本文主要是介绍20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)
2023/8/9 19:02
由于喜欢看纪录片等外文视频,通过剪映/PR2023/AUTOSUB识别字幕之后,可以通过google翻译识别为简体中文的DOCX文档。
DOCX文档转换为TXT文档之后,还需要修饰其中的字幕序号才能得到最终所需要的简体中文SRT文档。
google.py
#f=open("./1574/%03d.ts"%(n+1),"wb")
f=open("12.txt","wb")
#f = open("p:\\ts\\1574.txt")
f1 = open("1.txt")
#for n in range(1,4000):
for n in range(1,4560):
line = f1.readline()
#f.write(response.content)
#f.write(line)
f.decode().write(line)
f.close()
google12.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\py>python google12.py > test.srt
f_path=r'1.txt'
temp = 1
xuhao = 1;
with open(f_path) as f:
lines = f.readlines()
for line in lines:
if temp == 1:
print(str(xuhao))
temp=0
else:
if len(line) == 1:
#print("jiangedian!")
temp=1
xuhao = xuhao+1
print(line.rstrip())
txt2srt3all.py
【处理目录下的全部ANSI编码的TXT字幕为SRT字幕,但是不处理字目录!】
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
f2=open(new_file,"wb")
#f_path=r'C:\Users\Admin\Desktop\shapenetcore_partanno_segmentation_benchmark_v0_normal_2\00000001\0.txt'
#f_path=r'1.txt'
#f_path=file
temp = 1
xuhao = 1;
#with open(f_path) as f:
with open(file) as f:
lines = f.readlines()
for line in lines:
if temp == 1:
#print(str(xuhao))
#f.decode().write(line)
#f2.decode().write(str(xuhao))
#f2.write(str(xuhao))
f2.write(str(xuhao).encode())
f2.write(str('\n').encode())
temp=0
else:
if len(line) == 1:
#print("jiangedian!")
temp=1
xuhao = xuhao+1
#print(line.rstrip())
#f.decode().write(line)
#f2.decode().write(line.rstrip())
#f2.write(line.rstrip())
f2.write(line.encode())
#f=open(new_file,"wb")
f2.close()
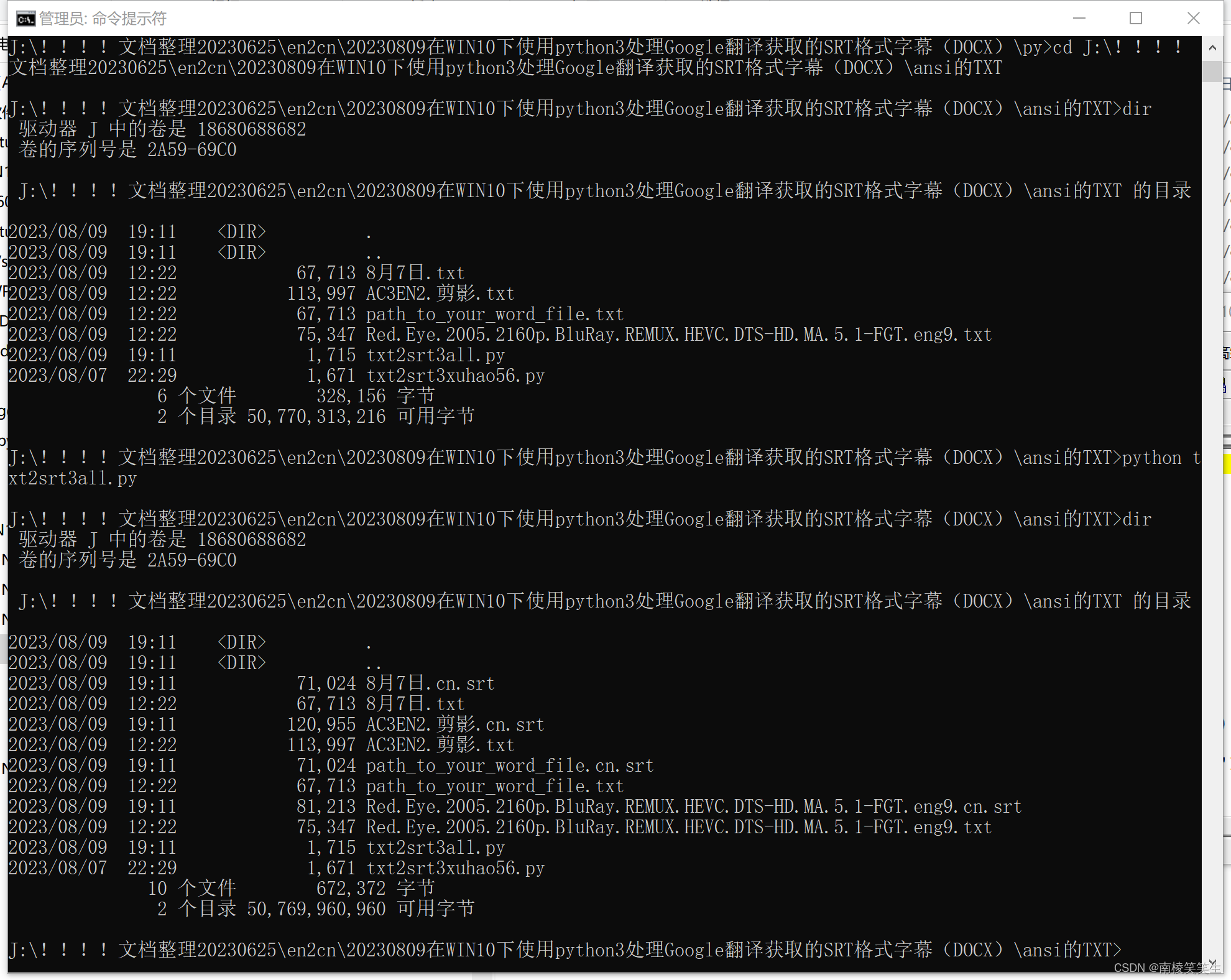
LOG:
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT>dir
驱动器 J 中的卷是 18680688682
卷的序列号是 2A59-69C0
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT 的目录
2023/08/09 19:11 <DIR> .
2023/08/09 19:11 <DIR> ..
2023/08/09 12:22 67,713 8月7日.txt
2023/08/09 12:22 113,997 AC3EN2.剪影.txt
2023/08/09 12:22 67,713 path_to_your_word_file.txt
2023/08/09 12:22 75,347 Red.Eye.2005.2160p.BluRay.REMUX.HEVC.DTS-HD.MA.5.1-FGT.eng9.txt
2023/08/09 19:11 1,715 txt2srt3all.py
2023/08/07 22:29 1,671 txt2srt3xuhao56.py
6 个文件 328,156 字节
2 个目录 50,770,313,216 可用字节
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT>python txt2srt3all.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT>dir
驱动器 J 中的卷是 18680688682
卷的序列号是 2A59-69C0
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT 的目录
2023/08/09 19:11 <DIR> .
2023/08/09 19:11 <DIR> ..
2023/08/09 19:11 71,024 8月7日.cn.srt
2023/08/09 12:22 67,713 8月7日.txt
2023/08/09 19:11 120,955 AC3EN2.剪影.cn.srt
2023/08/09 12:22 113,997 AC3EN2.剪影.txt
2023/08/09 19:11 71,024 path_to_your_word_file.cn.srt
2023/08/09 12:22 67,713 path_to_your_word_file.txt
2023/08/09 19:11 81,213 Red.Eye.2005.2160p.BluRay.REMUX.HEVC.DTS-HD.MA.5.1-FGT.eng9.cn.srt
2023/08/09 12:22 75,347 Red.Eye.2005.2160p.BluRay.REMUX.HEVC.DTS-HD.MA.5.1-FGT.eng9.txt
2023/08/09 19:11 1,715 txt2srt3all.py
2023/08/07 22:29 1,671 txt2srt3xuhao56.py
10 个文件 672,372 字节
2 个目录 50,769,960,960 可用字节
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\ansi的TXT>
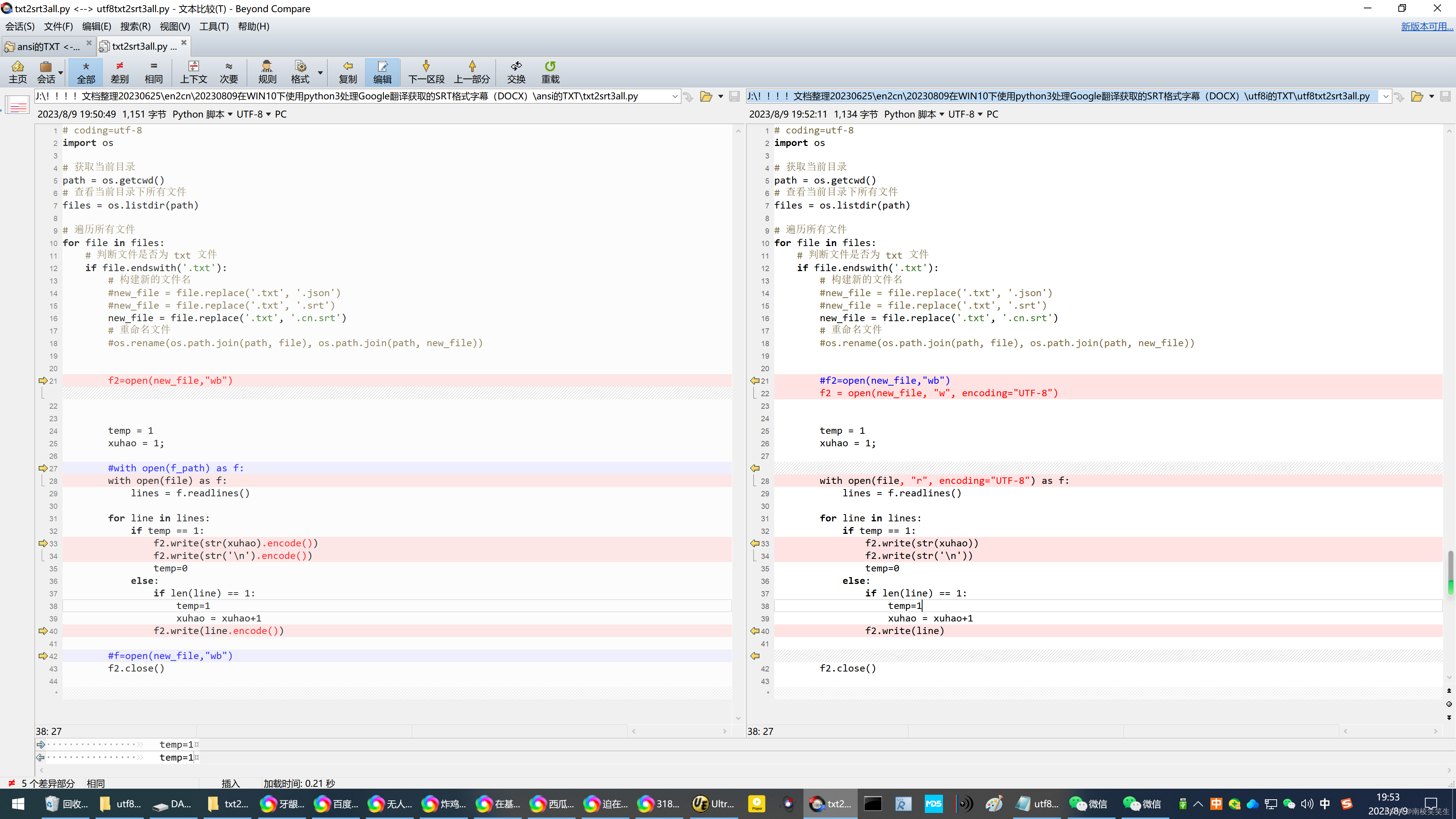
utf8txt2srt3all.py
【处理目录下的全部UTF8编码的TXT字幕为SRT字幕,但是不处理字目录!】
# coding=utf-8
import os
# 获取当前目录
path = os.getcwd()
# 查看当前目录下所有文件
files = os.listdir(path)
# 遍历所有文件
for file in files:
# 判断文件是否为 txt 文件
if file.endswith('.txt'):
# 构建新的文件名
#new_file = file.replace('.txt', '.json')
#new_file = file.replace('.txt', '.srt')
new_file = file.replace('.txt', '.cn.srt')
# 重命名文件
#os.rename(os.path.join(path, file), os.path.join(path, new_file))
#f2=open(new_file,"wb")
#with open(new_file, "w", encoding="UTF-8") as txt_file:
#f2 = open(new_file, "wb", encoding="UTF-8")
f2 = open(new_file, "w", encoding="UTF-8")
temp = 1
xuhao = 1;
#with open(f_path) as f:
#with open(file) as f:
#with open(new_file, "w", encoding="UTF-8") as txt_file:
#with open(file, "w", encoding="UTF-8") as f:
with open(file, "r", encoding="UTF-8") as f:
lines = f.readlines()
for line in lines:
if temp == 1:
#f2.write(str(xuhao).encode())
#f2.write(str('\n').encode())
f2.write(str(xuhao))
f2.write(str('\n'))
temp=0
else:
if len(line) == 1:
temp=1
xuhao = xuhao+1
#f2.write(line.encode())
f2.write(line)
f2.close()
参考资料:
https://pythonjishu.com/nwbuyryewwscpxl/
使用Python对文件进行批量改名的方法
python docx utf8 读写
https://deepinout.com/python/python-qa/t_how-to-read-and-write-unicode-utf-8-files-in-python.html
如何在Python中读写Unicode(UTF-8)文件?
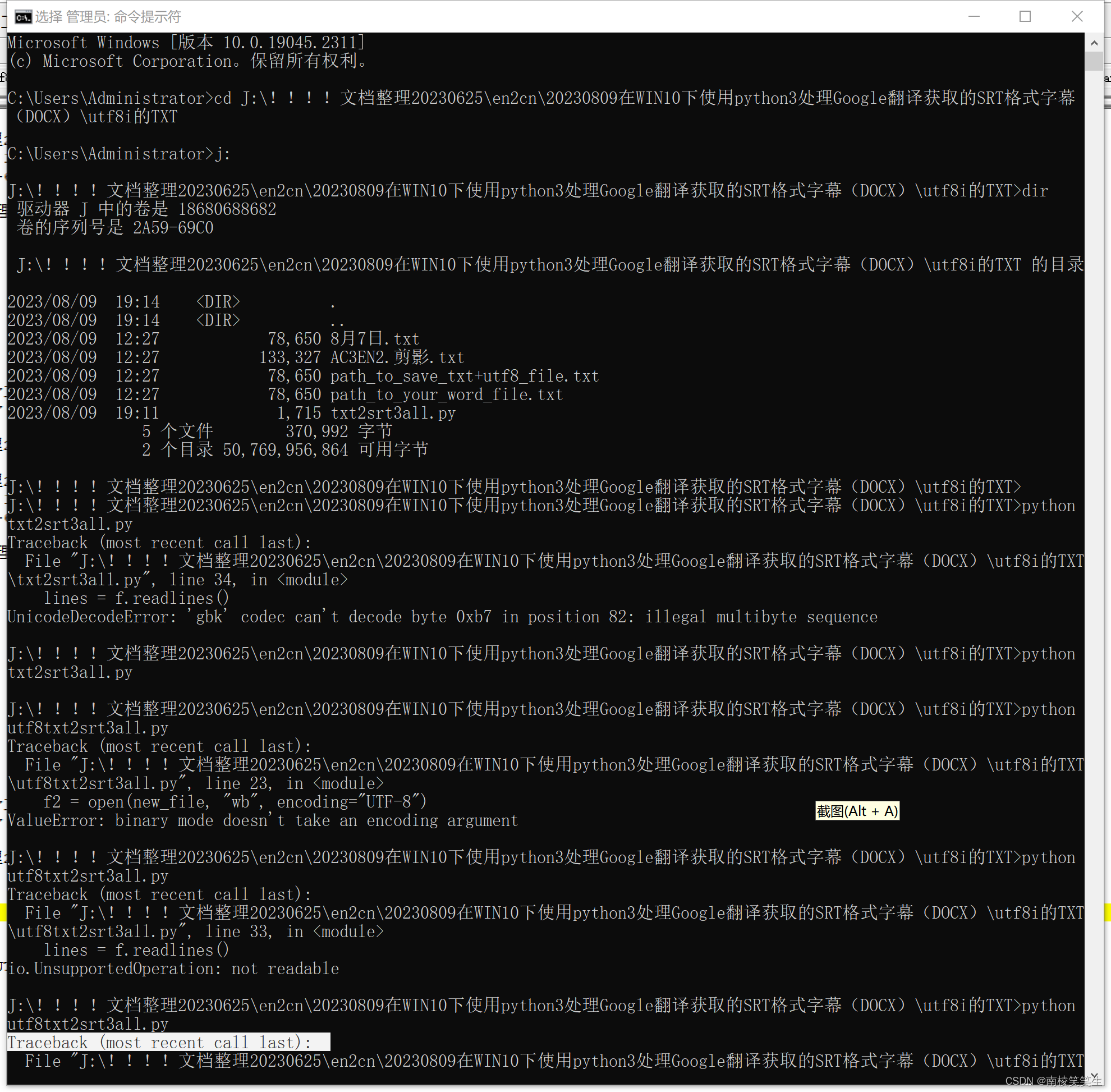
UTF8的脚本的调试记录,写法有很大的差异的!
Microsoft Windows [版本 10.0.19045.2311]
(c) Microsoft Corporation。保留所有权利。
C:\Users\Administrator>cd J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕 (DOCX)\utf8i的TXT
C:\Users\Administrator>j:
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>dir
驱动器 J 中的卷是 18680688682
卷的序列号是 2A59-69C0
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT 的目录
2023/08/09 19:14 <DIR> .
2023/08/09 19:14 <DIR> ..
2023/08/09 12:27 78,650 8月7日.txt
2023/08/09 12:27 133,327 AC3EN2.剪影.txt
2023/08/09 12:27 78,650 path_to_save_txt+utf8_file.txt
2023/08/09 12:27 78,650 path_to_your_word_file.txt
2023/08/09 19:11 1,715 txt2srt3all.py
5 个文件 370,992 字节
2 个目录 50,769,956,864 可用字节
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python txt2srt3all.py
Traceback (most recent call last):
File "J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT\txt2srt3all.py", line 34, in <module>
lines = f.readlines()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb7 in position 82: illegal multibyte sequence
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python txt2srt3all.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
Traceback (most recent call last):
File "J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT\utf8txt2srt3all.py", line 23, in <module>
f2 = open(new_file, "wb", encoding="UTF-8")
ValueError: binary mode doesn't take an encoding argument
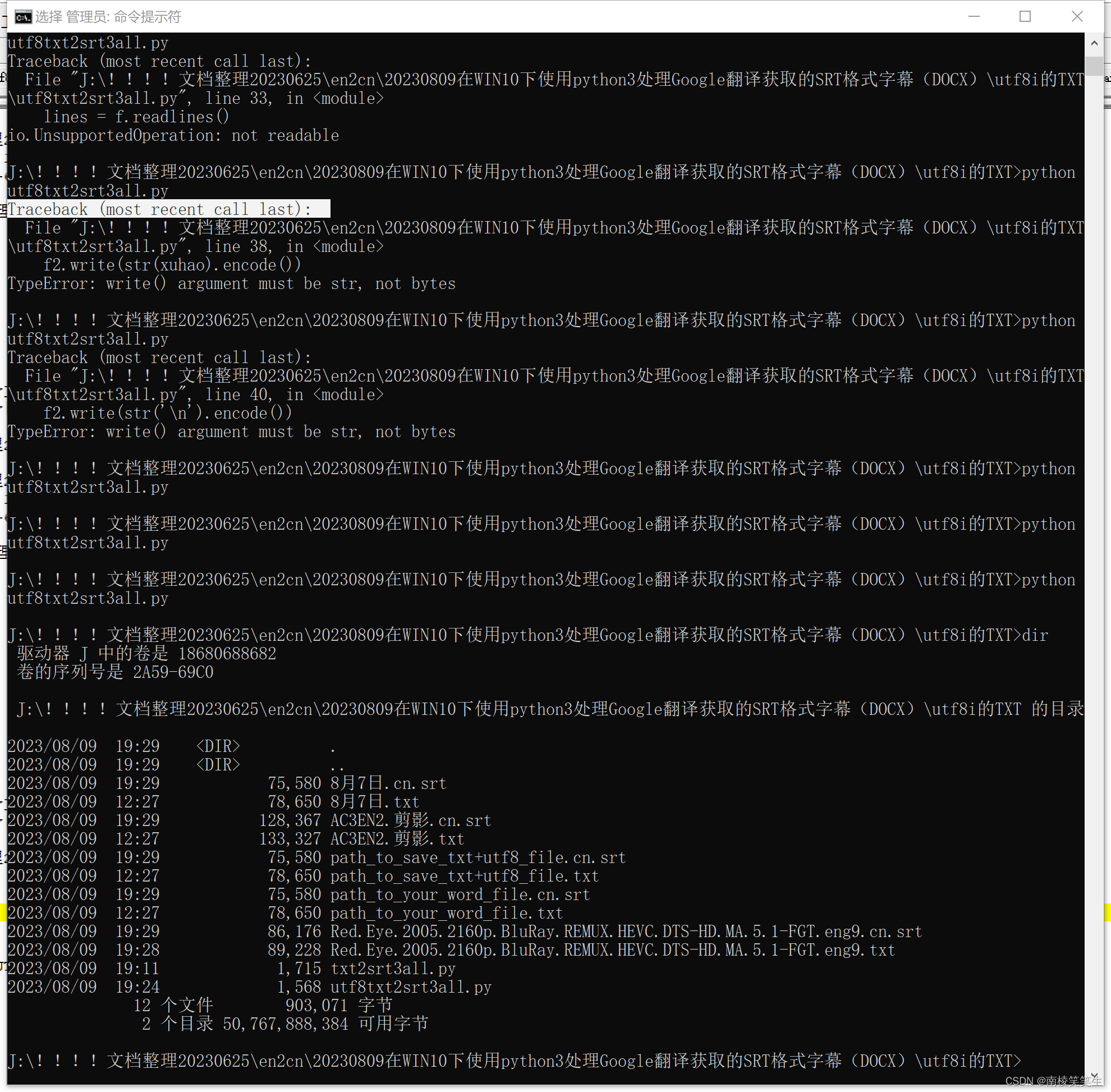
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
Traceback (most recent call last):
File "J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT\utf8txt2srt3all.py", line 33, in <module>
lines = f.readlines()
io.UnsupportedOperation: not readable
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
Traceback (most recent call last):
File "J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT\utf8txt2srt3all.py", line 38, in <module>
f2.write(str(xuhao).encode())
TypeError: write() argument must be str, not bytes
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
Traceback (most recent call last):
File "J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT\utf8txt2srt3all.py", line 40, in <module>
f2.write(str('\n').encode())
TypeError: write() argument must be str, not bytes
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>python utf8txt2srt3all.py
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>dir
驱动器 J 中的卷是 18680688682
卷的序列号是 2A59-69C0
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT 的目录
2023/08/09 19:29 <DIR> .
2023/08/09 19:29 <DIR> ..
2023/08/09 19:29 75,580 8月7日.cn.srt
2023/08/09 12:27 78,650 8月7日.txt
2023/08/09 19:29 128,367 AC3EN2.剪影.cn.srt
2023/08/09 12:27 133,327 AC3EN2.剪影.txt
2023/08/09 19:29 75,580 path_to_save_txt+utf8_file.cn.srt
2023/08/09 12:27 78,650 path_to_save_txt+utf8_file.txt
2023/08/09 19:29 75,580 path_to_your_word_file.cn.srt
2023/08/09 12:27 78,650 path_to_your_word_file.txt
2023/08/09 19:29 86,176 Red.Eye.2005.2160p.BluRay.REMUX.HEVC.DTS-HD.MA.5.1-FGT.eng9.cn.srt
2023/08/09 19:28 89,228 Red.Eye.2005.2160p.BluRay.REMUX.HEVC.DTS-HD.MA.5.1-FGT.eng9.txt
2023/08/09 19:11 1,715 txt2srt3all.py
2023/08/09 19:24 1,568 utf8txt2srt3all.py
12 个文件 903,071 字节
2 个目录 50,767,888,384 可用字节
J:\!!!!文档整理20230625\en2cn\20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)\utf8i的TXT>
这篇关于20230809在WIN10下使用python3处理Google翻译获取的SRT格式字幕(DOCX)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


