本文主要是介绍沉浸式面试:MySQL连环炮,你能抗到第几个?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来聊聊MySQL原理
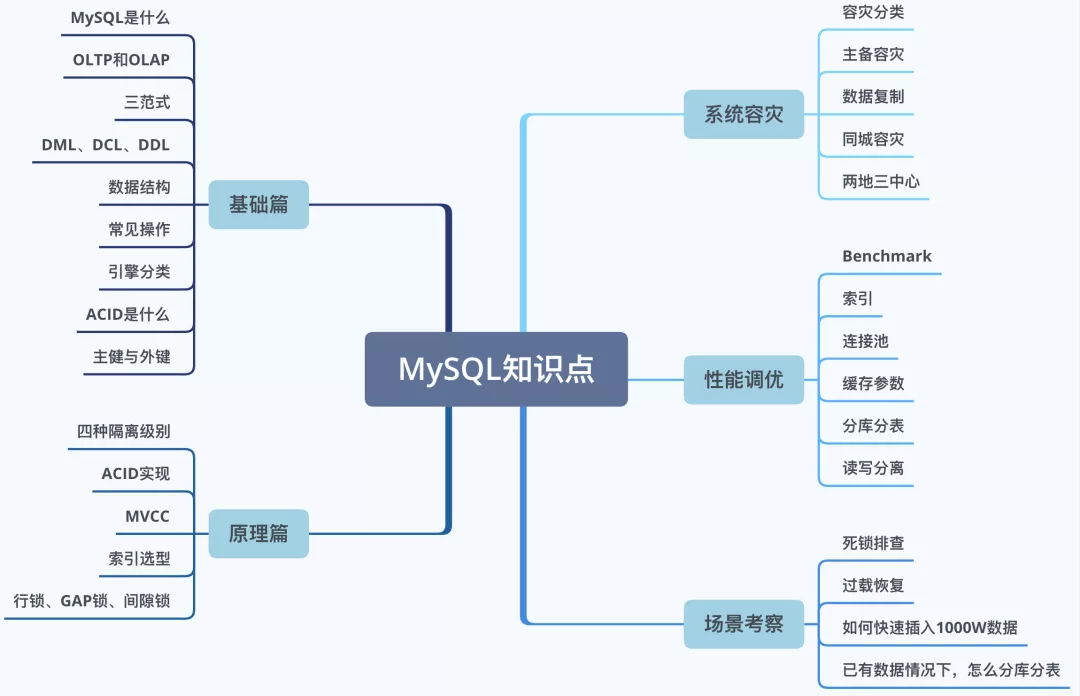
基础篇主要是侧重基础知识,原理篇是有一定基础后的递进,通过学习本篇,不仅可以进一步了解MySQL的各项特性,还能为接下来的容灾调优打下坚实的基础。
现在,就让我们继续跟随阿柴进行这场沉浸式面试吧。
ACID与隔离级别
那你先来说说MySQL的四种隔离级别吧。
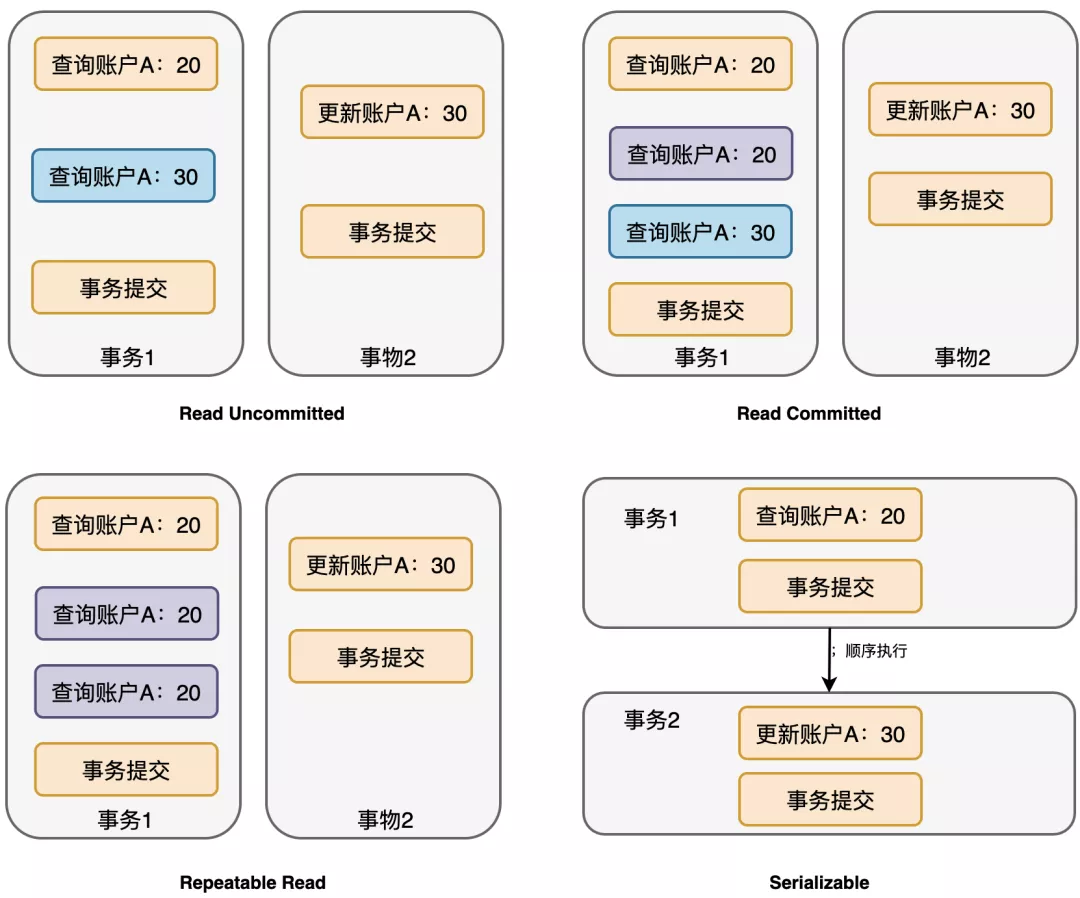
SQL标准定义了4类隔离级别,包括一些具体规则,用来限定事务之间的隔离性。
这四种级别分别是读未提交、读已提交、可重复读、串型化。
读未提交,顾名思义,就是可以读到还没有提交的数据;读已提交会读到其它事务已经提交的数据;可重复读确保了同一事务中,读取同一条数据时,会看到同样的数据行;串型化通过强制事务排序,使其不可能相互冲突。
重点介绍下Repeatable Read吧。
Repeatable Read就是可重复读。它确保了在同一事务中,读取同一条数据时,会看到同样的数据行。
它也是MyQL的默认事务隔离级别,这种级别事务之间影响很小,通常已经能够满足日常需要了。
说出四种隔离级别只是最低要求,能每一项具体去阐述特性就算过关。如果还能指出存在的问题、依赖的技术,那么就是妥妥的加分了!
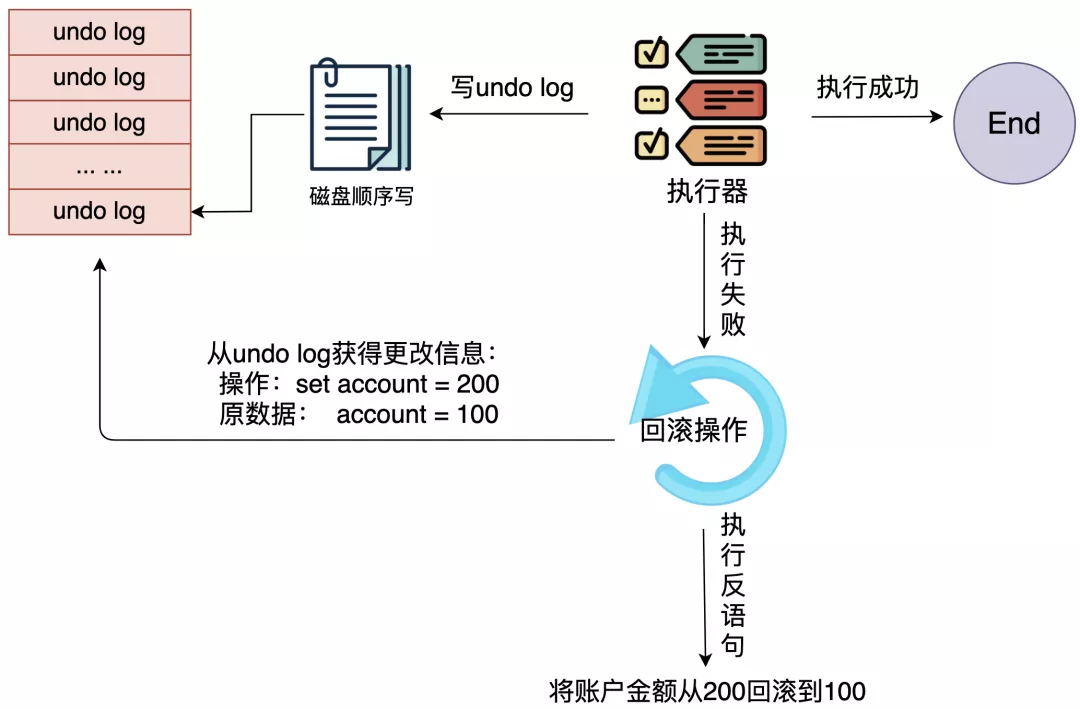
下面我们来聊聊InnoDB中ACID的实现吧,先说一下原子性是怎么实现的。
事务要么失败,要么成功,不能做一半。聪明的InnoDB,在干活儿之前,先将要做的事情记录到一个叫undo log的日志文件中,如果失败了或者主动rollback,就可以通过undo log的内容,将事务回滚。
那undo log里面具体记录了什么信息呢?
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作,使数据回到之前的状态。。。
那持久性又是怎么实现的?
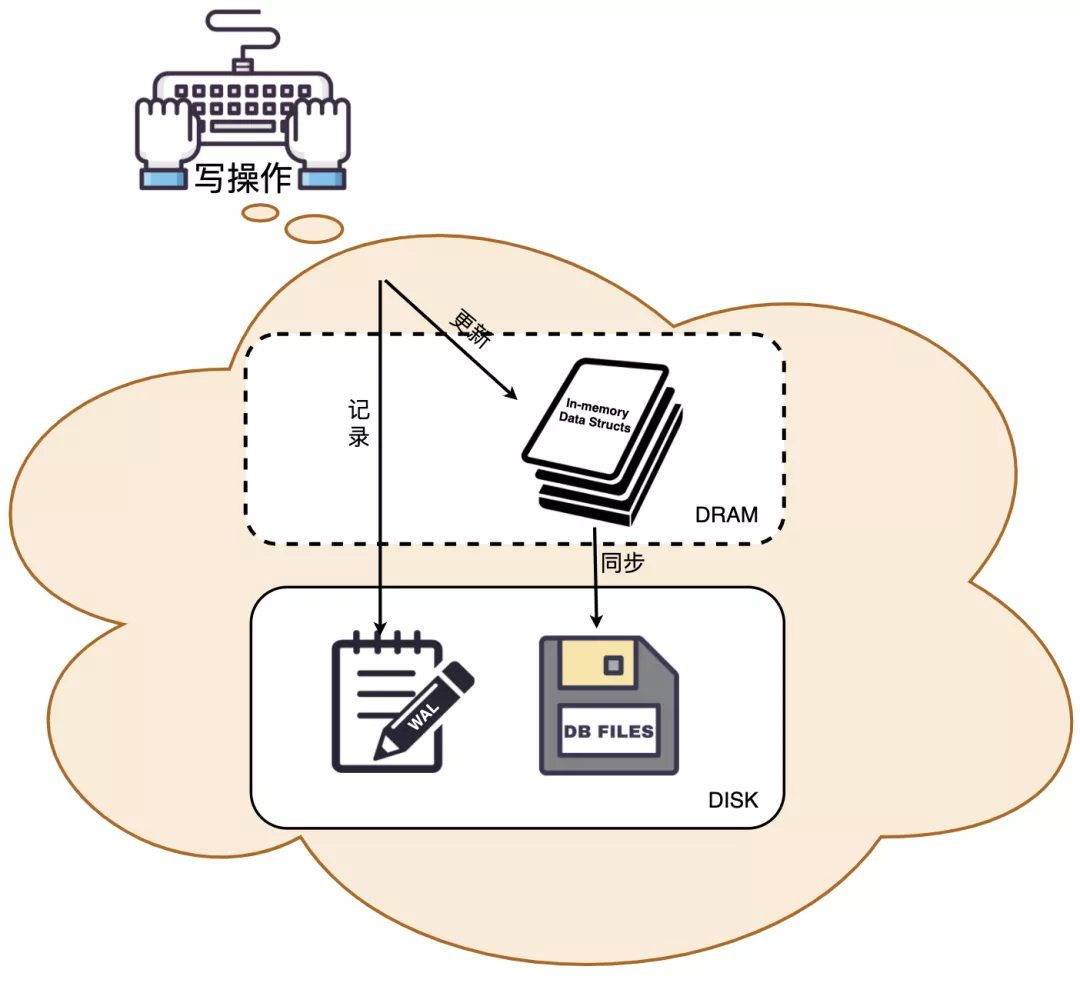
持久性是用来保证一旦给客户返回成功,数据就不会消失,持久存在。最简单的做法,是每次写完磁盘落地之后,再给客户返回成功。但如果每次读写数据都需要磁盘IO,效率就会很低。
为此,追求极致的InnoDB提供了缓冲。当向数据库写入数据时,会首先写入缓冲池,缓冲池中修改的数据会定期刷新到磁盘中,这一过程称为刷脏。
如果MySQL宕机,那此时Buffer Pool中修改的数据不是丢失了吗?
Innodb引入了redo log来解决这个问题。当数据修改时,会先在redo log记录这次操作,然后再修改缓冲池中的数据,当事务提交时,会调用fsync接口对redo log进行刷盘。
如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。由于redo log是WAL日志,也就是预写式日志,所有修改先写入日志,所以保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。

按你所说,redo log 也需要写磁盘,为什么不直接将数据写磁盘呢?
嗯。。。主要是有以下两方面的原因:
1.对Buffer Pool进行刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO;
2.刷脏是以数据页为单位,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入,所以积累一些数据一并写入会大大提升性能;而redo log中只包含真正需要写入的部分,无效IO比较少。
redo log是持久性的核心,WAL的思路也是持久化的常见解决方式,只有先落地了,才能应对后续的各种异常。
那隔离性怎么实现呢?
MySQL能支持Repeatable Read这种高隔离级别,主要是锁和MVCC一起努力的结果。
我先说锁吧。事务在读取某数据的瞬间,必须先对其加行级共享锁,直到事务结束才释放;事务在更新某数据的瞬间,必须先对其加行级排他锁,直到事务结束才释放;
为了防止幻读,还会有间隙锁进行区间排它锁定。
然后是MVCC,多版本并发控制,主要是为了实现可重复读,虽然锁也可以,但是为了更高性能考虑,使用了这种多版本快照的方式。
因为是快照,所以一个事务针对同一条Sql查询语句的结果,不会受其它事务影响。
索引原理
索引的底层实现是什么?
用的B+树,它是一个N叉排序树,每个节点通常有多个子节点。节点种类有普通节点和叶子节点。根节点可能是一个叶子节点, 也可能是个普通节点。
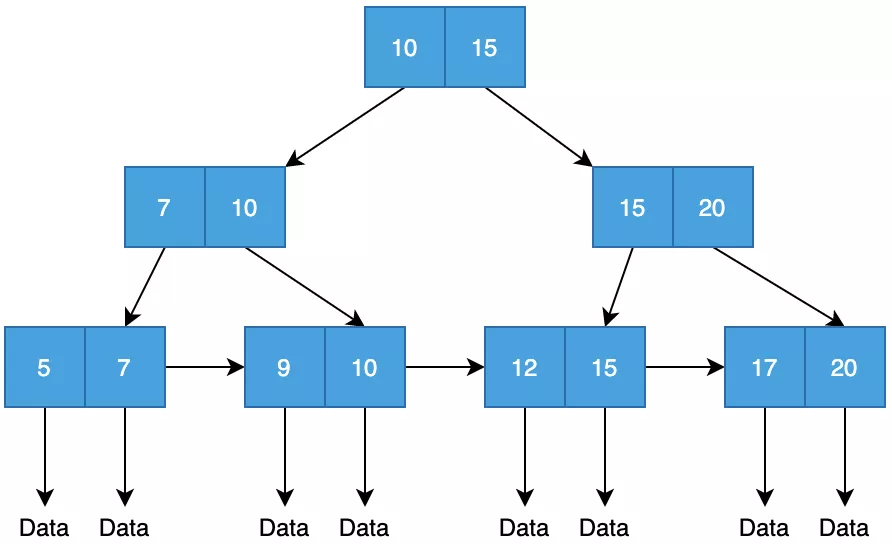
那MySQL为什么用树做索引?
一般而言,能做索引的,要么Hash,要么树,要么就是比较特殊的跳表。Hash不支持范围查询,跳表不适合这种磁盘场景,而树支持范围查询,且多种多样,很多树适合磁盘存储。所以MySQL选择了树来做索引。
那你能说说为什么是B+树,而不是平衡二叉树、红黑树或者B-树吗?
平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
同时,B+树优势在于每个节点能存储多个信息,这样深度比平衡二叉树会浅很多,减少数据查找的次数。
平衡二叉树
红黑树放弃了追求完全平衡,只追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
但是红黑树多用于内部排序,即全放在内存中,而B+树多用于外存上时,B+也被称为一个磁盘友好的数据结构。
同时,红黑树和平衡二叉树有相同缺点,即每个节点存储一个关键词,数据量大时,导致它们的深度很深,MySQL每次读取时都会消耗大量IO。
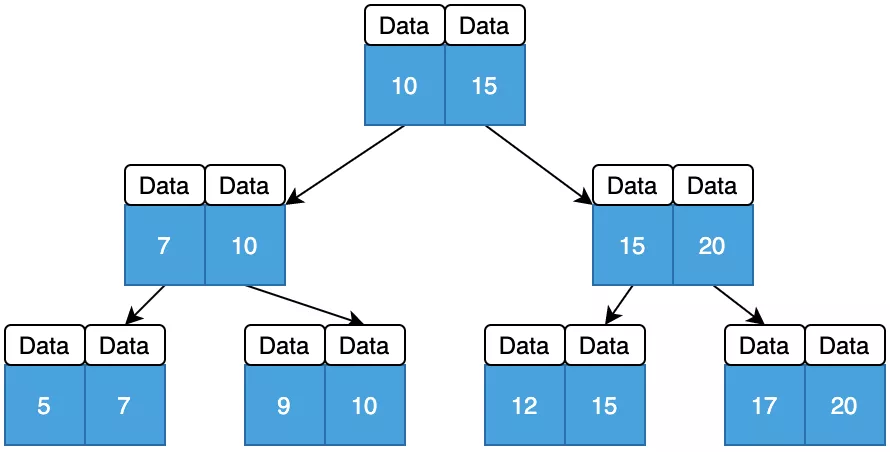
那B+树相比B-树有什么优点呢?
哈哈,我觉得这就属于同门师兄较劲儿了。B+树非叶子节点只存储key值,而B-树存储key值和data值,这样B+树的层级更少,查询效率更高;
MySQL进行区间访问时,由于B+树叶子节点之间用指针相连,只需要遍历所有的叶子节点即可,而B-树则需要中序遍历一遍。
这类选型问题其实很深,要深刻理解为什么要用B+树、B+树有哪些竞争对手。换句话说,也就是要了解,哪些数据结构能做索引。如果能答出哈希表、树、跳表这三大类,就说明确实有自己的深入思考,这部分知识点学透了,也是加分项。
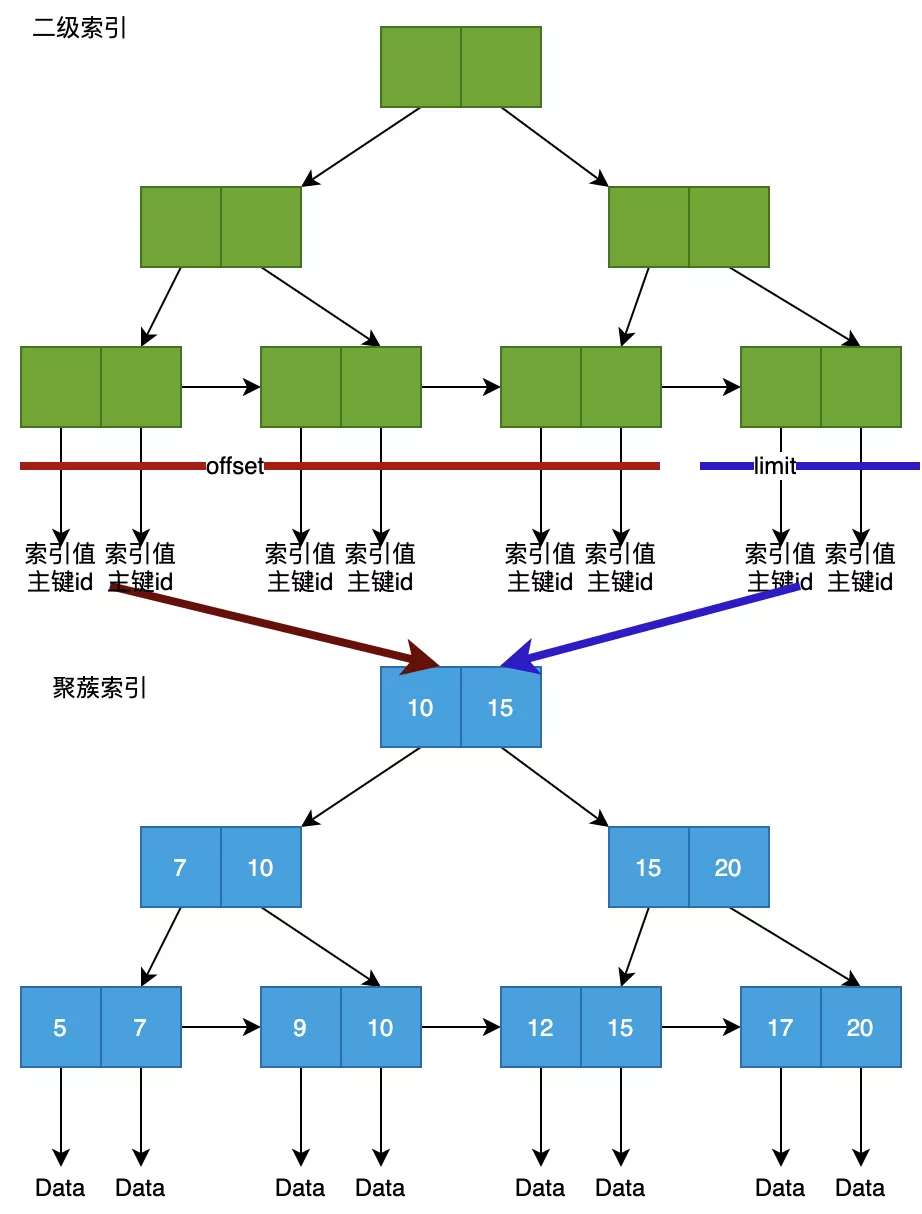
接下来讲讲聚簇索引和二级索引吧。
聚簇索引是主键上的索引,二级索引是非主键字段的索引。这两者相同点是都是基于B+树实现。
区别在于,二级索引的叶子结点只存储索引本身内容,以及主键ID,聚簇索引的叶子结点,会存储完整的行数据。在一定程度上,可以说二级索引就是主键索引的索引。
一般来说,面试官让介绍两个名词或者概念,潜台词就是要我们说清楚两者的相同点、不同点,说清楚了就过关。如果有些自己的总结性思考,比如在上面的对话中,阿柴回答出二级索引是主键索引的索引,这样就会让面试官眼前一亮。
下面讲讲MySQL锁的分类吧。
MySQL从锁粒度粒度上讲,有表级锁、行级锁。从强度上讲,又分为意向共享锁、共享锁、意向排它锁和排它锁。
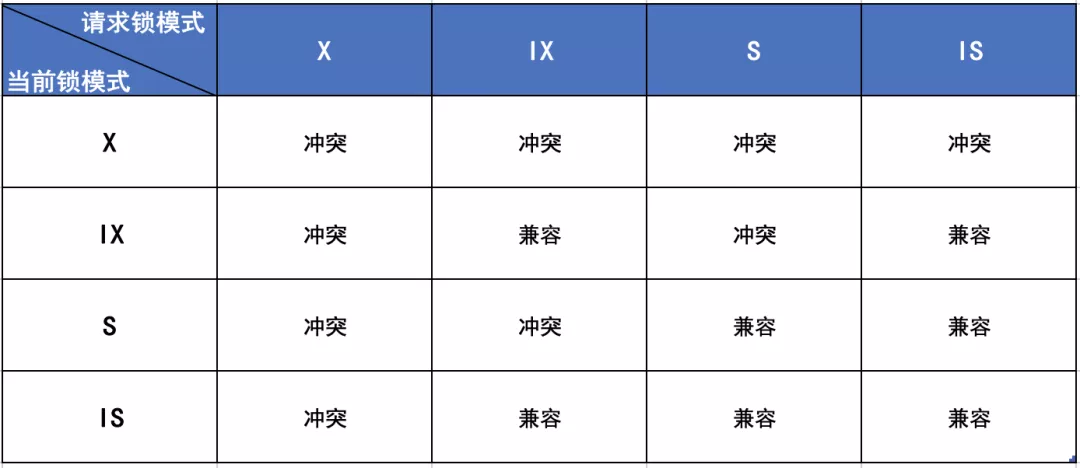
锁模式的兼容情况
那select操作会加锁吗?
对于普通select语句,InnoDB 不会加任何锁。但是select语句,也可以显示指定加锁。有两种模式,一种是LOCK IN SHARE MODE是加共享锁,还有Select ... for updates是加排它锁。
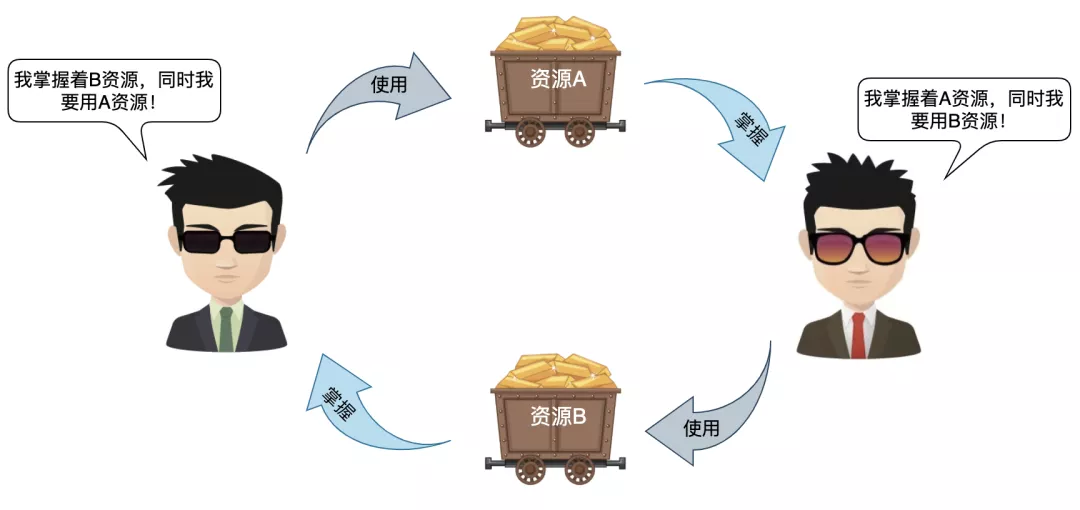
什么情况下会发生死锁?
嗯。。。比如事务A锁住了资源1,然后去申请资源2,但事务B已经占据了资源2,需要资源1,谁都不退让,就死锁了。对于MySQL,最常见的情况,就是资源1、资源2分别对应一个排它锁。
那间隙锁你有了解么?
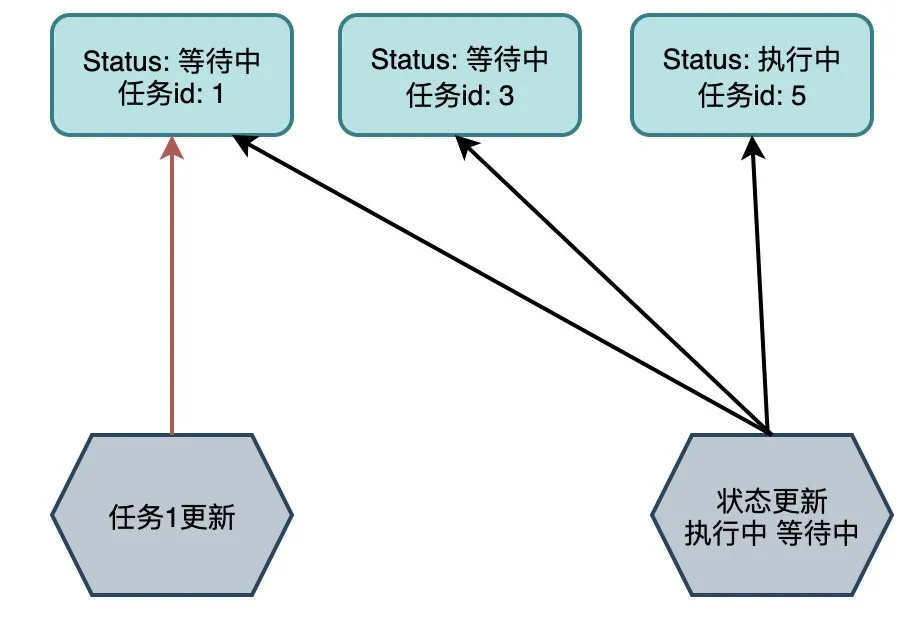
间隙锁就是对索引行进行加锁操作,不仅锁住其本身,还会锁住周围邻近的范围区间。间隙锁的目的是为了解决幻影读,但也因此带来了更大的死锁隐患。
比如,一个任务表里面有个状态字段,是一个非唯一索引,有一个任务id,是唯一索引。
一个sql将状态处于执行中的任务设置为等待中,另一个sql正好通过任务id更新在范围内的一条任务信息。那么因为是在不同索引加锁的,所以都能成功。但是最后去更新主键数据的时候,就会死锁。
最后
介于篇幅,其中的一些知识点,比如MVCC,并未扩展出来深度阐述,建议大家下来自己深入研究一下,牛牛后面也会针对一些重点知识,进行单篇讲解。
原文链接:
https://mp.weixin.qq.com/s/BRn4wXS8afzKjwjkkZ6ATg
这篇关于沉浸式面试:MySQL连环炮,你能抗到第几个?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






