本文主要是介绍Hadoop问题系列<一>:ERROR: MaxTemperature is not COMMAND nor fully qualified CLASSNAME,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hadoop权威指南示例项目3-2,然后拿到服务器运行
然后报错: FileSystemCat is not COMMAND nor fully qualified CLASSNAME。`
(前提是已经安装好了hadoop)
看到hadoop FileSystemCat hdfs://localhost/user/tom/quangle.txt就有点懵!!!
以下是执行顺序:
export HADOOP_CLASSPATH=“你jar包放的路径”;

然后就是执行:

jar的方式也行:

你的类最好是放在包下面,我测试的时候,直接放java下面,也会报
ERROR: FileSystemCat is not COMMAND nor fully qualified CLASSNAME.:
我竟然每次在执行Jar命令的时候,都会clean,这个习惯“真好”,导致我的jar包中没有class文件。(我真优秀啊!!!)
如果按照上面的步骤执行还出错,请解压一下你的jar包检查是否有问题。
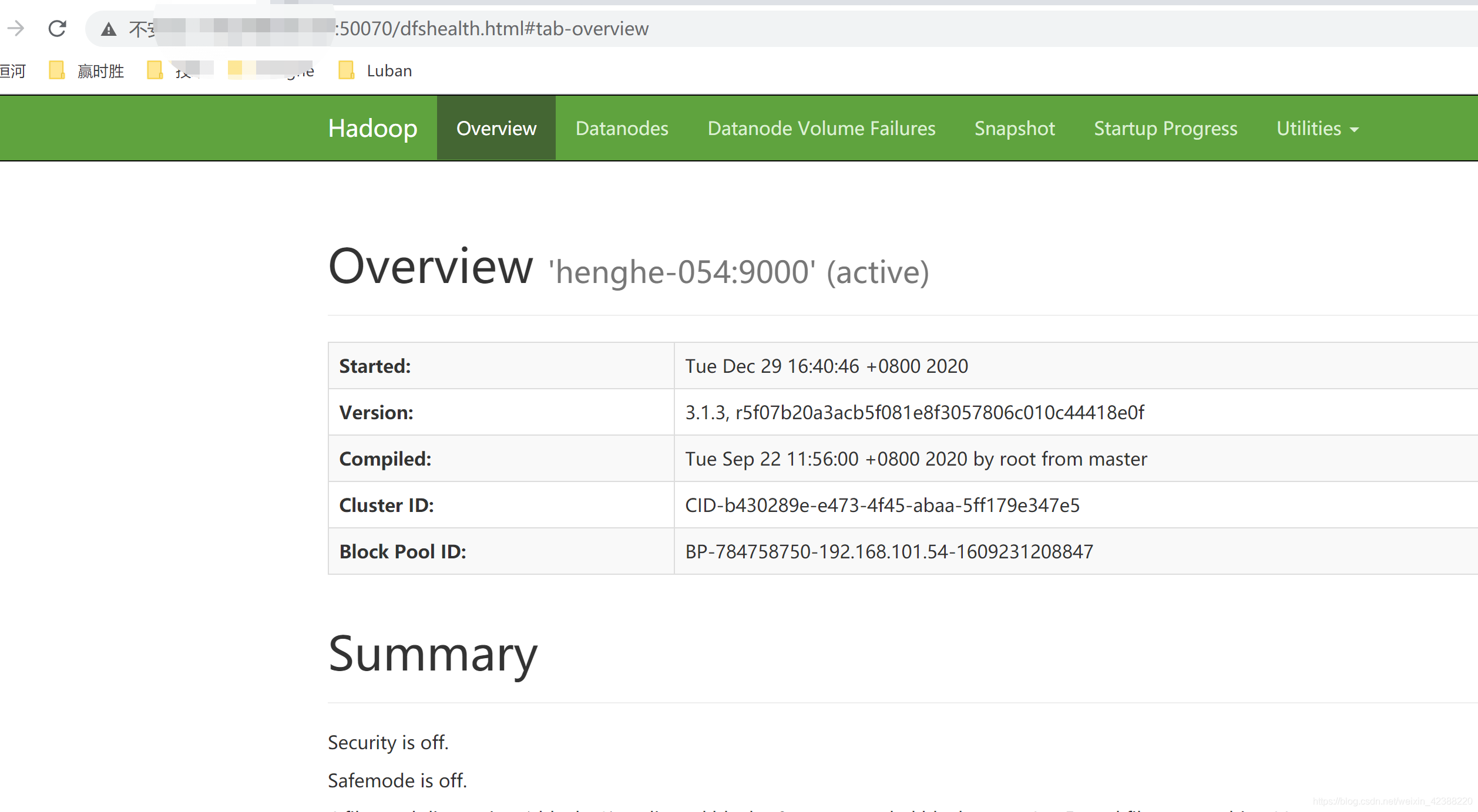
问题2:hadoop启动8088,但是启动不了hdfs 50070
我在启动hdfs的时候,发现可以启动8088,但是启动不了50070,遇到这种情况:
1.查看防火墙,防火墙关闭情况下 执行2
2.netstat -ant,我发现我没有50070端口,
3.直接hadoop namenode -format重启集群。 但在进行这个命令之前,一定要清空logs文件夹和tmp文件夹
要不然执行了也无效!!!
奈斯先生嘲笑我是个“人才”,毕竟我直接在服务器上去运行了Java文件,哈哈哈哈哈(优秀!!!)

这篇关于Hadoop问题系列<一>:ERROR: MaxTemperature is not COMMAND nor fully qualified CLASSNAME的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






