本文主要是介绍从零开始搭建一个基于React框架的博客发布系统 (SIX) Webpack编译配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
打包是门学问,用户浏览你的网站,你应该总是想用户查看不同的页面的同时去加载相应的资源,而不是用户访问你的网站你就一股脑的把服务端资源全部传送给用户,比如我要看第一篇博客,你凭什么把所有的博客全部发给用户,浪费流量倒是小事,但是网站资源过多,这就是性能的瓶颈。
在config下新建blog.js文件,分别把每篇博客作为打包的入口。可以打印一下blog返回的内容。
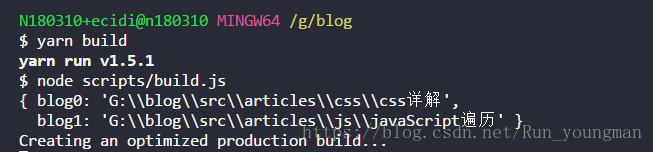
通过这个不难看出,他找到了博客所在的具体文件夹,可以看出第一次打包的产出结果:
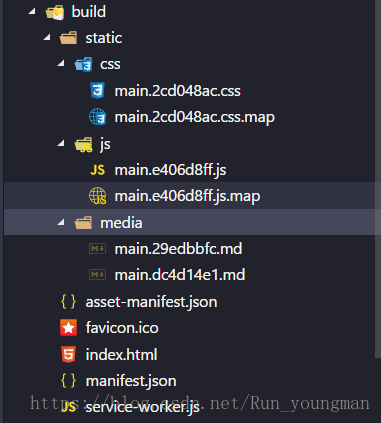
css,js单独放在了一个文件夹中,以及md文件作为静态文件存在。
现在我把entry变成
entry: {app: [require.resolve('./polyfills'), paths.appIndexJs],...blogs},
app文件夹下统一存放index.js引申的文件,blog另外作为入口打包。
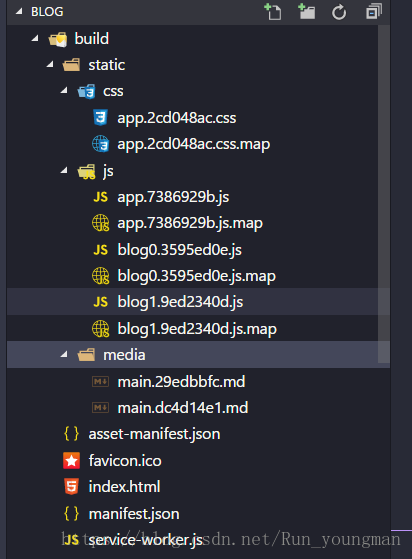
样式还没有处理,但是你可以看到,每一篇博客都被分别打包了。
剩下的时候就是我们开发的时候做的操作,包括raw-loader打包markdown文件,
less-loader,postcss-loader等解析css文件。这些和开发环境是一致的,因为毕竟build也需要执行展示的。
并且,在代码中,我使用了新引入的UglfyJsPlugin,并没有使用webpack**自带**的UglfyJsPlugin,避免一些问题的出现。
new UglifyJsPlugin({ sourceMap: false }),
看看现在的build效果:
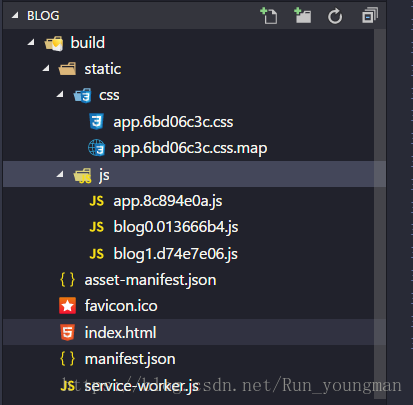
这样依赖打包的内容就更清爽了,直观看到的是.map文件不见了,看刚才的UglfyJsPlugin的配置,
我们把sourceMap设置为了false。
还差一步,我暂时还不知道原因,记得把webpack的一段话修改一下打包方式:
{test: /\.(js|jsx|mjs)$/,include: paths.appSrc,loader: require.resolve('babel-loader'),options: {//compact:true 放弃这个默认的操作。cacheDirectory: true,},},一开始默认的是compact:true
这样一来,就剩下最后一步了,这个就不涉及前端的知识了,记得一开始的时候让大家新建过一个github.io的仓库,这个就是github提供给你存放部署代码的,你提交上去的代码他会自动为你部署,然后通过https://xxx.github.io就可以访问自己添加的内容了。
到这里,博客系统就告一段落了,以后可能会继续升级功能,谢谢收看,有问题留言哦。
这篇关于从零开始搭建一个基于React框架的博客发布系统 (SIX) Webpack编译配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





