本文主要是介绍Python实现word或pdf文件转png长图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python实现word/pdf文件转png长图
- 背景
- 思路
- 不足
- 实现
- 1. word转pdf
- 2. pdf转图片
- 3. 图片空白行删除
- 效果
背景
最近写项目周报要求转为长图片输出,本着“自己动手,丰衣足食”(抠门)的原则,就不购买xx会员了,自己动手做一个word转换图片的小工具~~
思路
- 先将Word文档转为pdf文件。
- 读取pdf文件,逐页转为图片,保存为多个临时文件。
- 读取临时图片文件,拼接输出一张图片文件。
- 对长图中过多的空白行进行删除。
不足
- word文件转pdf目前用的是win32com库,只能在windows系统使用。
- 空白行的判断效率较低。
实现
1. word转pdf
# -*- coding:utf-8 -*-
"""
将word文档转换为pdf文件
"""
from datetime import datetime
from pathlib import Path
import win32com.client# 将Word文档转换为PDF文件
def convert_to_pdf(input_file_path, output_file_path):# 目标文件若已存在,则先删除Path(output_file_path).unlink(True)word = client.DispatchEx('Word.Application')try:doc = word.Documents.Open(input_file_path)doc.SaveAs2(output_file_path, FileFormat=17)doc.Close()except Exception as e:print("转pdf失败:%s" % e)finally:word.Quit()def word_2_pdf(word_name, new_pdf_name):word_path = Path(word_name).parentconvert_to_pdf(word_name, new_pdf_name)return new_pdf_nameif __name__ == "__main__":word_name = "d:/test_word.docx"word_2_pdf(word_name)
2. pdf转图片
# -*- coding:utf-8 -*-from datetime import datetime
from pathlib import Path
# 安装fitz 就是安装 PyMuPDF 才能使用
import fitz
# import os
# 安装 opencv, opencv的像素含义顺序是 BGR (不是常用的RGB)
# pip3 install opencv-python -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import cv2
import numpy as np
from shutil import copyfiledef pdf_2_png(pdf_name,png_name=None):print(pdf_name)pdf_path = Path(pdf_name).parentdoc = fitz.open(pdf_name)img_stack = Nonetemp = 0# 每页pdf生产一个临时图片for pg in range(doc.page_count):page = doc[pg]temp += 1rotate = int(0)# 每个尺寸的缩放系数为2,这将为我们生成分辨率提高四倍的图像。zoom_x = 2.0zoom_y = 2.0trans = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)pixmap = page.get_pixmap(matrix=trans, alpha=False)# 生成临时png文件路径pic_name = str(pdf_path.joinpath('_temp_{}.png'.format(temp)).absolute())pixmap.save(pic_name)# pm_img = cv2.imread(pic_name) # 此方式不支持中文目录,改用下方方法pm_img = cv2.imdecode(np.fromfile(pic_name, dtype=np.uint8), cv2.IMREAD_COLOR + cv2.IMREAD_IGNORE_ORIENTATION)pm_img = cv2.resize(pm_img, (1191, 1684))# 删除临时图片文件Path(pic_name).unlink(True)# 拼长图if img_stack is None:img_stack = np.vstack((pm_img,))else:img_stack = np.vstack((img_stack, pm_img))# 删除长图中的空白区域thin_img = shrink_img(img_stack, 100, 20)output_file = png_name if png_name is not None else str(pdf_path.joinpath(Path(pdf_name).stem + ".png").absolute())# cv2.imwrite(str(tmp_img_name.absolute()), thin_img) # 不支持中文目录# 采用下述方法保存到带中文的目录cv2.imencode('.png', thin_img)[1].tofile(output_file)def shrink_file(img_file,target_file):pm_img = cv2.imread(img_file)im = shrink_img(pm_img, 120, 20)cv2.imwrite(target_file, im)if __name__ == "__main__":pf = "d:/test_word.pdf"pdf_2_png(pf)
3. 图片空白行删除
def is_blank(line):"""判断本行是否空白行"""for pixel in line:if not all(n == 255 for n in pixel):return Falsereturn Truedef get_blank_block(img, begin_row, end_row, need_height):"""获取高度大于等于输入值的整块空白区域"""if (img is None) or (begin_row < 0) or (end_row < begin_row) or (need_height <= 0):return False, 0, 0if (end_row - begin_row) < need_height:return False, 0, 0start_row = -1found = Falsefound_height = 0for row in range(begin_row, end_row):line = img[row, :]if not is_blank(line):# 非空白,则判断高度是否符合if found_height >= need_height:breakstart_row = -1found_height = 0continue# 是空白行if start_row < 0:start_row = rowfound_height += 1if found_height >= need_height:found = Truereturn found, start_row, found_heightdef shrink_img(img, blank_height=50, reserve_height=20):"""将图片中过长的空白背景截取删除:对于图片中整行都是白色,且超过一定高度的,仅保留指定高度区域,其余删除。"""# 读取原始图片宽高height, width = img.shape[:2]found = Trueimg_stack = Nonebegin_row = 0while found:found, begin_blank_row, found_height = get_blank_block(img, begin_row, height, blank_height)if found:# 找到空白区域,将搜索起始行到空白起始行之间的图像加入stack,跳过空白区域,继续搜索img2 = img[begin_row: begin_blank_row + reserve_height, :]begin_row = begin_blank_row + found_heightelse:# 没找到空白区域,将搜索起始行到结束行的图像加入stackimg2 = img[begin_row:height, :]if img_stack is None:img_stack = np.vstack((img2,))else:img_stack = np.vstack((img_stack, img2))if img_stack is None:img_stack = imgreturn img_stackif __name__ == "__main__":img_info = cv2.imread("d:/test.png")thin_img = shrink_img(img_info, 60, 20)cv2.imshow('result', thin_img)cv2.waitKey(0)cv2.destroyAllWindows()
效果
-
word原始文件,多页。
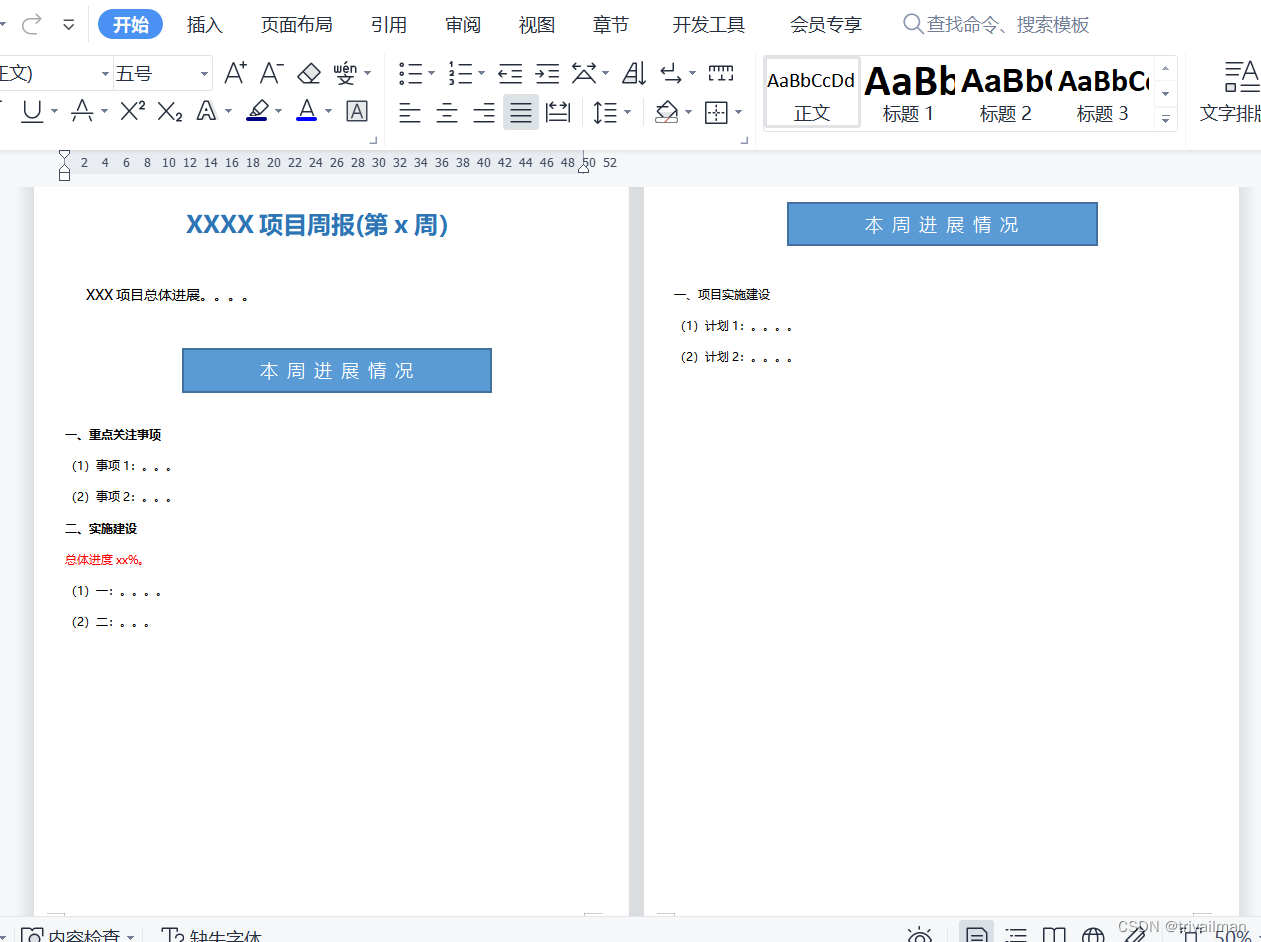
-
拼接后的长图(分页之间存在空白)

这篇关于Python实现word或pdf文件转png长图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



