本文主要是介绍我狂揽16个offer:面试常问的这些问题你准备了吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、前言
近期有小伙伴跟我反馈 ,面试有遇到面试官问 python 内存管理机制相关的问题,因为之前没有特地的去了解过,所以不知道怎么回答。
所以今天就专门写了这篇 python 内存管理机制的文章,来给大家系统的梳理一下内存管理机制的知识点,以及面试中容易被问到的问题。
通过这篇文章帮你们轻松通关面试中 python 内存管理机制相关的问题。
02、引用计数机制
引用计算机制是咱们 python 中垃圾回收的主要机制,python 解释器会根据对象的引用计数是否为零,来对进行垃圾回收,释放内存。接下来我们先来看看什么是引用计数。
我们先来看一个最简单的 python 赋值语句
>>> a = 10如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的自动化测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)_哔哩哔哩_bilibili【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)共计200条视频,包括:1、接口自动化之为什么要做接口自动化、2、接口自动化之request全局观、3、接口自动化之接口实战等,UP主更多精彩视频,请关注UP账号。![]() https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337
这边给变量 a 赋值了一个数值类型的对象 10, 那么在内存中存储的时候,a 这个变量指向的是 10 这个对象,此时 10 这个对象的引用计算会加 1。
>>> b=a当我们再把 a 赋值给变量 b 时,b 引用的也是 a 这个变量引用的值 10,那么这个时候 10 这个对象的引用计数又会加 1。
引用计数增加:
● 对象被创建
● 对象被别的变量引用(赋值给一个变量)
● 对象被作为元素,放在容器中(比如被当作元素放在列表中)
引用计数减少:
● 对象的别名被显式的销毁
● 对象的一个别名被赋值给其他对象 (例:比如原来的 a=10,被改成 a=100,那么此时 10 的引用计数就减少了)
● 对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
● 一个引用离开了它的作用域(调用函数的时候传进去的参数,在函数运行结束后,该参数的引用即被销毁)
引用计数查看
咱们如果要查看对象的引用计数,可以通过内置模块 sys 提供的 getrefcount 方法去查看。
import sys
obj =[11,22,33]
print(sys.getrefcount(obj))注意点:当使用某个引用作为参数,传递给 getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多 1 ;对应一些常用的基本数据看到的引用计数值会比较大(因为 python 内部引用)
03.数据池和缓存
1、小整数池
a=1000
a1=1000
b = 10
b1 = 10
# a和a1是否为同一个对象?,b和b1是否为同一个对象?问题:a 和 a1 是否为同一个对象?,b 和 b1 是否为同一个对象?
答案: b 和 b1 是同一个对象,a 和 a1 不是
为什么会出现上述情况呢?
当运行 python 程序时,Python 自动将-5~256 的整数进行了缓存,放在一个‘池’(小整数池)中,无论程序中那些变量指向这些范围内的整数或者字符串当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
优点:对于一些常用的整数,直接从‘池’里拿来用,避免频繁的创建和销毁,提升效率,节约内存
2、intern 机制
intern 机制,也称为字符串驻留池,是针对于字符串内存管理的一种优化处理的机制。
In [4]: s1='abc'
In [5]: s2 ='abc'
In [6]: s2 is s2
Out[6]: TrueIn [7]: s3='abc?'
In [8]: s4 = 'abc?'
In [9]: s3 is s4
Out[9]: False
#为什么会出现这种情况,同样是字符串为什么上面两次赋值,是同一个对象,下面不是。intern 机制的优点是,在创建新的字符串对象时(如果字符串只包含数字、字母、下划线),会先在字符串驻留池里面找是否有已经存在的值相同的对象,如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率。
3、缓存机制

● float、int 、list 等一些内置的数据类型,会缓存 80 个对象
● 元组 会根据元组数据的长度,分别缓存元组长度为 0-20 的对象。
● 其他的自定义类型一般都是缓存 2 个对象
04、垃圾回收机制
● python 的垃圾回收机制用一句话来形容就是:引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
引用计数
● 引用计数:在之前讲对象的引用我们讲到了,每个对象创建之后都有一个引用计数,当引用计数为 0 的时候,那么此时的的垃圾回收机制会自动把它销毁,回收内存空间。
● 引用计数存在一个缺点:那就是当两个对象出现循环引用的时候,那么这个两个变量始终不会被销毁,这样就会导致内存泄漏。
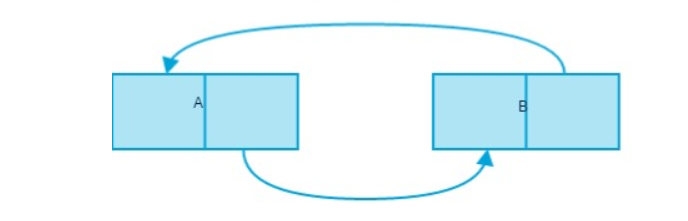
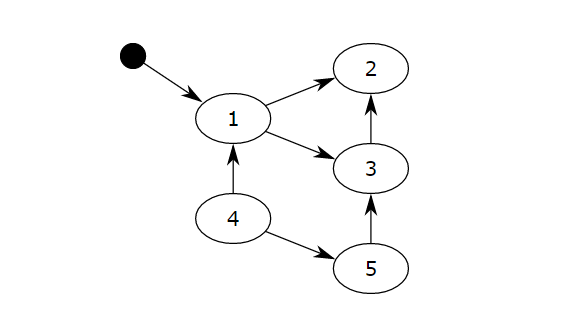
标记清除:
首先标记对象(垃圾检测),然后清除垃圾(垃圾回收),首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效),将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象。
分代回收
分代回收是一种以空间换时间的操作方式,Python 将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python 将内存分为了 3“代”,分别为年轻代(第 0 代)、中年代(第 1 代)、老年代(第 2 代),他们对应的是 3 个链表,它们的垃圾收集频率随着对象存活时间的增大而减小。

这篇关于我狂揽16个offer:面试常问的这些问题你准备了吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




