本文主要是介绍一个使用公式化序列分类的EAL学术写作的辅助环境,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:
为新手英语作为一种附加语言(EAL)作者写一篇英语研究文章是一项具有挑战性的任务,需要在句子和意义水平上的经验和训练。EAL作者在撰写研究文章时采用的一个策略是使用公式化序列(FSs)。然而,可用的FS语料库是通用的,而且规模非常有限。先前的研究已经报道了使用少量FSs的书面使用FS的有效性。本研究提出了一个通过使用特定领域的FSs来改进学术写作的辅助环境。FSs从已发表的文章中提取出来,并使用机器学习技术进行修辞学分类。然后,用户可以从任何使用建议的原型的研究文章中搜索和添加他/她选择的新FSs。在实际环境中评价了所提方法的有效性。结果表明,该提案对学术写作的改进有积极的影响。与使用传统术语库方法的人相比,使用该原型的新手作者报告的感知有用性明显更高。
辅助修辞短语写作系统 (ARP) :
本研究的目的是设计和开发一个使用机器学习的智能辅助学术写作系统,即一种有监督学习的方法。机器学习是一种数据分析方法,包括建立预测和分类的模型。为了做出预测,我们使用基于样本数据进行训练的机器学习分类器建立了一个精确的数学模型。目标标签可以根据学习到的数据集分配给新的测试数据集。准确的结果预测取决于模型的训练效果。本研究利用提取的多类别句子对模型进行训练
训练模型的构建:
该预测模型通过将期望输出与输入实例配对来训练预测模型。该系统以生物化学和计算机科学研究文章的摘要和介绍作为输入,并在训练阶段结束时选择最终的预测模型,用于预测类标签。

特征提取模块:
| 种类 解释 |
| 背景 关于知识领域被广泛接受的陈述 结论 调查的结论;从观察和结果中推断出的陈述 实验 作者所进行的实验和他们所使用的实验方法 目标 是研究者要解决的问题 假设 在调查后被证明是正确或假的陈述 方法 用来解决问题的方法或过程 模型 用于研究的模型类型;它取决于主题 动机 为什么研究是必要的,为什么应该进行 问题 所提出的研究旨在解决的多个问题或多个问题 结果 研究成果和讨论结果 |
根据图1所示的体系结构,形成了两个特征向量作为输出,一个来自自动特征提取,另一个来自手动特征提取。这些实例按行组织,这些特性按列组织,如表2所示。这些列只描述了为预测模型选择的提取的特征片段。稀疏矩阵中的每一行都描述了来自数据集的一个特征向量或句子。最后一列描述了给定的句子或实例的类标签。
参与者:
本研究的参与者是来自一所大学信息技术学院的硕士学生(共58名,27名女性和31名男性)。这些学生正在攻读计算机科学硕士学位,主修人工智能(18名学生)、软件工程(22名学生)和计算机网络(18名学生)。作为硕士学位课程的一个合格标准,所有的学生都需要通过24个学分的课程作业和10个学分的研究(论文)。所有学生在课程过程中选修三门核心课程和五门专业课程。两到四个学生只有一个主管。

为了帮助学生写下他们的研究工作的介绍,在实验开始时进行了一个培训课程。培训课程包括以下主题:
(1)如何开始和结束一个介绍,让读者参与和专注于建议的工作?
(2)信息呈现的顺序,更重要的是修辞信息的类型。
结果:
| 分组 | 数量 | 平均数 | 标准偏差 | t | |
| EG | 实验组 | 31 | 29.25 | 2.09 | 0.178 |
| CG | 控制组 | 27 | 29.37 | 2.69 |
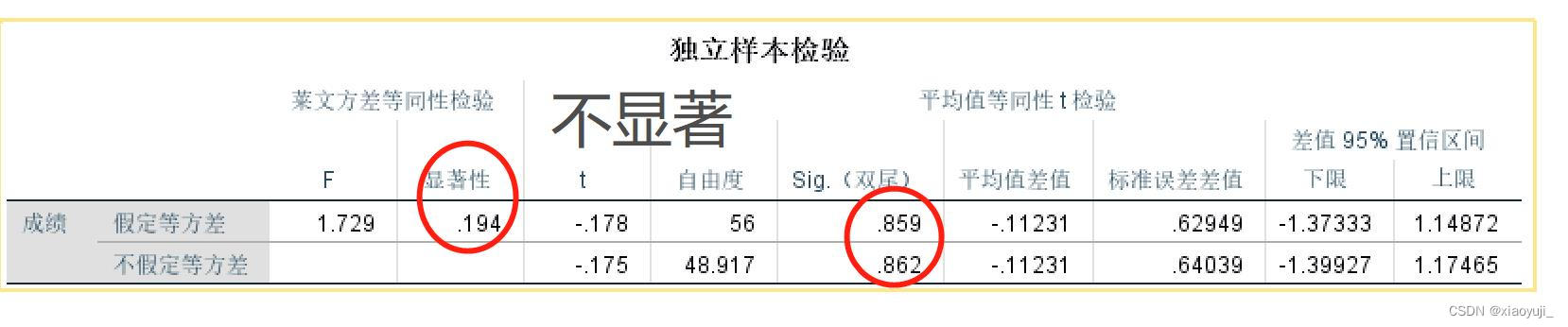
实验组的总均值为29.25,标准差为2.09,而对照组的总均值为29.37,标准差为2.69。采用非配对样本t检验,也称为独立样本t检验,以检验两组之间的显著性差异。t检验的结果显示,检验前的p=0.194大于0.05。这说明我们,两组学生的技能水平和基线知识水平之间没有显著差异。零假设,即两组在干预前具有相同水平的写作技能被接受。
表5:后测的t检验措施
| 分组 | 数量 | 平均数 | 标准偏差 | t | |
| EG | 实验组 | 31 | 42 | 4.16 | -5.277 |
| CG | 控制组 | 27 | 36.59 | 3.55 |

干预后,我们进行了后测,以发现对照组与实验组之间的统计学意义。所有学生在后测中均有满意的成绩,但实验组得分较高。对照组和实验组的检验后计算结果见表5。检验后得分的独立样本t检验结果显示,显著性值p小于0.05。这说明对照组和实验组的学术写作能力存在很大差异。由于干预后两组人都具有相同水平的写作技能,因此拒绝了零假设。实验组总体均值为42,标准差为4.16,而对照组总体均值为36.59,标准差为3.55。预试前的平均得分使得很难决定谁表现更好,但在原型干预后,实验组的得分远远高于对照组。结果表明,该原型有助于提高这些研究生的学术写作水平。
结论:
本文提出了一个学术写作支持的辅助环境,以及计算机科学研究生的概要和论文写作的实验结果。该系统通过从已发表的文章中提取和分类句子,为新手作者提供了特定领域的公式化序列。结果表明,所提出的辅助环境提高了学生文章的写作质量和结构。
未来写作方向:
目前的工作的一个局限性是,只有在科学领域的研究文章被用于训练和测试机器学习模型。社会科学研究领域有不同的公式化序列集,需要不同的特征提取集。本建议的并不局限于写作技能的提高;本建议可以扩展到基于修辞学句子的研究文章之间的相似性计算。
这篇关于一个使用公式化序列分类的EAL学术写作的辅助环境的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




