本文主要是介绍【论文解析】抽象摘要中基本语篇单位的构建(ACL 2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:https://www.aclweb.org/anthology/2020.acl-main.551.pdf
本文的起点
最近的抽象式摘要都是对于提前抽取的每个句子进行精简或者重写,但是一般来讲,有些句子是连贯的,例如需要合并2个句子为1个句子。
想去做一个新的摘要方法,相比较句子级别的摘要,它能够更有信息量,也更精简。
待解决的问题,一个是哪些EDU应该被挑选出来;另一个问题是如何将这些EDU去拼接成一个更流畅的摘要。
贡献
使用EDU代替句子作为基本的抽取单元(与另一篇一样)
使用强化学习应用到EDU的选取上(其实之前也有类似的工作,文中也提到)
提出重写时,是根据其EDU所属的块进行重写,完成既精简,又可以保留丰富信息的重写。那么如何划分这些EDU块又是一个关键问题。
据他们所说,是第一个提出在摘要中使用EDU的方法。实验表明它取得了(显著,从实验结果上看,也并不是十分显著)的提升。
它的大部分工作都借鉴于Fast Abstractive Summarization with
Reinforce-Selected Sentence Rewriting,包括将抽取和生成两个部分相结合,以及使用预训练来解决开局困惑的问题。(可以看Fast-abs的解读)
在这个基础之上,作者增加了2个部分改变,一个是将选取的基本单元使用EDU代替句子,第二部分就是在抽象时,增加EDU的group操作,从而形成一个一个句子,其他的基本都没变。
做法
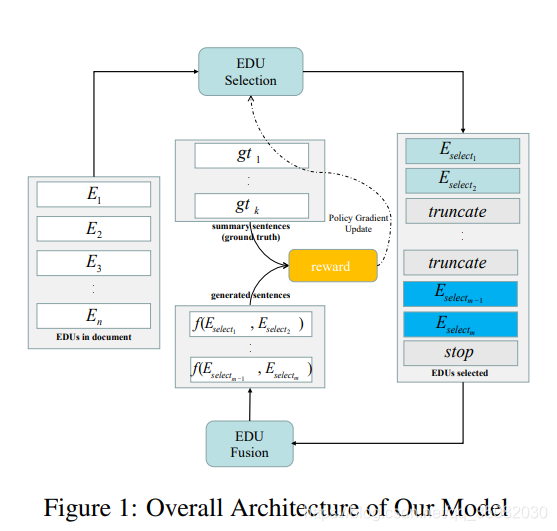
抽取式摘要中有两部分,一个是EDU抽取,一个是EDU融合。
在EDU抽取部分:
在挑选EDU时,使用的是PT网络,编码使用的是CNN+LSTM。
在解码时,除了可以指向EDU,还可以指向2个标识符分别表示了分割位置和终止。
在EDU融合部分:
在句子融合时,使用的是标准的PT网络进行生成(Get To The Point: Summarization with Pointer-Generator Networks)。
最后使用强化学习,根据融合后的预测结果与标注结果的 R 1 f R1_f R1f值作为奖励值来调节抽取模型。特别的,它需要预训练这两部分的模型,使用的是最大似然目标优化。在抽取EDU部分,它也是贪心的选取EDU,使得 R L r RL_r RLr值增加的最多。但是与上一篇不同的是,他没有规定挑选出多少个EDU,而是由模型学习所得。在融合EDU部分直接与标准的摘要做对比。
模型
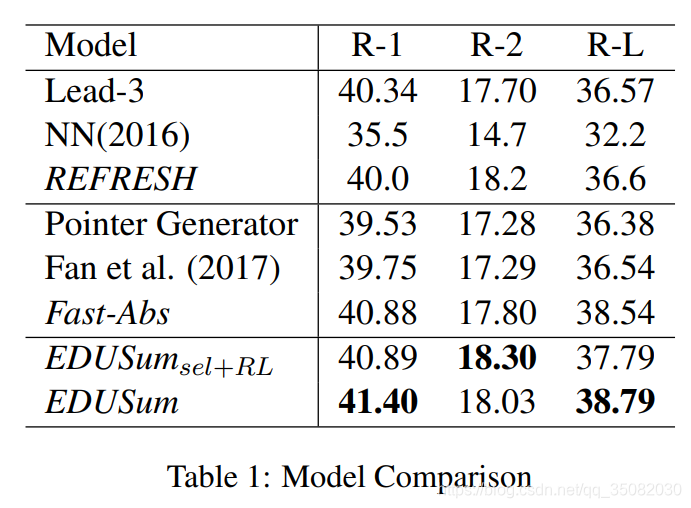
性能表现
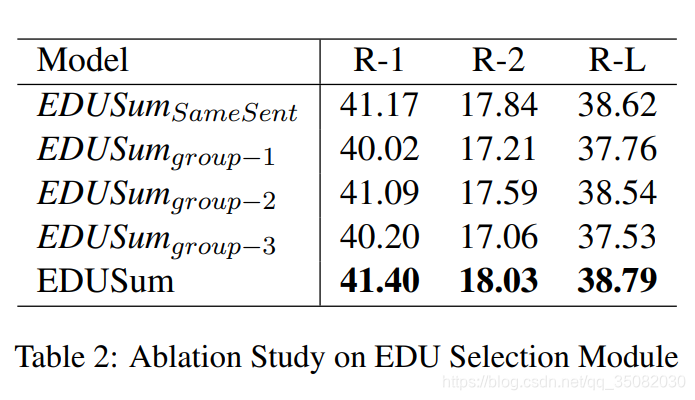
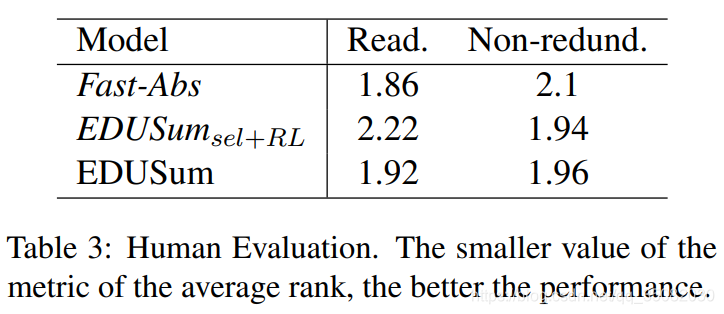
新知识
如何进行人工评估质量,例如可阅读性和冗余性?上一篇使用的是人工打分,那这个打分的主观性很强,本文中,使用的是排名,这个相对客观一些,选取一些基准系统,将结果进行排名,从而获得一个平均的名次,作为其一种评价指标。这也是非常好的想法。
问题
问题是它也并没有取得最优性能,例如EMNLP2019年的BERTsum会高很多。(可能是没有用BERT的原因)。
另外,它与Fast-Abs进行了对比,但是Fast-Abs有抽取式和抽象式2个性能,它只与抽象式进行了比较,而这个性能会低一些。而作者的只抽取的模型性能还有一些下降,个人认为是EDU抽取仍然没有句子抽取准确。
正如上面讲的,它主要借鉴了Fast-Abs的工作,因此在本文中,确实有很多细节没有描述清楚,一些表述也是稍微有一些不一致等。
新单词
compressing 精简
remedy纠正
thorough 周密的
non-redundancy 不冗余的
这篇关于【论文解析】抽象摘要中基本语篇单位的构建(ACL 2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




