本文主要是介绍MySQL:修改系统时钟会导致数据库hang住吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
水平有限,有误请谅解
约定:
page rwlock:控制page frame本生的读写锁,这个通常再进行对page的读取和修改的时候会涉及到,比如对page的修改需要上x类型的锁。
page mutex:主要控制page的io状态等信息的mutex,本文不涉及。
MTR:最小日志单元,对于写操作而言,其中包含了redo信息和page rwlock信息,MTR提交的时候会释放page rw lock,并且将本次MTR的redo信息写到redo buffer。
一、问题展示
最近遇到2次这个比较奇葩得问题,一次是8.0.16/一次是8.0.18,主要是信号量监控线程发现读写锁超时自杀重启数据库。问题现象如下:
读写锁超时crash
主要的等待在如下的rwlock上,如下:
某线程 --Thread 140571742508800 has waited at buf0flu.cc line 1357 for 830 seconds the semaphore
某线程 --Thread 140579717510912 has waited at btr0pcur.h line 656 for 613 seconds the semaphore
当然不是上面这么少,肯定很多,但是类型大概就是这两种。
日志系统完全停止
这个问题主要在于整个信号量超时期间,从第一个信息输出到最后一个信息输出都不会变比如如下:
Log sequence number 20600471237
Log buffer assigned up to 20600471237
Log buffer completed up to 20600471237
Log written up to 20600471237
Log flushed up to 20600471237
Added dirty pages up to 20598368792
Pages flushed up to 20598368792
Last checkpoint at 20598368792
...
Pending writes: LRU 0, flush list 2, single page 0这里伴随着刷盘IO的问题。
二、初次分析
这些堵塞的线程到底是什么,又堵塞在什么读写锁上
一般来讲我们读写锁一般都说文中开头说的page rwlock。
--Thread 140571742508800 has waited at buf0flu.cc line 1357 for 830 seconds the semaphore 这种类型的实际上一看等待点就知道这玩意是clean线程,稍微翻一下代码就知道这里是在做flush list的刷盘。通常刷盘的时候会获取page rwlock(sx类型)
--Thread 140579717510912 has waited at btr0pcur.h line 656 for 613 seconds the semaphore 这种类型的实际上就是正常的用户session,在对page进行访问或者修改的时候需要page rwlock(x/s类型)。
那么我们的redo日志系统卡住前后的几个lsn代表什么意思呢?如下:
Log written up to 20600471237
Log flushed up to 20600471237
Added dirty pages up to 20598368792
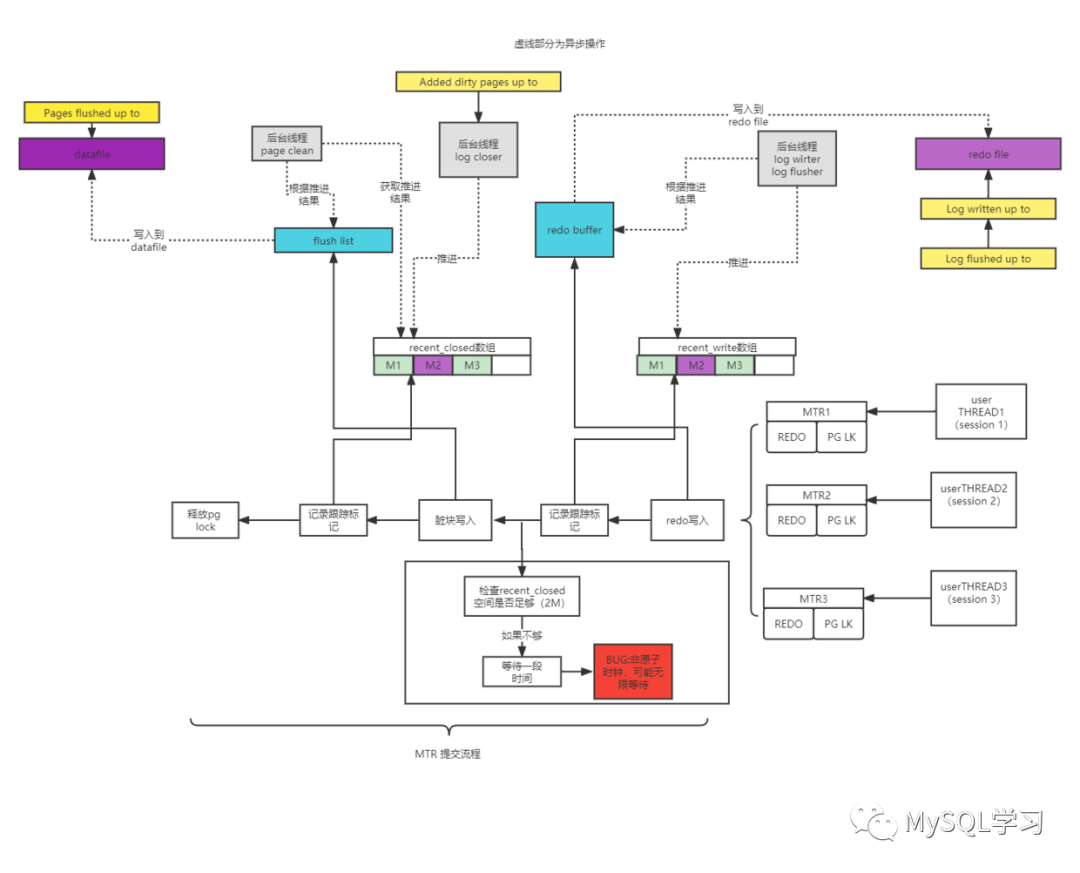
Pages flushed up to 20598368792Log written up to :这实际上是log writer线程写入到的redo的lsn位,在log_files_write_buffer函数内部更改,当然log writer是不断地进行recent write数组,然后不断地写入到redo。对应log.write_lsn.load()。
Log flushed up to:这实际上是log flusher线程刷盘到的redo的lsn位点,在log_flush_lown函数内部更改。对应 log.flushed_to_disk_lsn.load()。
Added dirty pages up to:这实际上在8.0.16/8.0.18是由log closer线程更新的,但是8.0.22对log closer线程做了删除,直接由用户线程自己负责。主要是查看推进的recent close数组的位点。对应就是log.recent_closed.tail()变量。而recent close数组作为clean线程和用户线程(8.0.22之前还有log closer线程)之间同步信息,我们很容易发现clean线程在根据recent close数组推进的结果进行刷脏参考函数page_cleaner_flush_pages_recommendation的开头。
Pages flushed up to:这实际上又log checkpoint线程更新,在进行进行检查点之前,会进行可以进行检查点的位置,那么这个位置必须是已经写了脏数据的位点,从计算的方式来看主要是应该是获取各个buffer pool上flush list最老的那个page,那么就是当前脏叶刷新的位点,但是有一些特别的计算函数log_compute_available_for_checkpoint_lsn
我们看到一个特别的现象就是Log flushed up to - Added dirty pages up to 大概不就是2M的空间,我印象中recent_closed数组的最大值就是2M,因此是不是说明recent_closed已经满了,但是log closer线程不做推进了。如果是这种情况也很容模拟,我只需要用gdb的挂起线程的功能,将log closer挂起即可,我随后进行了测试确实现象一模一样。这也很容易理解,如果redo刷盘功能停止,那么MTR的提交必然会受到堵塞,而我们page rwlock在MTR提交的时候释放,所以hang住很容易理解。那么是不是有BUG呢,当然版本比较老,如果有这个问题应该会由爆出来,因此用 log closer BUG mysql为关键字好像并没有找到相关的BUG。
三、再次分析
前面考虑的是recent_closed数组已满的情况,还会不会是recent_closed数组根本就是空的呢,我随后查看log closer问题时候的stack,发现是正常的等待状态,因此recent_closed数组为空的可能性就很大了。然后稍微看看MTR提交的时候关于recent_closed的更改前会判断recent_closed是否有足够的空间,如果这里出现问题,那么后面的recent_closed数组更新和将脏块挂入到flush list就不会做,那么log_closer线程自然会在推进完最后一次recent_closed数组后,因为无事可做而挂起。代码很简单就是下面这点:
然后呢我以log_wait_for_space_in_log_recent_closed函数为关键字寻找BUG,真还有如下:
https://bugs.mysql.com/bug.php?id=96615
看提交者的描述这种问题就会导致 log closer无事可做而挂起,原因是在等待空闲recent_closed数组空间的时候用的不是原子时钟,如果修改系统时间可能会出现这个问题。官方也没说修复这个问题,最后的回复如下:
看来真的不能随便更改系统时间,非原子时钟问题,可能导致某些该唤醒的不能唤醒。这回导致系统直接hang住。
可能这样描述比较难理解,我用一个图来表示吧,因为涉及的东西比较多。注意了,这里不是说的事务提交,是MTR的提交,实际上我们的redo是一直在做写入操作的,MTR的提交和后台线程之间是异步的。但是一旦涉及到事务提交,那么双1的情况下就必须要保证redo 刷盘,那么到底异步的这些操作到底刷盘没有,那就需要去额外的确认操作,如果还没刷盘那就等,这个由我们的log_writer_notifier/log_flush_notifier线程介入,却确认和反馈给用户线程。但是这个BUG里不涉及,红色部分就是问题所在点,
这篇关于MySQL:修改系统时钟会导致数据库hang住吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





