本文主要是介绍Linux之iostat溯源diskstats,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
iostat
- 默认输出解析
- 详细输出解析
- 关键指标
- diskstats
- 字段解析
- await的计算来源
- 计算方法
- svctm计算来源
- 计算方法
- util的计算来源
- 计算方法
系统级别的IO工具
默认输出解析
iostat
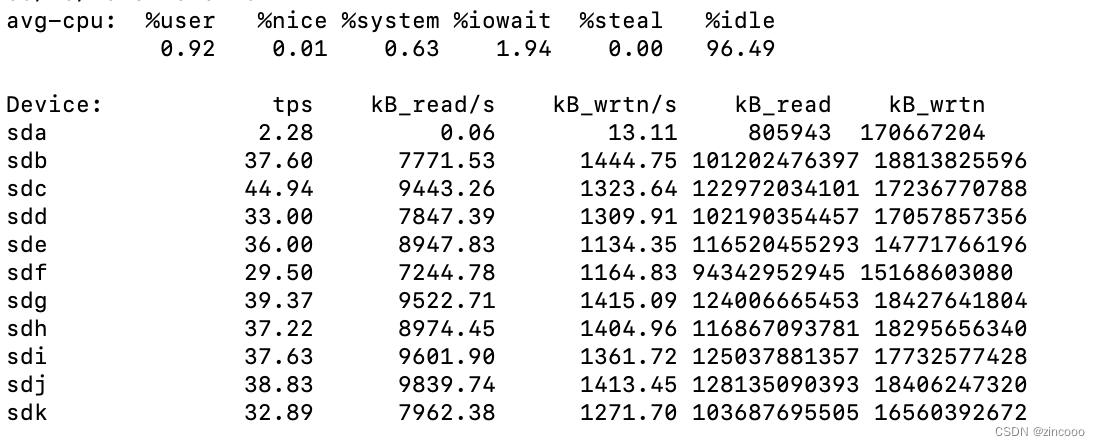
- %usr CPU在用户模式下的时间百分比
- %nice CPU处在带NICE值的用户模式下的时间百分比
- %system CPU在系统模式下的时间百分比
- %iowait CPU等待输入输出完成时间的百分比
- %steal 管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
- %idle CPU空闲时间百分比
- tps 该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输"意思是"一次I/O请求”。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
- kB_read/s 每秒从设备读取的数据量
- kB_wrtn/s 每秒向设备写入的数据量
- kB_read 读取的总数据量
- kB_wrtn 写入的总数据量
详细输出解析
iostat -x
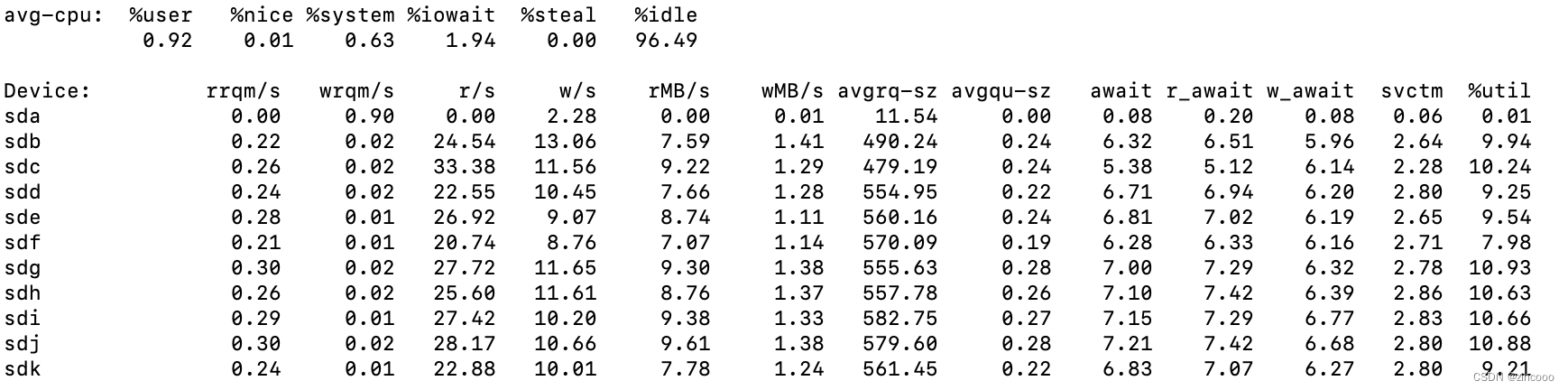
- rrqm/s : 每秒合并读操作的次数
- wrqm/s: 每秒合并写操作的次数
- r/s :每秒读操作的次数
- w/s : 每秒写操作的次数
- rMB/s :每秒读取的MB字节数
- wMB/s: 每秒写入的MB字节数
- avgrq-sz:每个IO的平均扇区数,即所有请求的平均大小,以扇区(512字节)为单位
- avgqu-sz:平均为完成的IO请求数量,即平均意义上的请求队列长度
- await:平均每个IO所需要的时间,包括在队列等待的时间,也包括磁盘控制器处理本次请求的有效时间。
1. r_wait:每个读操作平均所需要的时间,不仅包括硬盘设备读操作的时间,也包括在内核队列中的时间。
2. w_wait: 每个写操平均所需要的时间,不仅包括硬盘设备写操作的时间,也包括在队列中等待的时间。 - svctm: 表面看是每个IO请求的服务时间,不包括等待时间,但是实际上,这个指标已经废弃,iostat工具没有任何一输出项表示的是硬盘设备平均每次IO的时间。
- %util: 工作时间或者繁忙时间占总时间的百分比
关键指标
- avgqu-sz
队列的长度,在一定程度上反应了繁忙程度 - avgrq-sz
它的含义是说,平均下来一段时间内,所有请求的平均大小,单位是扇区,即(512字节)。avgrq-sz这个值反应了用户的IO-Pattern,反应过来的IO是大IO还是小IO,那么avgrq-sz反应了这个要素。
假设avgrq-sz为8,即8个扇区 = 8*512(Byte) = 4KB,则可以反应IO大小
但是总的大小受内核参数控制cat /sys/block/sdc/queue/max_sectors_kb - r/s和w/s
反应iops=r/s+w/s
diskstats
iostat的数据来源于内核提供的==/proc/diskstats==文件,该文件里面记录了系统中累计读写访问总数、IO访问总耗时等参数(也会在文件 /sys/block/<disk_name>/stat 中记录单个磁盘的统计信息)。
字段解析

每一列的含义如下:
- major:主设备号 — 不同类别设备编号不一样,虚拟磁盘统一为253,磁盘统一为8,环回设备统一为7
- minor:次设备号
- dev_name:磁盘名
- rd_ios:读完成总次数 — 不包含5列中的合并读取次数
- rd_merges:读取合并次数 — 如果两个读操作读取相邻的数据块时,可以被合并成一个,以提高效率。
- rd_sectors:读取的扇区总数 — 单个扇区 512B
- rd_ticks:读请求的总耗时 (ms) — 每个读操作从__make_request()开始计时,到end_that_request_last()为止,包括了在队列中等待的时间。
- wr_ios:写完成总次数
- wr_merges:写合并次数
- wr_sectors:写的扇区总数
- wr_ticks:写请求总耗时 (ms) — 包含在队列中等待时间
- in_flight:当前未完成的I/O数量。在I/O请求进入队列时该值加1,在I/O结束时该值减1。
注意:是I/O请求进入 plug 队列时,而不是提交给硬盘设备时。流程为 I/o-> plug -> elevator -> driver - io_ticks(tot_ticks):该设备用于处理I/O的自然时间。
请注意io_ticks与rd_ticks(字段7)和wr_ticks(字段11)的区别,rd_ticks和wr_ticks是把每一个I/O所消耗的时间累加在一起。而io_ticks表示该设备有I/O(即非空闲)的时间,不考虑I/O有多少,只考虑当前有没有I/O。因为硬盘设备通常可以并行处理多个I/O,所以rd_ticks和wr_ticks往往会比自然时间大。在实际计算时,字段12(in_flight)不为零的时候io_ticks保持计时,字段12(in_flight)为零的时候io_ticks停止计时。 - time_in_queue: 对字段13(io_ticks)的加权值(ms)。
字段13(io_ticks)是自然时间,但不考虑当前有几个I/O正在被处理,而time_in_queue是用当前的I/O数量(即字段12 in-flight)乘以自然时间(比如时间点1有一个I/O,时间点2有两个I/O, 那么 io_ticks = 1 + 1,而 time_in_queue=1+2,因为时间点2有两个 I/O)。虽然该字段的名称是time_in_queue,但并不真的只是在队列中的时间,其中还包含了硬盘处理I/O的时间。iostat在计算avgqu-sz时会用到这个字段。
通过上面的这些统计信息,我们可以大致计算出磁盘的单次 I/O 耗时,但是由于 /proc/diskstats 中没统计在磁盘上的实际耗时,所以我们无法计算出 I/O 在磁盘上的准确处理时间
await的计算来源
单次I/O的平均耗时(ms),包含在队列中的耗时和磁盘处理耗时
计算方法
间隔时间内 读写请求总耗时/读写总次数
#new 指这次获取 /proc/diskstats 的值, old 指上次获取 /proc/diskstats 的值
await =((new.rd_ticks - old.rd_ticks) + (new.wr_ticks - old.wr_ticks)) / (new.rd_ios + new.wr_ios - old.rd_ios-old.wr
svctm计算来源
单次I/O的服务时间(ms), 不包括等待时间
计算方法
间隔时间内 所有的io服务时间/io请求次数
svc_t=(new.io_ticks-old.io_ticks)/(new.rd_ios + new.wr_ios - old.rd_ios-old.wr_ios)
注意
- svctm 是根据一段时间内有IO访问的时间累加和除以这段时间内的IO访问次数。但是这个结果并不能简单地表示单次 I/O 时间, 比如当磁盘能并行处理请求时, 10个请求从开始处理到处理结束花费时间为10ms, 那么 io_ticks 统计的耗时是 10ms, 根据上面公式来算,单次 I/O 耗时为1ms,实际上每个请求可能都花费了10ms。
但是对于 sata hdd 盘我们可以用 svctm 来简单地表示单次磁盘耗时, 对于nvme 我们不能用 svctm 表示单次 I/O 耗时。
util的计算来源
磁盘使用时间百分比
计算方法
#itv 表示两次统计之间的时间间隔
util = (new.tot_ticks - old.tot_ticks)/ itv
注意
如果磁盘可以并行,那么虽然 util显示达到100%, 磁盘吞吐可能还未达到上限。
这篇关于Linux之iostat溯源diskstats的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





