本文主要是介绍07-Cadence17.4 allegro的artwork设定(输出gerber文件需要),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Cadence17.4 allegro的artwork设定
这里写目录标题
- Cadence17.4 allegro的artwork设定
- 1.artwork设置与选择
- 2.注意
1.artwork设置与选择
打开artwork设置选项
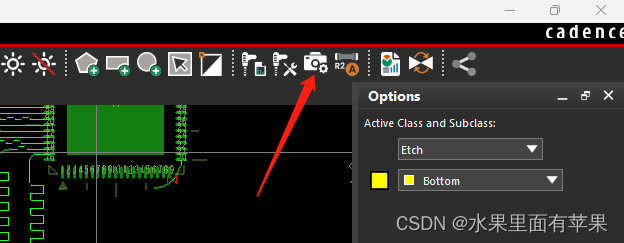
此时软件会弹出“Arwtrok Control Form”对话框,如下,我这里是四层板的设计。

000层:我在画图时有个习惯就是多增加一个000层,目前是在layout时可以一键切换到想要的视图模式,但是在出gerber文件的时候不要勾选此选项就好。
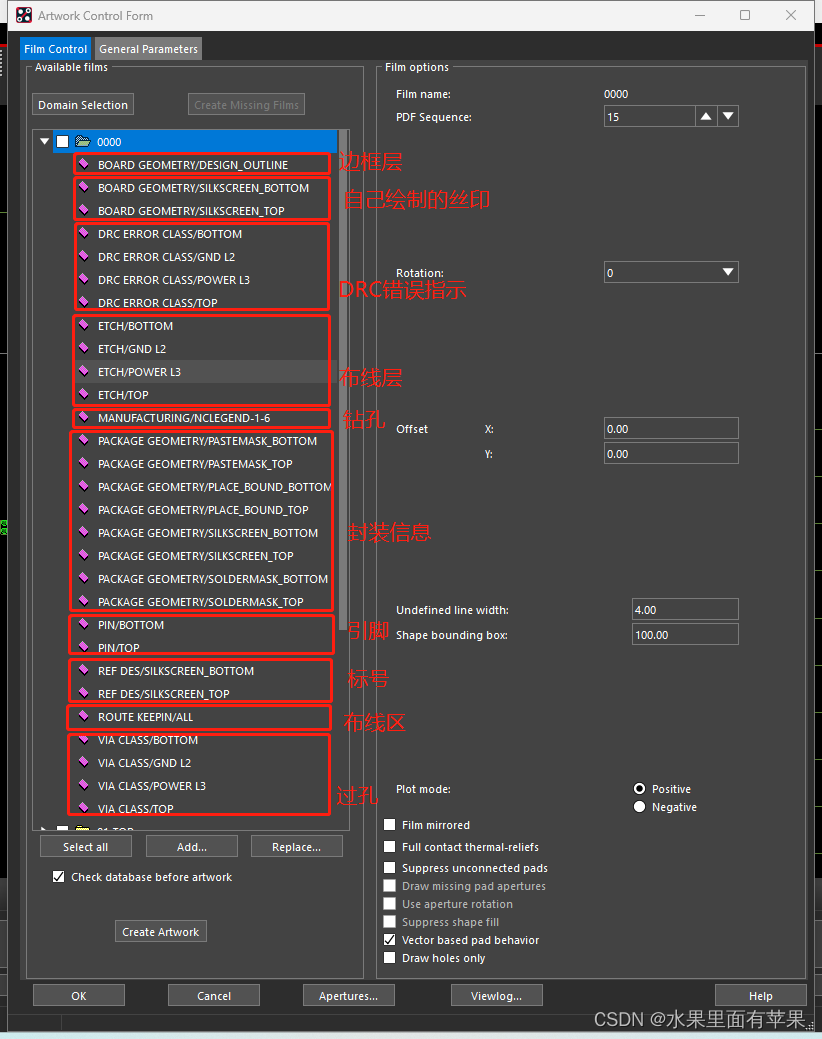
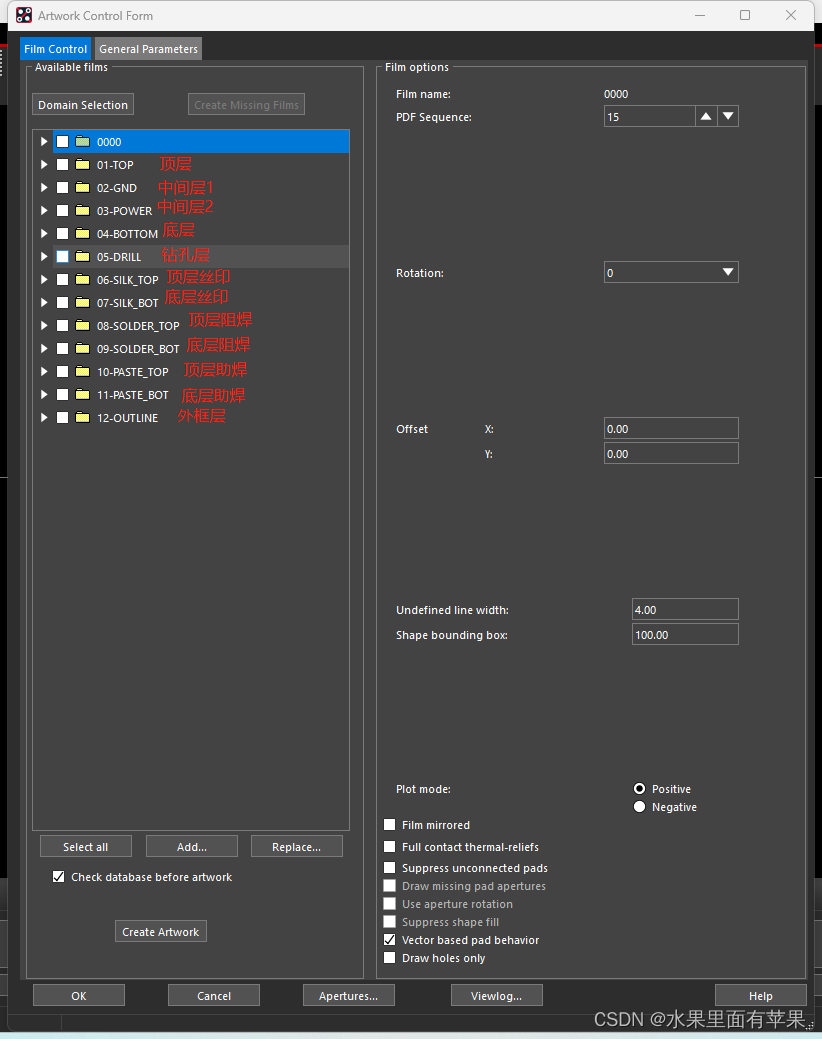
TOP层:包括布线,引脚,过孔

GND层:包括布线,过孔

POWER层:包括布线,过孔

BOTTOM层:包括布线,引脚,过孔

DRILL:包括钻孔图和孔标号

SILK-TOP/SILK-BOT:顶层和底层的丝印
SOLDER-TOP/SOLDER-BOT:顶层和底层的阻焊层

PASTE-TOP/PASTE-BOT:顶层和底层的阻焊层

OUTLINE:边框层

2.注意
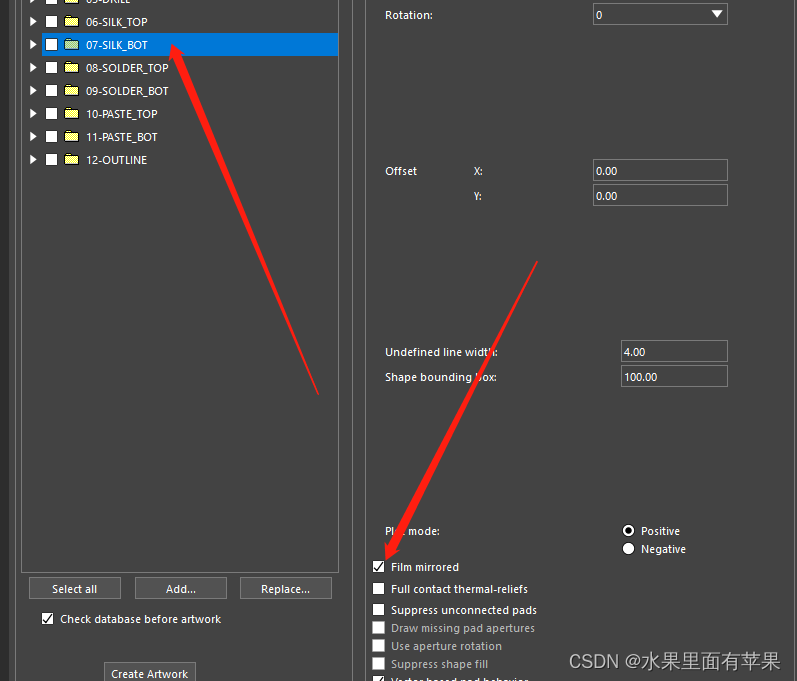
箭头所指的位置需要填写,否则gerber文件的丝印没有宽度。

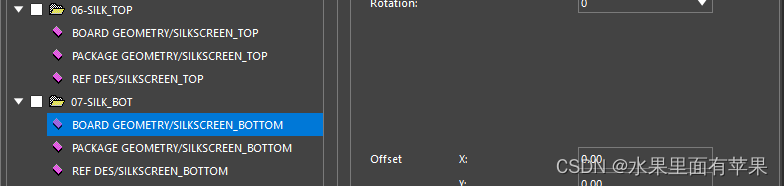
当你在输出bottom层的丝印时,请注意将下图的√打上,否则时镜像的文件,在输出gerber文件时记得取消
这篇关于07-Cadence17.4 allegro的artwork设定(输出gerber文件需要)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![业务中14个需要进行A/B测试的时刻[信息图]](https://img-blog.csdnimg.cn/img_convert/aeacc959fb75322bef30fd1a9e2e80b0.jpeg)