related_Achievements_dir = os.path.join(authBaseDir, 'Query_Related_Achievements.xlsx')logger.info("Query_Related_Achievements测试数据的路径是:{}".format(Query_Related_Achievements_dir))parse = ParseExcel(Query_Related_Achievements_dir, 'Sheet1')Query_Related_Achievements_params = parse.getDataFromSheet(5)@allure.story("Query Related Achievements(查询用户成就信息)")@pytest.mark.parametrize("clientType,language,retCode,istoken,result", Query_Related_Achievements_params)def test_001_Query_Related_Achievements(self, get_token_head, http, clientType, language, retCode, istoken, result):uri = '/api/auth/account/achievement/related/query/v1'params = {"clientType": clientType, "language": language}if istoken == 'yes':header = get_token_headresponse = http.get(uri=uri, params=params, headers=header)json_req = response.json()logger.info("Query_Related_Achievements有token的返回值是:{}".format(json_req))assert json_req.get('retCode') == 200assert json_req.get('result')[0]['smallImg'] == resultelse:response = http.get(uri=uri, params=params)json_req = response.json()logger.info("Query_Related_Achievements没有token的返回值是:{}".format(json_req))assert json_req.get('retCode') == 401assert json_req.get('message') == result

8 、集成allure
写到这里,是不是发现前面的allure.feature是不是用不了呢?这是因为我们还没有集成allure进去。
1、下载allure,放到lib目录下,使你的工程具备allure的能力。
2、pip install allure-pytest 安装pytest对应的allure包
9、 这时候就可以创建一些执行策略了
1、先在main中创建一个pytest.ini文件,设置一些执行参数

2、在main中创建执行策略
- 先在run_pytest方法中,执行案例并生成allure的json格式的报告文件,这里可以带--env prod将对应环境信息传入,这里没有传是因为默认是test环境,不传入的话就是执行的test环境测试数据
- general_report方法时将生成的json格式的报告,最终生成html文件放置到report下面的目录中
- 创建一个线程,先执行run_pytest,再执行general_report,避免json文件没有生成,这样生成html文件的报告数据可能不全,甚至没有。
"""
所有案例执行并生成allure测试报告的执行策略
"""import os
import sys
import threading
import pytestsys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../')
from common.report import Reportproject_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
report_dir = os.path.join(project_root, 'report')
# 存放测试结果的目录,会生成一推json文件
result_dir = os.path.join(report_dir, 'allure_result')
allure_report = os.path.join(report_dir, 'allure_report')report = Report()# 定义搜索条件,搜索所有以test开头的用例
tag = 'test'def run_pytest():# --clean-alluredir# pytest.main(['-vv', '-s', '-m', 'webtest', f'--alluredir={result_dir}', '--clean-alluredir'])# 执行前清除allure_result数据,避免生成报告时,会把上次执行的数据带进去pytest.main(['-vv', '-s', '-k', f'{tag}', f'--alluredir={result_dir}', '--clean-alluredir'])def general_report():# 调用cmd方法 report.allure,根据windows或linux环境判断# 然后执行生成报告的方法generate# --clean 覆盖路径,将上次的结果覆盖掉cmd = "{} generate {} -o {} --clean".format(report.allure, result_dir, allure_report)# 执行命令行命令,并通过read()方法将命令的结果返回print(os.popen(cmd).read())if __name__ == '__main__':# 创建两个线程,分别执行两个方法run = threading.Thread(target=run_pytest)gen = threading.Thread(target=general_report)run.start()# 先执行第一个线程,这个线程执行完才会执行下面的线程和主线程run.join()gen.start()gen.join()10、 自动化执行生成结果
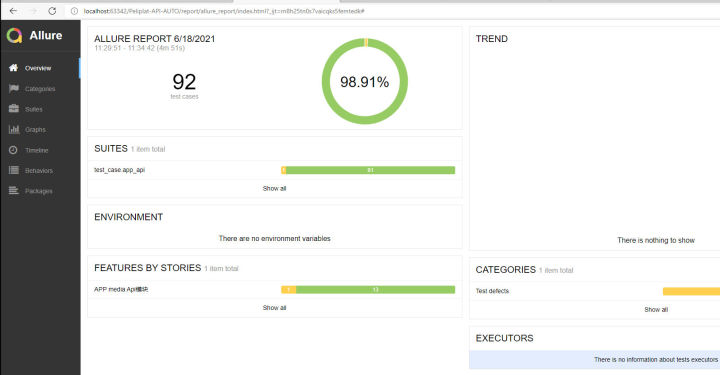
在windows下,右键执行main下面的run_test_allure_html.py(就是上一个步骤的python文件),然后打开report/allure_report/index.html看看报告是否生成成功
福利:
软件测试工程师学习资源包
结语
这篇贴子到这里就结束了,最后,希望看这篇帖子的朋友能够有所收获。如果想以测试为长期发展职业目标,是需要时刻保持学习的,要使自己具备竞争力,无论你现在工作几年,只要行动起来,你就已经占优势了。祝大家2022年能升职加薪,没入职的就早日拿到心仪公司的offer,事事顺遂。
衷心感谢每一个认真阅读我文章的人
欢迎留言,或是关注我的专栏和我交流。
这篇关于软件测试十年老鸟——分享学习实战经验,看完直呼窝靠的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




