本文主要是介绍【Bug】【内存相关】偶然发现一个内存溢出Bug复盘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、问题
跑自动化用例的时候,uat-sg环境,发现SGW经常会返回 502 Bad Gateway响应
二、原因
经过SRE和BE Dev共同排查,502 是从ALB-- > 后端服务 后端服务无法响应导致,ALB会直接给客户端返回502。
服务端:由于cgroup升级到v2,java无法正确识别内存配置(设置32G,实际物理内存只有16G),导致内存溢出,服务重启,一直没响应给ALB,所以返回502
检查实际启动参数内存分配:

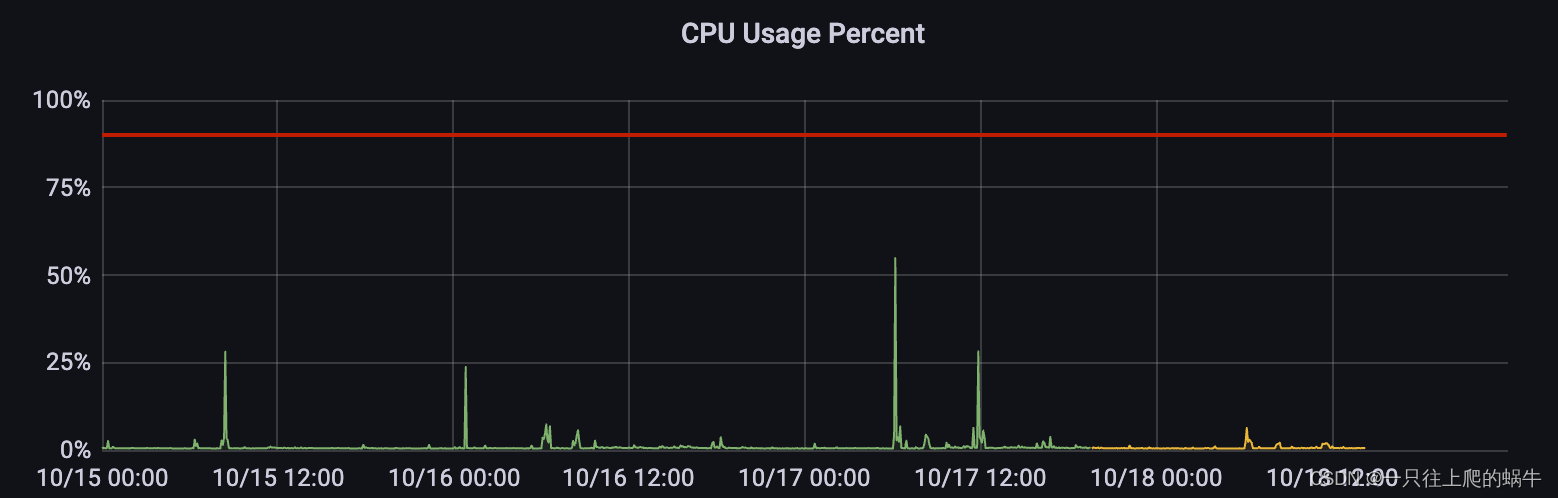
检查grafana CPU监控,发现有波动
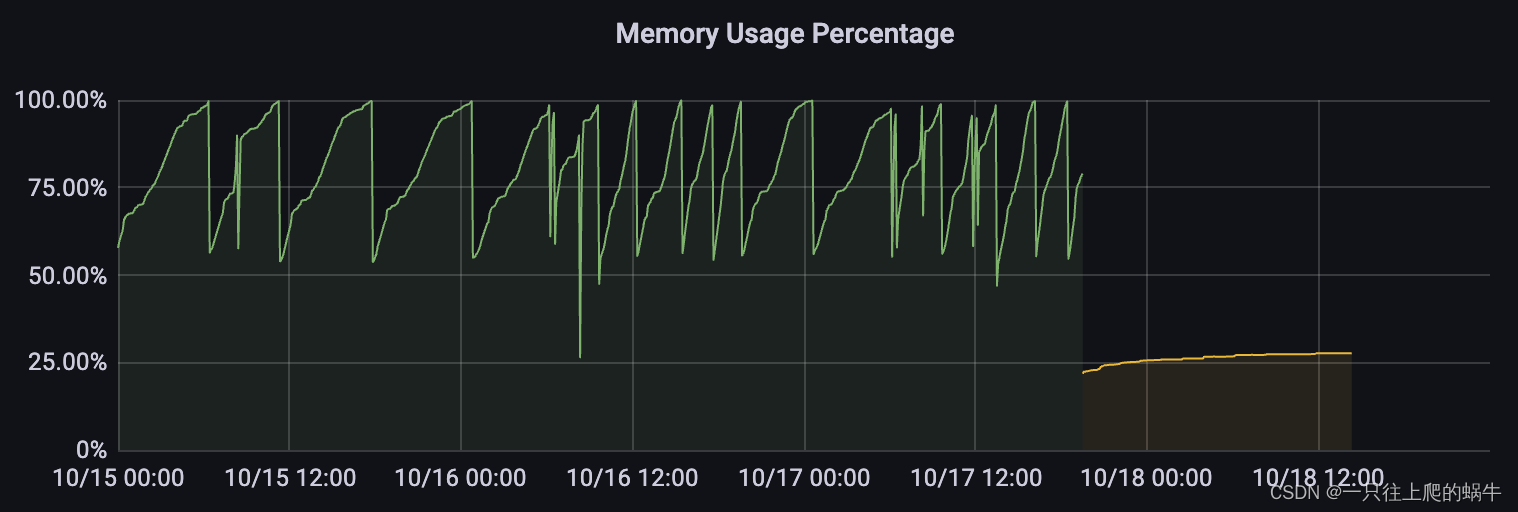
检查grafana 内存监控,发现有用完情况
检查服务重启日志,有对应重启记录

三、解决办法
将Java启动参数-jar -XX:InitialRAMPercentage=80.0 -XX:MaxRAMPercentage=80.0 -XX:MinRAMPercentage=80.0
修改为:-jar -Xms12g -Xmx15g
四、效果
修改后,所有自动化未返回502
五、影响
live xx地区可能会有相同现象,发版解决
六、监控告警
思考:建立live环境服务器资源阈值告警体系,及时发现问题
这篇关于【Bug】【内存相关】偶然发现一个内存溢出Bug复盘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





